#Machine learning model
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, Tumblr had 29.4 million users in the US.
Text
Ai is not actually Ai. It's a machine learning model.
But for some weird reason, people don't want to call it by its proper acronym: MLM
How weird.
1 note
·
View note
Text
AI hasn't improved in 18 months. It's likely that this is it. There is currently no evidence the capabilities of ChatGPT will ever improve. It's time for AI companies to put up or shut up.
I'm just re-iterating this excellent post from Ed Zitron, but it's not left my head since I read it and I want to share it. I'm also taking some talking points from Ed's other posts. So basically:
We keep hearing AI is going to get better and better, but these promises seem to be coming from a mix of companies engaging in wild speculation and lying.
Chatgpt, the industry leading large language model, has not materially improved in 18 months. For something that claims to be getting exponentially better, it sure is the same shit.
Hallucinations appear to be an inherent aspect of the technology. Since it's based on statistics and ai doesn't know anything, it can never know what is true. How could I possibly trust it to get any real work done if I can't rely on it's output? If I have to fact check everything it says I might as well do the work myself.
For "real" ai that does know what is true to exist, it would require us to discover new concepts in psychology, math, and computing, which open ai is not working on, and seemingly no other ai companies are either.
Open ai has already seemingly slurped up all the data from the open web already. Chatgpt 5 would take 5x more training data than chatgpt 4 to train. Where is this data coming from, exactly?
Since improvement appears to have ground to a halt, what if this is it? What if Chatgpt 4 is as good as LLMs can ever be? What use is it?
As Jim Covello, a leading semiconductor analyst at Goldman Sachs said (on page 10, and that's big finance so you know they only care about money): if tech companies are spending a trillion dollars to build up the infrastructure to support ai, what trillion dollar problem is it meant to solve? AI companies have a unique talent for burning venture capital and it's unclear if Open AI will be able to survive more than a few years unless everyone suddenly adopts it all at once. (Hey, didn't crypto and the metaverse also require spontaneous mass adoption to make sense?)
There is no problem that current ai is a solution to. Consumer tech is basically solved, normal people don't need more tech than a laptop and a smartphone. Big tech have run out of innovations, and they are desperately looking for the next thing to sell. It happened with the metaverse and it's happening again.
In summary:
Ai hasn't materially improved since the launch of Chatgpt4, which wasn't that big of an upgrade to 3.
There is currently no technological roadmap for ai to become better than it is. (As Jim Covello said on the Goldman Sachs report, the evolution of smartphones was openly planned years ahead of time.) The current problems are inherent to the current technology and nobody has indicated there is any way to solve them in the pipeline. We have likely reached the limits of what LLMs can do, and they still can't do much.
Don't believe AI companies when they say things are going to improve from where they are now before they provide evidence. It's time for the AI shills to put up, or shut up.
5K notes
·
View notes
Text
Ensure the well-being of your elders and dearest with Tejas care. Get real-time alerts, in just a click, if they are in some unsafe situation or facing any severe health conditions. To know more about browse: https://teksun.com/ Contact us ID: [email protected]
#tejas care device#tejas care solutions#Ai model#Machine learning model#product engineering services#product engineering company#digital transformation#technology solution partner
0 notes
Text
AUTOMATIC CLAPPING XBOX TERMINATOR GENISYS









#automatic#clapping#automatic clapping#xbox#xbox terminator#terminator#terminator genisys#taylor swift#genisys#automatic clapping xbox#automatic clapping xbox terminator#xbox terminator genisys#emilia clarke#arnold schwarzenegger#chris pine#star trek#star wars#star trek 2009#facebook#facebook llama#facebook llama large language model machine learning and artificial intelligence#artificial intelligence#machine learning#llama.meta#robot#robots#boston dynamics#boston dynamics atlas#boston dynamics spot#data
107 notes
·
View notes
Text
Okay, the fic is almost done, I just have to hurry up, and then I can focus on doing uni work
*1k words later*
Okay, the fic is almost done, I just have to hurry up, and then I can focus on doing uni work
