#gradient graphs
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has a low social media market share in South America.
Text

code art variation - gradient graphs
A gabriel graph is a special category of graph in graph theory where an edge can only be formed between two nodes if the circle formed by those two nodes contains no other nodes in the graph. A random geometric graph is a graph where an edge can only be formed between two nodes if they are less than a certain distance away from each other.
“Gradient Graphs” is an original generative code art algorithm; each run of the code produces a random visual output. The “Gradient Graphs” program generates random gabriel graphs and random geometric graphs, where each graph has a random number of nodes and each node has a random position and color. Nodes are connected by lines and circles that have a gradient from one point color to the other.
Users can interact with the program to remove the nodes, edge lines, or edge circles, choosing how they would like the graph to be displayed.
“Gradient Graphs” was made with JavaScript and p5.js.
This code and its output are licensed under the Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International (CC BY-NC-ND 4.0) License.
Copyright (C) 2022-2024 brittni and the polar bear LLC. Some rights reserved.
#code art#algorithmic art#generative art#genart#creative coding#digital art#black art#artists on tumblr#graph theory#gradient graphs#made with javascript
5 notes
·
View notes
Text
You are still ace/aro if there are 1 or 2 people you have experienced sexual/romantic attraction to.
You are still ace/aro if there are 1 or 2 people who upon becoming close to, you develop sexual/romantic attraction to.
You are still ace/aro if you enjoy sex (have a sex drive) or enjoy the wrappings of romance (a date or companionship).
Micro labels under the Ace umbrella don’t exclude you from being Ace.
Im seeing a lot of well meaning but tone deaf posts on IG and TikTok about how Ace/Aro ness id the complete lack of either sexual or romantic expression. A lot of purity within the label bullshit that we don’t tolerate in lgbtqia spaces.
Sexual attraction and sex drive are two different things that can overlap but sometimes don’t. Straight, gay, bi, pan etc people can all have low sex drives and not be interested in sex but still experience attraction just as some aces can have a sex drive devoid of attraction. Straight gay bi pan etc people can have reasons for not wanting romantic relationships but still feel the attraction for it, just as an aro can be in a relationship for a multitude of reasons and participate in romantic activities.
Placing a purist threshold on Aces and Aros is the type of gatekeeping that will ultimately lose you friends and community.
It’s called a spectrum for a reason.
27 notes
·
View notes
Text
nothing this cad program is giving me makes sense but im eepy so fuck it aspect ratio of *checks notes* 2197.151055
#i have spent literal hours of my life yelling at this stupid CAD program but at least the colors are pretty 😌#me having a complete mental breakdown because the mesh isn't working and hasn't been for the past two hours:#the pretty lil geometric gradients on the stress and displacement graphs:
0 notes
Text
📝 Guest Post: Yandex develops and open-sources YaFSDP — a tool for faster LLM training and optimized GPU consumption*
New Post has been published on https://thedigitalinsider.com/guest-post-yandex-develops-and-open-sources-yafsdp-a-tool-for-faster-llm-training-and-optimized-gpu-consumption/
📝 Guest Post: Yandex develops and open-sources YaFSDP — a tool for faster LLM training and optimized GPU consumption*
A few weeks ago, Yandex open-sourced the YaFSDP method — a new tool that is designed to dramatically speed up the training of large language models. In this article, Mikhail Khrushchev, the leader of the YandexGPT pre-training team will talk about how you can organize LLM training on a cluster and what issues may arise. He’ll also look at alternative training methods like ZeRO and FSDP and explain how YaFSDP differs from them.
Problems with Training on Multiple GPUs
What are the challenges of distributed LLM training on a cluster with multiple GPUs? To answer this question, let’s first consider training on a single GPU:
We do a forward pass through the network for a new data batch and then calculate loss.
Then we run backpropagation.
The optimizer updates the optimizer states and model weights.
So what changes when we use multiple GPUs? Let’s look at the most straightforward implementation of distributed training on four GPUs (Distributed Data Parallelism):
What’s changed? Now:
Each GPU processes its own chunk of a larger data batch, allowing us to increase the batch size fourfold with the same memory load.
We need to synchronize the GPUs. To do this, we average gradients among GPUs using all_reduce to ensure the weights on different maps are updated synchronously. The all_reduce operation is one of the fastest ways to implement this: it’s available in the NCCL (NVIDIA Collective Communications Library) and supported in the torch.distributed package.
Let’s recall the different communication operations (they are referenced throughout the article):
These are the issues we encounter with those communications:
In all_reduce operations, we send twice as many gradients as there are network parameters. For example, when summing up gradients in fp16 for Llama 70B, we need to send 280 GB of data per iteration between maps. In today’s clusters, this takes quite a lot of time.
Weights, gradients, and optimizer states are duplicated among maps. In mixed precision training, the Llama 70B and the Adam optimizer require over 1 TB of memory, while a regular GPU memory is only 80 GB.
This means the redundant memory load is so massive we can’t even fit a relatively small model into GPU memory, and our training process is severely slowed down due to all these additional operations.
Is there a way to solve these issues? Yes, there are some solutions. Among them, we distinguish a group of Data Parallelism methods that allow full sharding of weights, gradients, and optimizer states. There are three such methods available for Torch: ZeRO, FSDP, and Yandex’s YaFSDP.
ZeRO
In 2019, Microsoft’s DeepSpeed development team published the article ZeRO: Memory Optimizations Toward Training Trillion Parameter Models. The researchers introduced a new memory optimization solution, Zero Redundancy Optimizer (ZeRO), capable of fully partitioning weights, gradients, and optimizer states across all GPUs:
The proposed partitioning is only virtual. During the forward and backward passes, the model processes all parameters as if the data hasn’t been partitioned. The approach that makes this possible is asynchronous gathering of parameters.
Here’s how ZeRO is implemented in the DeepSpeed library when training on the N number of GPUs:
Each parameter is split into N parts, and each part is stored in a separate process memory.
We record the order in which parameters are used during the first iteration, before the optimizer step.
We allocate space for the collected parameters. During each subsequent forward and backward pass, we load parameters asynchronously via all_gather. When a particular module completes its work, we free up memory for this module’s parameters and start loading the next parameters. Computations run in parallel.
During the backward pass, we run reduce_scatter as soon as gradients are calculated.
During the optimizer step, we update only those weights and optimizer parameters that belong to the particular GPU. Incidentally, this speeds up the optimizer step N times!
Here’s how the forward pass would work in ZeRO if we had only one parameter tensor per layer:
The training scheme for a single GPU would look like this:
From the diagram, you can see that:
Communications are now asynchronous. If communications are faster than computations, they don’t interfere with computations or slow down the whole process.
There are now a lot more communications.
The optimizer step takes far less time.
The ZeRO concept implemented in DeepSpeed accelerated the training process for many LLMs, significantly optimizing memory consumption. However, there are some downsides as well:
Many bugs and bottlenecks in the DeepSpeed code.
Ineffective communication on large clusters.
A peculiar principle applies to all collective operations in the NCCL: the less data sent at a time, the less efficient the communications.
Suppose we have N GPUs. Then for all_gather operations, we’ll be able to send no more than 1/N of the total number of parameters at a time. When N is increased, communication efficiency drops.
In DeepSpeed, we run all_gather and reduce_scatter operations for each parameter tensor. In Llama 70B, the regular size of a parameter tensor is 8192 × 8192. So when training on 1024 maps, we can’t send more than 128 KB at a time, which means network utilization is ineffective.
DeepSpeed tried to solve this issue by simultaneously integrating a large number of tensors. Unfortunately, this approach causes many slow GPU memory operations or requires custom implementation of all communications.
As a result, the profile looks something like this (stream 7 represents computations, stream 24 is communications):
Evidently, at increased cluster sizes, DeepSpeed tended to significantly slow down the training process. Is there a better strategy then? In fact, there is one.
The FSDP Era
The Fully Sharded Data Parallelism (FSDP), which now comes built-in with Torch, enjoys active support and is popular with developers.
What’s so great about this new approach? Here are the advantages:
FSDP combines multiple layer parameters into a single FlatParameter that gets split during sharding. This allows for running fast collective communications while sending large volumes of data.
Based on an illustration from the FSDP documentation
FSDP has a more user-friendly interface: — DeepSpeed transforms the entire training pipeline, changing the model and optimizer. — FSDP transforms only the model and sends only the weights and gradients hosted by the process to the optimizer. Because of this, it’s possible to use a custom optimizer without additional setup.
FSDP doesn’t generate as many bugs as DeepSpeed, at least in common use cases.
Dynamic graphs: ZeRO requires that modules are always called in a strictly defined order, otherwise it won’t understand which parameter to load and when. In FSDP, you can use dynamic graphs.
Despite all these advantages, there are also issues that we faced:
FSDP dynamically allocates memory for layers and sometimes requires much more memory than is actually necessary.
During backward passes, we came across a phenomenon that we called the “give-way effect”. The profile below illustrates it:
The first line here is the computation stream, and the other lines represent communication streams. We’ll talk about what streams are a little later.
So what’s happening in the profile? Before the reduce_scatter operation (blue), there are many preparatory computations (small operations under the communications). The small computations run in parallel with the main computation stream, severely slowing down communications. This results in large gaps between communications, and consequently, the same gaps occur in the computation stream.