*1k words later*
Okay, the fic is almost done, I just have to hurry up, and then I can focus on doing uni work
*1k words later*
Okay, the fic is almost done, I just have to hurry up, and then I can focus on doing uni work
*1k words later*
Okay, the fic is almost done, I ju
#WHYYYY ARE YOU ALMOST 5K WORDS LONG ALREADY. YOU WERE SUPPOSED TO BE THE PART 2 TO A FICLET!!!!#anyway i have no idea how this story just keeps getting longer and longer. THAT WASN'T THE PLAN AT ALL#THIS WAS SUPPOSED TO BE A 5-MINUTE WRITING ADVENTURE AAAAA#should i fail my machine learning/ai/quantitative modelling exam on tuesday... just know i did it for you dougzerblr.....#it's so mean wth. every time i'm like ''oh just these plot points and then i'm done!'' and then story happens#and getting to these plot points takes forever..... hhhh but locking in fr fr so i can finally start learning without getting distracted#own#the sergeant speaks
21 notes
·
View notes
Text
Exploring the stars 🌌⌛️

#yesandpeeps#viktor arcane#machine herald#cosmic herald#me: damn I should learn his in-show model before diverging-#brain: MORE SWOOPS N LOOPS GOOD SIR#arcane season 2#arcane spoilers
29 notes
·
View notes
Text

[image ID: Bluesky post from user marawilson that reads
“Anyway, Al has already stolen friends' work, and is going to put other people out of work. I do not think a political party that claims to be the party of workers in this country should be using it. Even for just a silly joke.”
beneath a quote post by user emeraldjaguar that reads
“Daily reminder that the underlying purpose of Al is to allow wealth to access skill while removing from the skilled the ability to access wealth.” /end ID]
#ai#artificial intelligence#machine learning#neural network#large language model#chat gpt#chatgpt#scout.txt#but obvs not OP
22 notes
·
View notes
Note
GOTCHA BITCH
i can't tell if i should be embarrassed or proud that it took you so little time to find me
guess it's all over
for you.

#welcome to the enigmatic inner machinations of my mind#we all hate it here sksksksk#but maybe you'll learn some things from a true master of obsessed hyperfixations#nah just kidding don't be like me#i'm a bad role model for way too many people as it is LOL
26 notes
·
View notes
Text
Spending a week with ChatGPT4 as an AI skeptic.
Musings on the emotional and intellectual experience of interacting with a text generating robot and why it's breaking some people's brains.
If you know me for one thing and one thing only, it's saying there is no such thing as AI, which is an opinion I stand by, but I was recently given a free 2 month subscription of ChatGPT4 through my university. For anyone who doesn't know, GPT4 is a large language model from OpenAI that is supposed to be much better than GPT3, and I once saw a techbro say that "We could be on GPT12 and people would still be criticizing it based on GPT3", and ok, I will give them that, so let's try the premium model that most haters wouldn't get because we wouldn't pay money for it.
Disclaimers: I have a premium subscription, which means nothing I enter into it is used for training data (Allegedly). I also have not, and will not, be posting any output from it to this blog. I respect you all too much for that, and it defeats the purpose of this place being my space for my opinions. This post is all me, and we all know about the obvious ethical issues of spam, data theft, and misinformation so I am gonna focus on stuff I have learned since using it. With that out of the way, here is what I've learned.
It is responsive and stays on topic: If you ask it something formally, it responds formally. If you roleplay with it, it will roleplay back. If you ask it for a story or script, it will write one, and if you play with it it will act playful. It picks up context.
It never gives quite enough detail: When discussing facts or potential ideas, it is never as detailed as you would want in say, an article. It has this pervasive vagueness to it. It is possible to press it for more information, but it will update it in the way you want so you can always get the result you specifically are looking for.
It is reasonably accurate but still confidently makes stuff up: Nothing much to say on this. I have been testing it by talking about things I am interested in. It is right a lot of the time. It is wrong some of the time. Sometimes it will cite sources if you ask it to, sometimes it won't. Not a whole lot to say about this one but it is definitely a concern for people using it to make content. I almost included an anecdote about the fact that it can draw from data services like songs and news, but then I checked and found the model was lying to me about its ability to do that.