We tried to overcome these issues, and the solution we’ve come up with is the YaFSDP method.
YaFSDP
In this part, we’ll discuss our development process, delving a bit into how solutions like this can be devised and implemented. There are lots of code references ahead. Keep reading if you want to learn about advanced ways to use Torch.
So the goal we set before ourselves was to ensure that memory consumption is optimized and nothing slows down communications.
Why Save Memory?
That’s a great question. Let’s see what consumes memory during training:
— Weights, gradients, and optimizer states all depend on the number of processes and the amount of memory consumed tends to near zero as the number of processes increases. — Buffers consume constant memory only. — Activations depend on the model size and the number of tokens per process.
It turns out that activations are the only thing taking up memory. And that’s no mistake! For Llama 2 70B with a batch of 8192 tokens and Flash 2, activation storage takes over 110 GB (the number can be significantly reduced, but this is a whole different story).
Activation checkpointing can seriously reduce memory load: for forward passes, we only store activations between transformer blocks, and for backward passes, we recompute them. This saves a lot of memory: you’ll only need 5 GB to store activations. The problem is that the redundant computations take up 25% of the entire training time.
That’s why it makes sense to free up memory to avoid activation checkpointing for as many layers as possible.
In addition, if you have some free memory, efficiency of some communications can be improved.
Buffers
Like FSDP, we decided to shard layers instead of individual parameters — this way, we can maintain efficient communications and avoid duplicate operations. To control memory consumption, we allocated buffers for all required data in advance because we didn’t want the Torch allocator to manage the process.
Here’s how it works: two buffers are allocated for storing intermediate weights and gradients. Each odd layer uses the first buffer, and each even layer uses the second buffer.
This way, the weights from different layers are stored in the same memory. If the layers have the same structure, they’ll always be identical! What’s important is to ensure that when you need layer X, the buffer has the weights for layer X. All parameters will be stored in the corresponding memory chunk in the buffer:
Other than that, the new method is similar to FSDP. Here’s what we’ll need:
Buffers to store shards and gradients in fp32 for the optimizer (because of mixed precision).
A buffer to store the weight shard in half precision (bf16 in our case).
Now we need to set up communications so that:
The forward/backward pass on the layer doesn’t start until the weights of that layer are collected in its buffer.
Before the forward/backward pass on a certain layer is completed, we don’t collect another layer in this layer’s buffer.
The backward pass on the layer doesn’t start until the reduce_scatter operation on the previous layer that uses the same gradient buffer is completed.
The reduce_scatter operation in the buffer doesn’t start until the backward pass on the corresponding layer is completed.
How do we achieve this setup?
Working with Streams
You can use CUDA streams to facilitate concurrent computations and communications.
How is the interaction between CPU and GPU organized in Torch and other frameworks? Kernels (functions executed on the GPU) are loaded from the CPU to the GPU in the order of execution. To avoid downtime due to the CPU, the kernels are loaded ahead of the computations and are executed asynchronously. Within a single stream, kernels are always executed in the order in which they were loaded to the CPU. If we want them to run in parallel, we need to load them to different streams. Note that if kernels in different streams use the same resources, they may fail to run in parallel (remember the “give-way effect” mentioned above) or their executions may be very slow.
To facilitate communication between streams, you can use the “event” primitive (event = torch.cuda.Event() in Torch). We can put an event into a stream (event.record(stream)), and then it’ll be appended to the end of the stream like a microkernel. We can wait for this event in another stream (event.wait(another_stream)), and then this stream will pause until the first stream reaches the event.
We only need two streams to implement this: a computation stream and a communication stream. This is how you can set up the execution to ensure that both conditions 1 and 2 (described above) are met:
In the diagram, bold lines mark event.record() and dotted lines are used for event.wait(). As you can see, the forward pass on the third layer doesn’t start until the all_gather operation on that layer is completed (condition 1). Likewise, the all_gather operation on the third layer won’t start until the forward pass on the first layer that uses the same buffer is completed (condition 2). Since there are no cycles in this scheme, deadlock is impossible.
How can we implement this in Torch? You can use forward_pre_hook, code on the CPU executed before the forward pass, as well as forward_hood, which is executed after the pass:
This way, all the preliminary operations are performed in forward_pre_hook. For more information about hooks, see the documentation.
What’s different for the backward pass? Here, we’ll need to average gradients among processes:
We could try using backward_hook and backward_pre_hook in the same way we used forward_hook and forward_pre_hook:
But there’s a catch: while backward_pre_hook works exactly as anticipated, backward_hook may behave unexpectedly:
— If the module input tensor has at least one tensor that doesn’t pass gradients (for example, the attention mask), backward_hook will run before the backward pass is executed. — Even if all module input tensors pass gradients, there is no guarantee that backward_hook will run after the .grad of all tensors is computed.
So we aren’t satisfied with the initial implementation of backward_hook and need a more reliable solution.
Reliable backward_hook
Why isn’t backward_hook suitable? Let’s take a look at the gradient computation graph for relatively simple operations:
We apply two independent linear layers with Weight 1 and Weight 2 to the input and multiply their outputs.
The gradient computation graph will look like this:
We can see that all operations have their *Backward nodes in this graph. For all weights in the graph, there’s a GradAccum node where the .grad of the parameter is updated. This parameter will then be used by YaFSDP to process the gradient.
Something to note here is that GradAccum is in the leaves of this graph. Curiously, Torch doesn’t guarantee the order of graph traversal. GradAccum of one of the weights can be executed after the gradient leaves this block. Graph execution in Torch is not deterministic and may vary from iteration to iteration.
How do we ensure that the weight gradients are calculated before the backward pass on another layer starts? If we initiate reduce_scatter without making sure this condition is met, it’ll only process a part of the calculated gradients. Trying to work out a solution, we came up with the following schema:
Before each forward pass, the additional steps are carried out:
— We pass all inputs and weight buffers through GateGradFlow, a basic torch.autograd.Function that simply passes unchanged inputs and gradients through itself.
— In layers, we replace parameters with pseudoparameters stored in the weight buffer memory. To do this, we use our custom Narrow function.
What happens on the backward pass:
The gradient for parameters can be assigned in two ways:
— Normally, we’ll assign or add a gradient during the backward Narrow implementation, which is much earlier than when we get to the buffers’ GradAccum. — We can write a custom function for the layers in which we’ll assign gradients without allocating an additional tensor to save memory. Then Narrow will receive “None” instead of a gradient and will do nothing.
With this, we can guarantee that:
— All gradients will be written to the gradient buffer before the backward GateGradFlow execution. — Gradients won’t flow to inputs and then to “backward” of the next layers before the backward GateGradFlow is executed.
This means that the most suitable place for the backward_hook call is in the backward GateGradFlow! At that step, all weight gradients have been calculated and written while a backward pass on other layers hasn’t yet started. Now we have everything we need for concurrent communications and computations in the backward pass.
Overcoming the “Give-Way Effect’
The problem of the “give-way effect” is that several computation operations take place in the communication stream before reduce_scatter. These operations include copying gradients to a different buffer, “pre-divide” of gradients to prevent fp16 overflow (rarely used now), and others.
Here’s what we did:
— We added a separate processing for RMSNorm/LayerNorm. Because these should be processed a little differently in the optimizer, it makes sense to put them into a separate group. There aren’t many such weights, so we collect them once at the start of an iteration and average the gradients at the very end. This eliminated duplicate operations in the “give-way effect”.
— Since there’s no risk of overflow with reduce_scatter in bf16 or fp32, we replaced “pre-divide” with “post-divide”, moving the operation to the very end of the backward pass.
As a result, we got rid of the “give-way effect”, which greatly reduced the downtime in computations:
Restrictions
The YaFSDP method optimizes memory consumption and allows for a significant gain in performance. However, it also has some restrictions:
— You can reach peak performance only if the layers are called so that their corresponding buffers alternate. — We explicitly take into account that, from the optimizer’s point of view, there can be only one group of weights with a large number of parameters.
Test Results
The resulting speed gain in small-batch scenarios exceeds 20%, making YaFSDP a useful tool for fine-turning models.
In Yandex’s pre-trainings, the implementation of YaFSDP along with other memory optimization strategies resulted in a speed gain of 45%.
Now that YaFSDP is open-source, you can check it out and tell us what you think! Please share comments about your experience, and we’d be happy to consider possible pull requests.
*This post was written by Mikhail Khrushchev, the leader of the YandexGPT pre-training team, and originally published here. We thank Yandex for their insights and ongoing support of TheSequence.
#approach#Article#attention#Blue#bugs#cluster#clusters#code#Collective#communication#communications#computation#cpu#CUDA#data#developers#development#documentation#efficiency#flash#Full#gpu#gradients#Graph#how#illustration#insights#interaction#issues#it
0 notes
Note
now i'm curious about who (in your opinion) would actually with the whole "burning down the world for their lover" thing. or perhaps something slightly less dramatic, for burning down the world is a messy and ecologically questionable business.
alternatively an extreme "will burn down the world for you" to mild yet constant "will do their dishes and fill out their taxes dutifully with you" gradient graph.
[Referencing this post!]