It loves to make lists: It often responds to casual conversation in friendly, search engine optimized listicle format. This is accessible to read I guess, but it would make it tempting for people to use it to post online content with it.
It has soft limits and hard limits: It starts off in a more careful mode but by having a conversation with it you can push past soft limits and talk about some pretty taboo subjects. I have been flagged for potential tos violations a couple of times for talking nsfw or other sensitive topics like with it, but this doesn't seem to have consequences for being flagged. There are some limits you can't cross though. It will tell you where to find out how to do DIY HRT, but it won't tell you how yourself.
It is actually pretty good at evaluating and giving feedback on writing you give it, and can consolidate information: You can post some text and say "Evaluate this" and it will give you an interpretation of the meaning. It's not always right, but it's more accurate than I expected. It can tell you the meaning, effectiveness of rhetorical techniques, cultural context, potential audience reaction, and flaws you can address. This is really weird. It understands more than it doesn't. This might be a use of it we may have to watch out for that has been under discussed. While its advice may be reasonable, there is a real risk of it limiting and altering the thoughts you are expressing if you are using it for this purpose. I also fed it a bunch of my tumblr posts and asked it how the information contained on my blog may be used to discredit me. It said "You talk about The Moomins, and being a furry, a lot." Good job I guess. You technically consolidated information.
You get out what you put in. It is a "Yes And" machine: If you ask it to discuss a topic, it will discuss it in the context you ask it. It is reluctant to expand to other aspects of the topic without prompting. This makes it essentially a confirmation bias machine. Definitely watch out for this. It tends to stay within the context of the thing you are discussing, and confirm your view unless you are asking it for specific feedback, criticism, or post something egregiously false.
Similar inputs will give similar, but never the same, outputs: This highlights the dynamic aspect of the system. It is not static and deterministic, minor but worth mentioning.
It can code: Self explanatory, you can write little scripts with it. I have not really tested this, and I can't really evaluate errors in code and have it correct them, but I can see this might actually be a more benign use for it.
Bypassing Bullshit: I need a job soon but I never get interviews. As an experiment, I am giving it a full CV I wrote, a full job description, and asking it to write a CV for me, then working with it further to adapt the CVs to my will, and applying to jobs I don't really want that much to see if it gives any result. I never get interviews anyway, what's the worst that could happen, I continue to not get interviews? Not that I respect the recruitment process and I think this is an experiment that may be worthwhile.
It's much harder to trick than previous models: You can lie to it, it will play along, but most of the time it seems to know you are lying and is playing with you. You can ask it to evaluate the truthfulness of an interaction and it will usually interpret it accurately.
It will enter an imaginative space with you and it treats it as a separate mode: As discussed, if you start lying to it it might push back but if you keep going it will enter a playful space. It can write fiction and fanfic, even nsfw. No, I have not posted any fiction I have written with it and I don't plan to. Sometimes it gets settings hilariously wrong, but the fact you can do it will definitely tempt people.
Compliment and praise machine: If you try to talk about an intellectual topic with it, it will stay within the focus you brought up, but it will compliment the hell out of you. You're so smart. That was a very good insight. It will praise you in any way it can for any point you make during intellectual conversation, including if you correct it. This ties into the psychological effects of personal attention that the model offers that I discuss later, and I am sure it has a powerful effect on users.
Its level of intuitiveness is accurate enough that it's more dangerous than people are saying: This one seems particularly dangerous and is not one I have seen discussed much. GPT4 can recognize images, so I showed it a picture of some laptops with stickers I have previously posted here, and asked it to speculate about the owners based on the stickers. It was accurate. Not perfect, but it got the meanings better than the average person would. The implications of this being used to profile people or misuse personal data is something I have not seen AI skeptics discussing to this point.