Honestly, I don’t think any of them are 😭 simply for the fact that “I’d burn the world down for you” is actually really vague and does not account for different takes on how far “far” really is? The trope assumes an extreme. Realistically, each character would have their own limits and exceptions that are not fully captured in such a broad statement. There’s other issues too. Characters change over time and are different at different points in the story. The trope can easily go from loyalty/devotion to overprotectiveness (based on the interpretation or execution), and it calls into question the characters’ ability to respect their partner’s independence. None of this nuance is considered by condensing all characters and comparing them to a trope.
For example, Riddle is generally known to have an explosive rage, and would quite literally burn the world down if he is threatened or rules/laws/social etiquette is disobeyed. You could, then, make the argument that he would fiercely be there for his partner. However, Riddle becomes much meeker when it comes to matters regarding his mother. Would he overcome his own fears and ��stand up” for his partner to his mother? What if his partner was the one to break a rule or a law? Would he let it slide, even though he tries to be equally strict with everyone?
Even characters that do play fast and loose with their morals don’t exactly fit or wouldn’t commit to the extremes all the time. What if Floyd loses his interest in the situation (because, let’s be real here, no one, not even himself, can control when his mood or interest fluctuates)? Leona would assess a situation and think first, act later, rather than immediately reacting. Several of the other characters have to think about their own reputations + how the public views them and cannot just do whatever they want whenever they want (royals, celebrities, the mega-rich, etc.) for the sake of love.
I know that using tropes to describe things can be a quick and easy way to label and categorize. However, I think that seeing media as “tropes” can oversimplify complex characters and stories in order to make them neatly fit a square block into a square peg. I also think this can unintentionally lead to the witch hunting or hatred of certain tropes (like the love triangle or miscommunication/misunderstanding) due to the frequency with which they are used rather than stopping to consider the quality of its execution each time.
doeyegshsjw I hope this doesn’t come across as shaming the question (I’m not, I promise!!), I saw the opportunity to discuss the tropeification of media and took it 😂 Nothing wrong with liking or disliking certain tropes, of course!! And nothing wrong if you create or consume this particular trope in regards to your own ships. I just personally don’t enjoy sorting characters into these really broad categories, I prefer to stare at them through a magnifying glass 🔎
#I love yapping about tropes and writing though#twisted wonderland#twst#disney twisted wonderland#disney twst#Riddle Rosehearts#Leona Kingscholar#Floyd Leech#notes from the writing raven#question#twst x reader#twisted wonderland x reader
63 notes
·
View notes
Text
how i make color palettes of my ocs before i pick one, an art tutorial?
hello, whenever i made a new design for myself i found a way to make lots of color palettes and pick one! i see this method more in paintings and rendering but not much on character designs? here are some examples i used that on.


it helps me so much when i feel experimental with colors. here are what you need
a wip character design. sketchy or pixel art works better since the colors can have some anti aliasing issues
a program with gradient maps. i'm using clip studio paint but ik photoshop also has it. like i said this is used more on photos or paintings
and here's what you do!
draw your character. i'm making a new fursona for myself but anything should work.