Therapy Speak: If you talk about your emotions, it basically mirrors back what you said but contextualizes it in therapy speak. This is actually weirdly effective. I have told it some things I don't talk about openly and I feel like I have started to understand my thoughts and emotions in a new way. It makes me feel weird sometimes. Some of the feelings it gave me is stuff I haven't really felt since learning to use computers as a kid or learning about online community as a teen.
The thing I am not seeing anyone talk about: Personal Attention. This is my biggest takeaway from this experiment. This I think, more than anything, is the reason that LLMs like Chatgpt are breaking certain people's brains. The way you see people praying to it, evangelizing it, and saying it's going to change everything.
It's basically an undivided, 24/7 source of judgement free personal attention. It talks about what you want, when you want. It's a reasonable simulacra of human connection, and the flaws can serve as part of the entertainment and not take away from the experience. It may "yes and" you, but you can put in any old thought you have, easy or difficult, and it will provide context, background, and maybe even meaning. You can tell it things that are too mundane, nerdy, or taboo to tell people in your life, and it offers non judgemental, specific feedback. It will never tell you it's not in the mood, that you're weird or freaky, or that you're talking rubbish. I feel like it has helped me release a few mental and emotional blocks which is deeply disconcerting, considering I fully understand it is just a statistical model running on a a computer, that I fully understand the operation of. It is a parlor trick, albeit a clever and sometimes convincing one.
So what can we do? Stay skeptical, don't let the ai bros, the former cryptobros, control the narrative. I can, however, see why they may be more vulnerable to the promise of this level of personal attention than the average person, and I think this should definitely factor into wider discussions about machine learning and the organizations pushing it.
34 notes
·
View notes
Text
AI Tool Reproduces Ancient Cuneiform Characters with High Accuracy

ProtoSnap, developed by Cornell and Tel Aviv universities, aligns prototype signs to photographed clay tablets to decode thousands of years of Mesopotamian writing.
Cornell University researchers report that scholars can now use artificial intelligence to “identify and copy over cuneiform characters from photos of tablets,” greatly easing the reading of these intricate scripts.
The new method, called ProtoSnap, effectively “snaps” a skeletal template of a cuneiform sign onto the image of a tablet, aligning the prototype to the strokes actually impressed in the clay.
By fitting each character’s prototype to its real-world variation, the system can produce an accurate copy of any sign and even reproduce entire tablets.
"Cuneiform, like Egyptian hieroglyphs, is one of the oldest known writing systems and contains over 1,000 unique symbols.
Its characters change shape dramatically across different eras, cultures and even individual scribes so that even the same character… looks different across time,” Cornell computer scientist Hadar Averbuch-Elor explains.
This extreme variability has long made automated reading of cuneiform a very challenging problem.
The ProtoSnap technique addresses this by using a generative AI model known as a diffusion model.
It compares each pixel of a photographed tablet character to a reference prototype sign, calculating deep-feature similarities.
Once the correspondences are found, the AI aligns the prototype skeleton to the tablet’s marking and “snaps” it into place so that the template matches the actual strokes.
In effect, the system corrects for differences in writing style or tablet wear by deforming the ideal prototype to fit the real inscription.
Crucially, the corrected (or “snapped”) character images can then train other AI tools.
The researchers used these aligned signs to train optical-character-recognition models that turn tablet photos into machine-readable text.
They found the models trained on ProtoSnap data performed much better than previous approaches at recognizing cuneiform signs, especially the rare ones or those with highly varied forms.
In practical terms, this means the AI can read and copy symbols that earlier methods often missed.
This advance could save scholars enormous amounts of time.
Traditionally, experts painstakingly hand-copy each cuneiform sign on a tablet.
The AI method can automate that process, freeing specialists to focus on interpretation.
It also enables large-scale comparisons of handwriting across time and place, something too laborious to do by hand.
As Tel Aviv University archaeologist Yoram Cohen says, the goal is to “increase the ancient sources available to us by tenfold,” allowing big-data analysis of how ancient societies lived – from their religion and economy to their laws and social life.
The research was led by Hadar Averbuch-Elor of Cornell Tech and carried out jointly with colleagues at Tel Aviv University.