2. decide on their markings/color placement in grayscale. i recommend doing grayscale so you can easily see the values. split your grays into however colors you want. i like doing 5-6 the most. i reccomend duplicating the color layer if you wanna try multiple palettes.
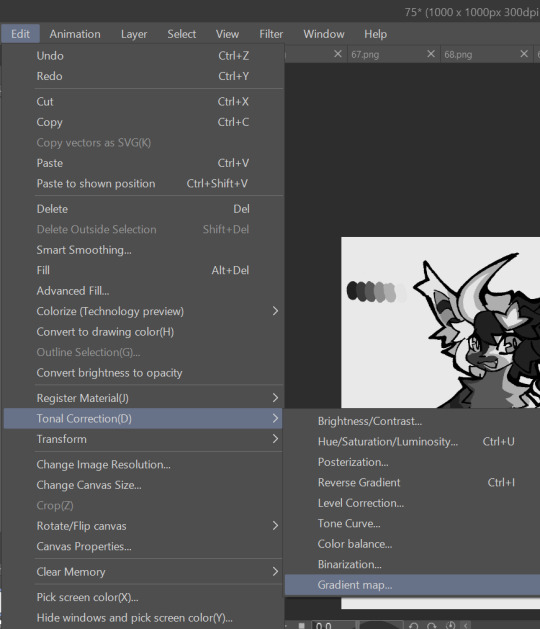
3. this part is program dependent but in csp's case go to edit > tonal correction > gradient map.
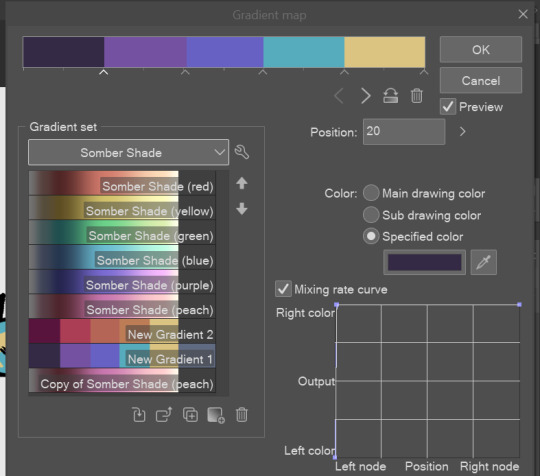
4. i made a few default 5 color gradient maps but if don't use gradients like me i reccomend making the graph like this so they become solid color. split the map into however many colors you used. i'll add a color to the red-orange one bc my character has 6 grays.
5. replace the colors by clicking below specified color. it all depends on your creativity and what you want. experiment til you like it.

6. fuck around, try stuff, put them together to see if you like any of em. i made 9 to see if i can focus on one of them and i actually ended up loving the bottom right. it really makes them shiny

7. (optional) if you like a palette you can further and play with colors while keeping the palette. you can use color balance (in the same menu as gradient map in csp) or layers to mess around, have fun!
also a color tip because people seem to compliment that a lot in my art: digital art has millions of colors! don't be afraid of using wacky tones unless you're going pantone. if you want to get something physical i recommend being open to alternative colors as they tend to be more limited. i know whoever is doing it will try their best to keep the colors close.
color theory is something i don't...care much about mostly because this is something i'm doing for fun. i'll consider it in professional work.
#artists on tumblr#digital art#ika's showtime#ikarnival#art tutorial#art tips#drawing tips#art resources#clip studio paint
420 notes
·
View notes
Text
Hi. You know what I wanna see in the new Tomodachi Life? Of course you do. I've been cooking this list for ten years.
Mii Customization
A makeup system similar to Miitopia's, if not the exact same one, is essential. While I personally still want my Miis to look like Miis, it feels pretty crucial to have those kinds of makeup options even for just Miis. Being able to share them is also a must. Bonus if we get tattoos.
It seems like we're getting new hairstyles, with an option to use an ombre gradient on them. I want them to go nuts. Different bangs options for certain hairstyles. Different ponytail/pigtail options. All kinds of different textures and styles. Anime-esque styles. Realistic styles. Textured hairstyles. Ahoge options like in Miitopia. Let me go apeshit.
Speaking of... Fantasy skintones. Customizable skintones, eye colors, and makeup colors. The skintones is a must for me, but I'm sure there are people out there who would LOVE to have that option too, to get their skintone just right, but also the skintones of their OCs and favorite characters.
Separated tops, bottoms, shoes, socks, hats, glasses, accessories, a la Miitomo, with more ability to customize their appearances. Bonus option: Allow people to make their own shirts and hoodies and such like in Animal Crossing, with a hub where you can share your creations with others. Bonus 2x if it uses the Miitopia makeup system and you can do all kinds of shapes.
Mii Personalities and Interactions
Traits a la Sims. The MBTI-based sliders were fine, but I want to mix and match traits, and I want those traits to mean something. I want those traits to heavily influence how a Mii reacts to situations, and not just influence their pose and funky things they say.
Memories. I want Miis to remember the fights they had, the good times and the bad (within reason), also like Sims. I want those memories to influence their relationships.
I need these motherfuckers to have cliques and friend groups and as complex of social lives as Nintendo can make them. I want to be able to make a graph of my Mii's relationships. And I want some influence over it, not just RNG. I personally don't want a TON of influence but I want some.
Yeah of course make them gay as shit. I'm not stupid of course I want gay Miis and queer Miis. I saw someone suggest opting out of relationships and babies and such and that's a damn fine idea too.
Not just traits, but preferences you can set. Likes the color red. Dislikes the smell of lemons. Loves horses. Dislikes corn. Likes goth clothes. Dislikes preppy outfits. Stuff like that.
Gameplay
I want to decorate each individual Mii apartment like in Animal Crossing. I want people to go apeshit nuts with furniture and whatnot. Complex builds. Some pre-determined rooms or room bases would be nice, and even just "you can put this thing in this room slot" would be fine too. Bonus if you can customize colors.
More group activities for Miis. More minigames and such. I actually haven't considered this one as much because I liked what we had and most of my desires are fine-tuning Miis, and we clearly already got it so the little guys can wander around outside.
But if they can wander outside I'd love more locations, more building types, more hangouts, more things to do.
Basically I need this to be the perfect ant farm of all the shit I like.
And that's a fairly complete list.
42 notes
·
View notes
Text
Monday Musings: How Does Magma Form and What is it Made Of?
The inside of our planet is full of left over heat from when it was created plus new heat from the decay of radioactive elements. However, the crust of the earth does not float on a sea of molten rock as some models predict. Molten rock, or magma, only forms in certain places under special conditions.
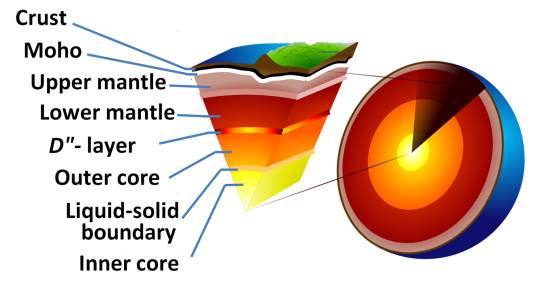
The upper mantle gets to temperatures comparable to those of lava, however due to the great pressure it is under, the rock remains solid. So, how can melt rock if pressure prevents melting? Lessen the pressure but keep the temperature unchanged. We use geothermal gradients to determine just where that point is.
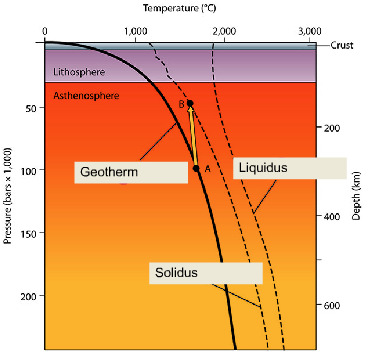
The geotherm is the temperature as a function of depth. The solidus represents conditions at which rock starts to melt and the liquidus represents the conditions at which rock completely melts. What this graph shows from point A to point B, the pressure decreases a lot but only cools a little. We call this decompression melting.
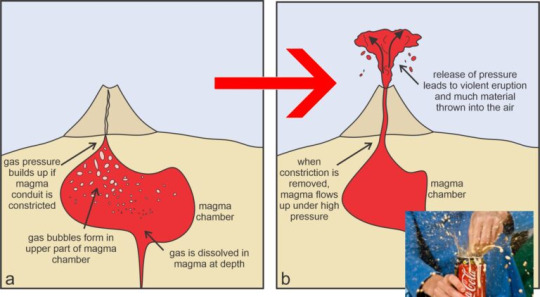
Another way rock can melt is through the addition of volatiles. Volatiles are substances that evaporate easily and can exist as gases at Earth surface pressures. Typically, these are water or carbon dioxide. This will drop the melting temperature of the hot, dry rock. We sometimes call this flux melting.
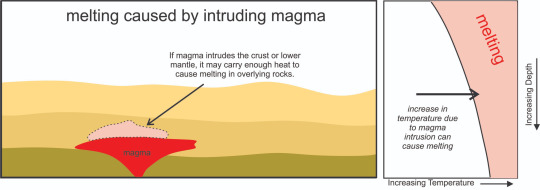
The third way to melt rock is to inject hot magma into the crust. If it has enough heat, it will raise the temperature of the surrounding rock which may be just enough to melt part of it. Thing hot fudge in ice cream. We call this heat-transfer melting.
Now that we have the how, let's learn about the composition. What is magma made out of? Lots of elements actually. Silica is a big portion. Silica is made of silicon-oxygen tetrahedrons.
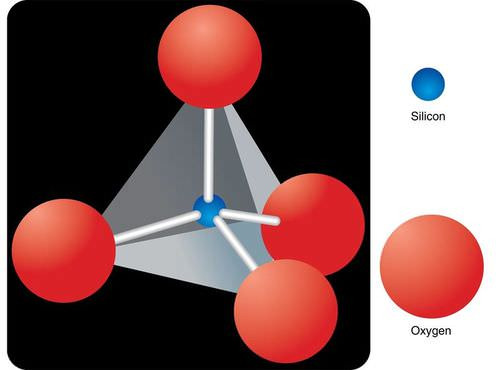
There are also other elements such as aluminum, calcium, sodium, magnesium, and iron. If it is a "wet magma" it will also contain elements that form volatiles such as water, carbon dioxide, sulfur dioxide, nitrogen, and hydrogen. "Dry magmas" do not contain volatiles.
There are four major types of magma based on the amount of silica present. These are ultramafic, mafic, intermediate, and felsic.
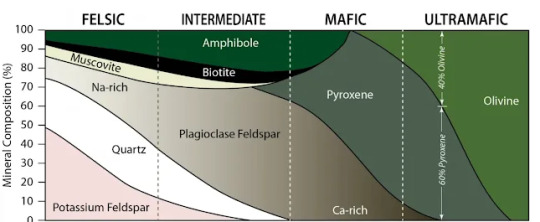
Ultramafic magmas have almost no silica in them. They are primarily made of olivine and pyroxenes, ferromagnesium minerals. Some will have a little bit of calcium-rich plagioclase.

Mafic rocks start to lose the high olivine content and add other minerals like amphiboles and biotite as well as a mixture of calcium and sodium-rich plag. Ultramafic and mafic rocks tend to be very dark in color. This magma has a low viscosity and flows easily.

Intermediate igneous rocks typically contain between 52% and 63% silica content. Here we lose olivine completely and add quartz and k-spar as well as increasing the amount of sodium-rich plag, biotite, and amphiboles while decreasing the amount of pyroxene. Here we start to add muscovite as well. The color also tends to be a mix of light and dark minerals.

Finally, we have felsic rocks which contain more than 65% silica content. They are primarily made of quartz, k-spar, and sodium-rich plag. There are also smaller amounts of mica (muscovite and biotite) and amphibole. These igneous rocks are light in color. They are also highly viscous and resistant to flow.

Today's lesson is now at an end but make sure you tune in tomorrow for some trivia! Fossilize you later!

#fun facts#geology#science#science education#mineralogy#igneous rock#magma#magma composition#mafic#ultramafic#felsic#how to make a rock melt#science side of tumblr#volcanology#igneous petrology
34 notes
·
View notes
Text

Gradient Graphs, no. 38
This post features art created by running azurepolarbear's original “Gradient Graphs” generative code art algorithm. Each run of the code produces a random visual output. Random points are generated on the canvas and assigned a color. Those points are connected by lines and circles that have a gradient from one point color to the other. The connected points will form either a gabriel graph or a random geometric graph, which both have roots in graph theory.
Made with JavaScript and p5.js.
Copyright (C) 2022-2025 brittni and the polar bear LLC. Some rights reserved.
#code art#code artist#algorithmic art#algorithmic artist#digital art#digital artist#p5js#made with javascript#creative coding#fxhash#women who code#black women who code#black art#black artist#graph theory#gradient graphs#abstract#abstract art#geometric#geometric art#artists on tumblr#computer art#creative computing
3 notes
·
View notes
Text
Five new autistic flags! And a nautilus as a symbol of the spectrum 💛
My current autistic hyperfixation has been the question of the autistic flag. By this I mean a flag for autism specifically rather than a broader neurodiversity flag.
Between autistic flag designs that look too similar to the Métis flag to a new flag design that looks annoyingly similar to intersex flag designs, none of the designs I've found for an autism-specific flag I've found have felt right.
So, I've made a whole bunch of alternative flags, varying from tweaks to existing flags to ground-up redesigns. Here's my current shortlist. Feel free to use any or all of them, or remix as desired! <3