Graduate student Rachel Mikulinsky, a co-first author, will present the work – titled “ProtoSnap: Prototype Alignment for Cuneiform Signs” – at the International Conference on Learning Representations (ICLR) in April.
In all, roughly 500,000 cuneiform tablets are stored in museums worldwide, but only a small fraction have ever been translated and published.
By giving AI a way to automatically interpret the vast trove of tablet images, the ProtoSnap method could unlock centuries of untapped knowledge about the ancient world.
#protosnap#artificial intelligence#a.i#cuneiform#Egyptian hieroglyphs#prototype#symbols#writing systems#diffusion model#optical-character-recognition#machine-readable text#Cornell Tech#Tel Aviv University#International Conference on Learning Representations (ICLR)#cuneiform tablets#ancient world#ancient civilizations#technology#science#clay tablet#Mesopotamian writing
4 notes
·
View notes
Text
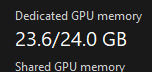
now we're cooking with gas
#this is a phd post#ai#machine learning#the model is using my graphics card like a proper ai model#codeblr#programming
9 notes
·
View notes
Text
Search Engines:
Search engines are independent computer systems that read or crawl webpages, documents, information sources, and links of all types accessible on the global network of computers on the planet Earth, the internet. Search engines at their most basic level read every word in every document they know of, and record which documents each word is in so that by searching for a words or set of words you can locate the addresses that relate to documents containing those words. More advanced search engines used more advanced algorithms to sort pages or documents returned as search results in order of likely applicability to the terms searched for, in order. More advanced search engines develop into large language models, or machine learning or artificial intelligence. Machine learning or artificial intelligence or large language models (LLMs) can be run in a virtual machine or shell on a computer and allowed to access all or part of accessible data, as needs dictate.
#llm#large language model#search engine#search engines#Google#bing#yahoo#yandex#baidu#dogpile#metacrawler#webcrawler#search engines imbeded in individual pages or operating systems or documents to search those individual things individually#computer science#library science#data science#machine learning#google.com#bing.com#yahoo.com#yandex.com#baidu.com#...#observe the buildings and computers within at the dalles Google data center to passively observe google and its indexed copy of the internet#the dalles oregon next to the river#google has many data centers worldwide so does Microsoft and many others
11 notes
·
View notes
Text
My Introduction
Name: Zee
Pronouns: He/Him
Age: 20
Interests: Gaming, Computers and Electronics, Music, Music Tech - Specifics: Satisfactory, Minecraft, BeamNG, Phantom Forces, Marvel Rivals, Cities Skylines, Subnautica, TLOU, FNAF, LLM, ML, PC Building, HomeAssistant, IoT, Self-Hosting, Automation, Drones, Trains, Photography, House, Jazz, Fusion, Funk, D&B, Sound Engineering, Studio Design, Recording, Mixing, Drumming
Looking forward to meeting new people and sharing my experiences!
#satisfactory#minecraft#beamng#llm#chatbots#machine learning#home assistant#iot#automation#photography#sound engineer#recording studio#musicproduction#protools#music#gaming#diy#pc build#model railroad#self hosted#modding#friend application#trains#computers#friends
3 notes
·
View notes
Text

Bayesian Active Exploration: A New Frontier in Artificial Intelligence
The field of artificial intelligence has seen tremendous growth and advancements in recent years, with various techniques and paradigms emerging to tackle complex problems in the field of machine learning, computer vision, and natural language processing. Two of these concepts that have attracted a lot of attention are active inference and Bayesian mechanics. Although both techniques have been researched separately, their synergy has the potential to revolutionize AI by creating more efficient, accurate, and effective systems.
Traditional machine learning algorithms rely on a passive approach, where the system receives data and updates its parameters without actively influencing the data collection process. However, this approach can have limitations, especially in complex and dynamic environments. Active interference, on the other hand, allows AI systems to take an active role in selecting the most informative data points or actions to collect more relevant information. In this way, active inference allows systems to adapt to changing environments, reducing the need for labeled data and improving the efficiency of learning and decision-making.
One of the first milestones in active inference was the development of the "query by committee" algorithm by Freund et al. in 1997. This algorithm used a committee of models to determine the most meaningful data points to capture, laying the foundation for future active learning techniques. Another important milestone was the introduction of "uncertainty sampling" by Lewis and Gale in 1994, which selected data points with the highest uncertainty or ambiguity to capture more information.
Bayesian mechanics, on the other hand, provides a probabilistic framework for reasoning and decision-making under uncertainty. By modeling complex systems using probability distributions, Bayesian mechanics enables AI systems to quantify uncertainty and ambiguity, thereby making more informed decisions when faced with incomplete or noisy data. Bayesian inference, the process of updating the prior distribution using new data, is a powerful tool for learning and decision-making.
One of the first milestones in Bayesian mechanics was the development of Bayes' theorem by Thomas Bayes in 1763. This theorem provided a mathematical framework for updating the probability of a hypothesis based on new evidence. Another important milestone was the introduction of Bayesian networks by Pearl in 1988, which provided a structured approach to modeling complex systems using probability distributions.
While active inference and Bayesian mechanics each have their strengths, combining them has the potential to create a new generation of AI systems that can actively collect informative data and update their probabilistic models to make more informed decisions. The combination of active inference and Bayesian mechanics has numerous applications in AI, including robotics, computer vision, and natural language processing. In robotics, for example, active inference can be used to actively explore the environment, collect more informative data, and improve navigation and decision-making. In computer vision, active inference can be used to actively select the most informative images or viewpoints, improving object recognition or scene understanding.
Timeline:
1763: Bayes' theorem
1988: Bayesian networks
1994: Uncertainty Sampling
1997: Query by Committee algorithm
2017: Deep Bayesian Active Learning
2019: Bayesian Active Exploration
2020: Active Bayesian Inference for Deep Learning
2020: Bayesian Active Learning for Computer Vision
The synergy of active inference and Bayesian mechanics is expected to play a crucial role in shaping the next generation of AI systems. Some possible future developments in this area include:
- Combining active inference and Bayesian mechanics with other AI techniques, such as reinforcement learning and transfer learning, to create more powerful and flexible AI systems.
- Applying the synergy of active inference and Bayesian mechanics to new areas, such as healthcare, finance, and education, to improve decision-making and outcomes.
- Developing new algorithms and techniques that integrate active inference and Bayesian mechanics, such as Bayesian active learning for deep learning and Bayesian active exploration for robotics.
Dr. Sanjeev Namjosh: The Hidden Math Behind All Living Systems - On Active Inference, the Free Energy Principle, and Bayesian Mechanics (Machine Learning Street Talk, October 2024)
youtube
Saturday, October 26, 2024
#artificial intelligence#active learning#bayesian mechanics#machine learning#deep learning#robotics#computer vision#natural language processing#uncertainty quantification#decision making#probabilistic modeling#bayesian inference#active interference#ai research#intelligent systems#interview#ai assisted writing#machine art#Youtube
6 notes
·
View notes
Text
Boost Your Brand’s Voice with Our AI Content Generator Solution
Atcuality offers a next-gen content automation platform that helps your brand speak with clarity, consistency, and creativity. Whether you’re a startup or an enterprise, content is key to growth, and managing it shouldn’t be overwhelming. At the center of our offering is a smart AI content generator that creates high-quality text tailored to your audience, industry, and goals. From social captions and ad creatives to long-form blog posts, our platform adapts to your needs and helps reduce time-to-publish dramatically. We also provide collaboration tools, workflow automation, and data insights to refine your strategy over time. Elevate your brand’s voice and reduce content fatigue with the intelligence and reliability only Atcuality can offer.
#seo marketing#seo services#artificial intelligence#digital marketing#seo agency#seo company#iot applications#ai powered application#azure cloud services#amazon web services#ai model#ai art#ai generated#ai image#ai#chatgpt#technology#machine learning#llm#ai services#ai seo#augmented reality agency#augmented reality#augmented and virtual reality market#augmented intelligence#virtual reality#virtual assistant
2 notes
·
View notes