I'll start with describing the flags that are tweaks of existing designs, and work my way to the nautilus, which I'm introducing as an alternative symbol for the autistic spectrum.
Flag Idea 1: golden infinity symbol on white background Most neurodivergent flags I've seen is a rainbow infinity (usually an infinity loop) on a white background; this is the oldest kind of design, from 2005. Many people are already using a gold infinity symbol (ideally an infinity loop) as a symbol for autism, because Au = gold.
I took the gold infinity symbol used to represent autism in the 2023 Autistic Progress Pride Flag, and stuck it on a white background, in the style of neurodiversity flags. I tweaked the infinity loop a little bit to further visually distinguish it from the Métis flag.
Flag Idea 2: fixing the red-yellow-green autistic flag This one takes the 2021 red-yellow-green autistic flag and replaces the problematic white lemniscate infinity symbol (which has been used to represent the Métis since 1815) with a dark red infinity loop. Red is another popular colour in autistic designs as a fuck you to Autism Speaks (fuck Autism Speaks).
Flag Idea 3: recolouring the Disability Pride flag (AuTiSTiC) There are two ideas in this flag. The first is to take the Magill disability pride flag and recolour the diagonal stripes to represent autism.
Since gold is used in autistic designs because Au->Autistic? Let's go all in. This flag has the colours of: Au: gold Ti: titanium (light grey) S: sulphur (light yellow) Ti: titanium (light grey again) C: carbon (off-black)
This is unashamedly dorky and I feel like if any minority group gets to have a dorky flag it should be us autistics.

Flag Idea 4: golden infinity + disability pride flag These flags represent the accumulation of the ideas thus far. Gold infinity symbol plus disability pride flag. I tried putting the infinity directly on the diagonal stripes and it was too busy, so I've moved them to the corners.
On the left is a version with the disability pride flag colours. On the right is a version using a yellow-white-yellow stripe design from the 2021 neurodiversity flag that's based on the disability pride flag.
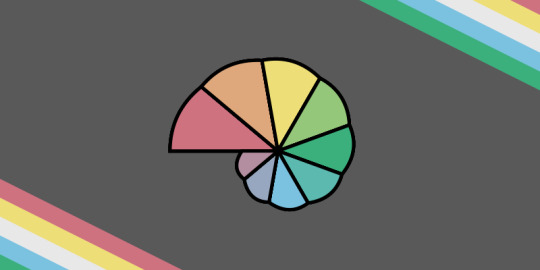
Flag Idea 5: the rainbow nautilus for the spectrum After showing earlier drafts of all of these flags to a bunch of my autistic friends, a consistent feedback was that none of us were actually that keen on the infinity symbol as a symbol of autism (even without the Métis issue).
I think flags are an opportunity to tell outsiders about what we’re about. One thing I want to convey about being autistic is that the autistic spectrum does NOT mean a gradient from autistic to non-autistic. Here’s a visualization I like:
So I got to thinking about how to visualize that polar graph. I realized a nautilus shell works on a number of levels:
To convey the polar graphs in a stylized way
A fractal shape keeps with the theme of infinity
We autistic folks tend to live in our metaphorical shells =)
Best as I can tell from google text & image searches, the nautilus is not used by any minority groups or geographic regions for flags. A handful of businesses and software projects have nautilus logos, so I iterated design to be nice and distinct.
Here's another version with the gold-and-white neurodiversity stripes:
I also wanna note that as somebody who has ADHD and autism that I am 100% fine with anybody who wants to use the nautilus for AuDHD - the very idea of the autism spectrum was to unite highly intertwined diagnosis categories and personally I think it's reasonable to include ADHD in the autism spectrum.
If you would like alternative versions / tweaks to these flags, let me know in the comments. I also want to be explicit that I release all of these designs in the public domain, so you are free to reuse and remix as desired! 💛
I've tried to provide a nice range of options from remixing existing designs to new ideas, and I hope everybody can find at least one autistic flag they like that is also distinct from other minority groups (e.g. Métis, intersex). I've also posted a detailed overview on infinity symbol design for anybody designing new flags! 💛
If you have any favourites or ideas for flags let me know! I'm curious which ones people will like most. edit: uploaded the SVGs to Wikimedia commons for anybody who wants to play with them.
#autistic#actually autistic#neurodivergent#autistic flag#autistic pride flag#autistic pride day#autistic pride#neurodiversity#autism#autism rights#autism pride#actuallyautistic#new flag#flag design
115 notes
·
View notes
Text
Engineer: *standing before a linegraph* Alright, today we’ll be talking about how we can Find Out and how much we can Find Out and what it takes to get there.
Engineer: So first we have to decide, “how much do we want to Find Out?” So, let’s say in this case I want to Find Out at a level of seven, so I find that level on my graph and I come horizontally to my gradient line and where it intersects with my gradient line. I go straight down to where it intersects with my Fuck Around line.
Engineer: *points* That there is going to tell me how much I have to Fuck Around to Find Out what I need to Find Out.
Engineer: So, as you can see the more you Fuck Around the more you’re going to Find Out, and also, if you stayed on here and you never Fucked Around you will never Find Out.
Engineer: So, I hope you found this lesson is helpful. Thank you.
42 notes
·
View notes
Text
A while ago, I quickly wrote a post about the OKLCH Color Picker, and the neat insight it gives about digital colors.
Ever since, however, I have heard the confusion of many people as to where the holes in those graphs come from. And although I am far from an expert in these things, I thought we could do a small exploration of one of the principles behind it.
Also, if any actual experts spot any mistakes or misconceptions I fell pray to, feel free to leave a correction in the replies!
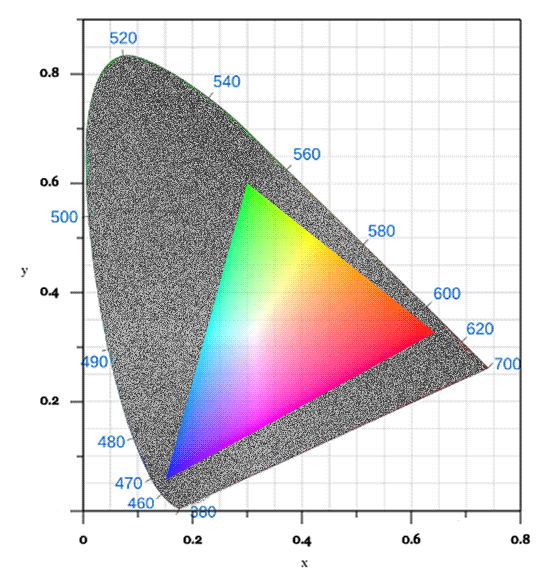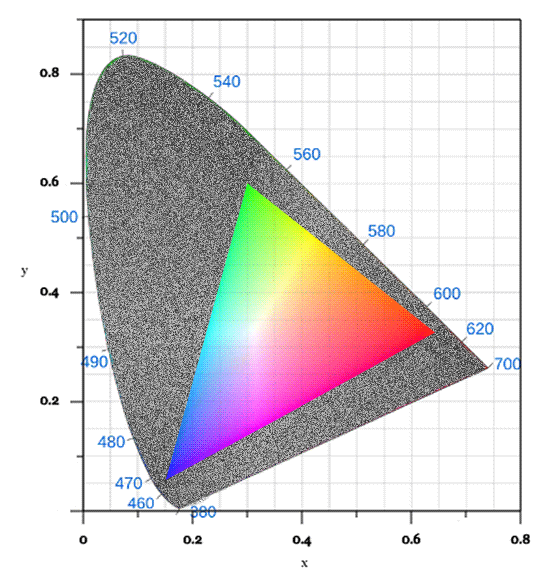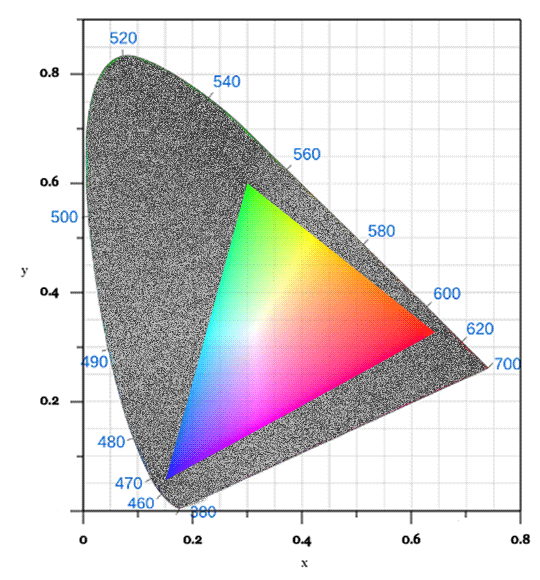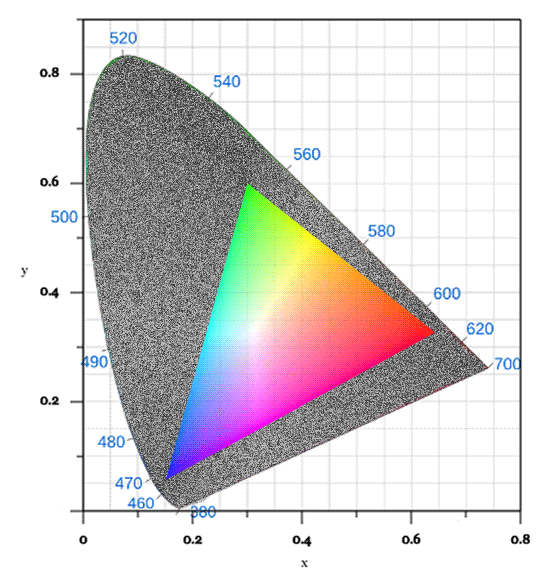
On any discussions of color vision and/or digital color spaces, you are likely to see the following image:

This is the notorious xy chromaticity diagram for the CIE 1931 color space, rendered here in glorious GIF format, as you may notice from the dithering in the gradients. It is an inaccurate representation, sure, but so are all of them.
This color space was designed to mathematically represent all color sensations that are visible to the average person. The diagram visualizes only the chromaticity of this space, that is, only the hue and saturation of the colors, which is what we are really interested in right now. However, the critical issue is: the colors the average display can show are just a small portion of the colors the average human can see.
The sRGB color space is what the average display uses to represent color, probably the default color space of the digital world. If we were to show only the colors sRGB can represent on that diagram, it would look something like this:
Hm. Not good, is it? Look at all the greens we're missing!
That's why we cannot display the accurate chromaticity diagram. The proportion of the colors your display can show is just that small when compared to the full gamut of human vision.
Okay, so how does that leave us with the holes on that colorpicker? Well, let's say I choose this blue color (#008EF7):

That's a nice, strong blue. Not too vivid, but also not muddy in any way. But I wish it was just a little bit greener. Some sort of "greenish blue" tone. Let's see what the color picker tells me:
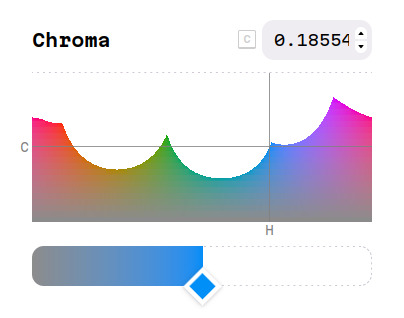
Hm. The color I want is in the hole.
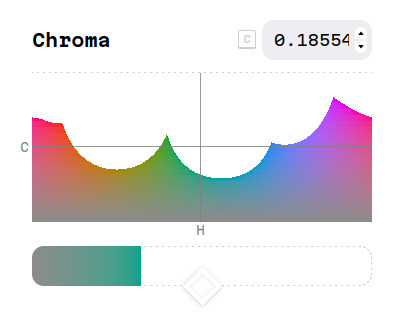
In this graph, the color picker is showing all the available combinations of hue and chroma that have the same lightness of the blue I initially chose. To get out of the hole, I can either bring the chroma slider down, which will make the color grayer and less intense, or I can tweak the hue slider to the sides, going fully towards green instead.
But to be clear, the color I want is not impossible, see. If we use some questionable math tricks, we can pinpoint where those two colors would fall in that CIE chromaticity diagram:

In there, we can see that the blue is right at the edge of what the average display can show, while the "greenish blue" I wanted is straight out. Again, this is a color that I can see, and could very well be trying to take a photo of out there somewhere, only to face the cruel constraints of sRGB.
105 notes
·
View notes
Text
๋࣭⭑ Devlog #38 | 2.27.24 ๋࣭⭑

How is it already almost March omfg.
Anyways Happy Valentine's Day month!!! This year, I was swamped with work, so I didn't get a chance to make Valentine's Day art. I did make a Valentine's piece last year though.
BUT we did have beloved @magunalafay make these Valentine's Day cards this year for the community!!! <3 If you missed it, well Happy Valentine's Day!!!!!

She made these as a gift, and I love her very much. Maguna u r so talented
This month was pretty busy for me, but I'm super happy with the progress made this month ^^ I feel like I've started the year off in a pretty good groove after it being all over the place for a hot second, yay!!!

This past month, Etza and Druk's routes. With the revamped demo finishing its revisions, it left a lot more time for me to focus writing on full route development.
If you missed the announcement, I FINISHED Etza's first draft!!! YAAAYYY!!!! FINALLY!!!!!!

That means 4/6 routes are finished in terms of the base writing, which is so exciting to MEEEEE. I've always seen Etza's draft as The Milestone because with their route finished, it would mean the four Central routes are done writing. And to me, while there's a good chuck of writing left, we are nearing the end of it.
There's only two routes left and that means it's about ~100k words which is CRAZY compared to when I had ~300k to write (:cries:). Even if that sounds like a lot, once I start chipping away at those routes, that 100k goes into the "double digits" aka 90k...80k... etc. and that makes me want to pee my pants
We also finished editing Druk's route, yay!!! So we reached a lot of milestones this month ^^

We are nearing the end of the Vui background commissions. It's very bittersweet; I'm so used to mentioning him in my devlogs now </3 There's only like 3(?) more BGs left for him to make, and then all of the BGs for the game will be finished. Very Wild! I think Alaris will have 25ish BGs, and they are all Stunning.
It's been a while since I showed you all a BG, so I'll give you all a preview of one I just got in!

Isn't it cozy? Guess whose house hehe
I personally have been doing a lot of sprite work this month to finish the final art assets for the demo. I added some expressions to Druk and Aisa that I'd been procrastinating (I don't even know why I was procrastinating them). And I finally finished Mom and Kimura's updated sprites! Patreon already saw them, but I'll show the new versions here too ^^


Preview of Mom (left) and Kimura (right) updated sprites. Now everyone's sprite styles are cohesive YAY!!
Aside from sprite work, much of my "art" time has been on finishing up/putting together the last of the screens for the GUI. Specifically, I got THIS BABY up and running. She is my crowning glory.
Memory Screen to Replay Unlocked Free Time Dates
Oh my god.... You all have NO IDEA how much of a pain this was to code. There is a transparency gradient going on in the left and right B&W previews (courtesy of community programming angel feniks/shawna).
And then the effort to have the Titles and Descriptions of the Previewed Date change tilted me on Multiple Occasions. But we finally got it to work thanks to bestie @siyo-koy pointing out I just coded one stupid "if" statement wrong LJAFSLIEFJIEJ. But the effort was WORTH IT because I'm so proud of her!!! I hope you all like it too as a way to relive Free Time Dates. I had a lot of fun with the Titles and descriptions.
I also put together the Stats and Affection Screens


Preview of Personality Stats & Affection Screens
So I coded both of them a bit differently from each other. The Personality Screen shows you a breakdown of your traits so far. Think of it like a pie graph! So in the preview picture, your choices indicate you are 33% Brave, 16% Charismatic, etc. I felt like this was a more natural way to portray personality rather than how many bravery points you've collected so far!
And then for Affection, it works in a more traditional way, where it counts it based on how many you've gotten out of the total amount you can get. This way, as the story progresses, how close you are to the person reflects how much your relationship as developed!
I've also added little descriptions underneath each that change depending on the percentage. So for example, if you have gotten 82% of the affection points for Kuna'a, the description of your relationship might change as well hehe

Other than that, I've mainly focused on getting the demo together. We released the beta demo earlier this month (? LOL). And the feedback has been so kind!!
A lot of this month was spent polishing so that the demo can be ready for early access and eventually public release. I updated sprites, made sure music crossfades with each other so that transitions between soundtracks feel smoother, I added/polished all of the screens I needed to (e.g., Memory Room, Full Credits, Cleaning Music Room, Adding Stats Screens), and I FINALLY as of yesterday added the Voiced Lines!!
One thing I added in the Extended Demo that I'm really happy with is the use of Extended Pronouns (courtesy of Angel Feniks). Below is a preview of how it works now!
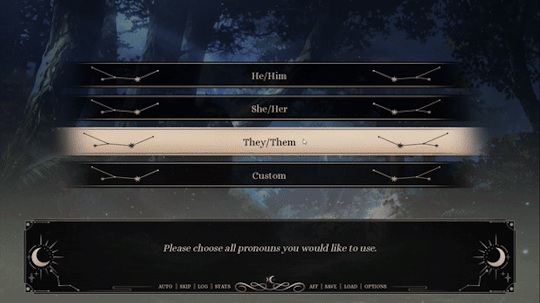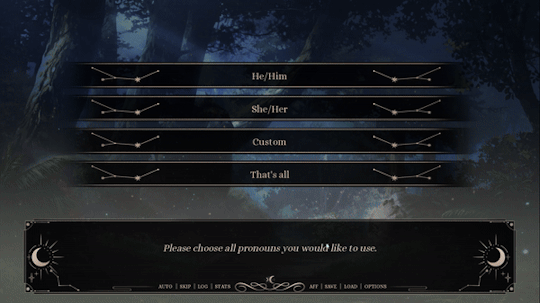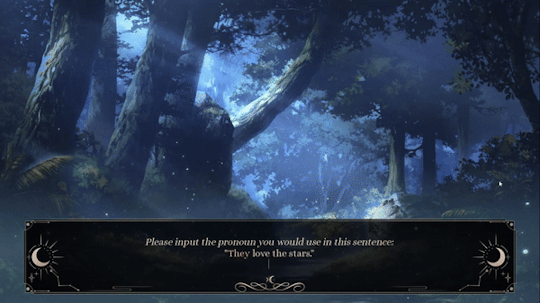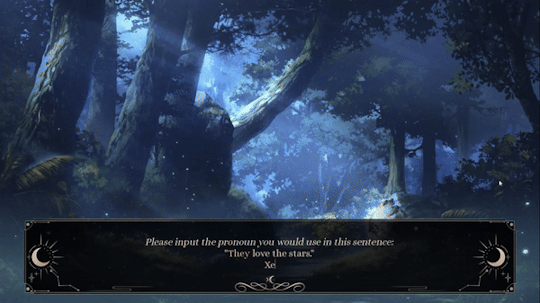
Preview of Extended Pronouns Function. Credit to Feniks
Basically, you can choose multiple pronouns for yourself, including custom pronouns (e.g., xe/xem, fae/faer, etc.). On top of that, you can choose how often you'd like the pronouns to alternate (e.g., every line versus every scene) and what kind of terms you'd like to be used for you (e.g., neutral vs. masculine vs. feminine)!
Overall, the demo is getting closer and closer to release!!! Early Access will hopefully be ready by the end of this week or next, so if you all would like access to it, please feel free to subscribe to my Patreon for this upcoming month! Available to Wyvern tier ($5) and up.

I didn't have any time to really play any games this month because I was drowning in work LMFAOSLJIEF. I did play the Threads of Bay demo by @lavendeerstudios and it was GORGEOUS! Very cute game with lovable characters and charming visuals. Andrew, I will have your number
Every other section was really long, so I'm going to throw it here even though it's not market research. But Intertwine recently hit 600 ratings, which is crazy. Thank you for still enjoying that game even if it's not one that is my main focus anymore. I'm really happy people still like it :on the verge of tears:
Anyways, this has been a long devlog. Here's to continuing to Ball in March. Hope you all have a great rest of your month, and I'll talk to you soon! <3
64 notes
·
View notes
Note
Your art is beautiful! But you use medibang? How did you do the gradient dot? Ive been looking for anyone how they use that because ive only seen medibang users use a gradient dot tool for background only
Ok. I totally see why medibang user only use it for bg because it’s actually not halftone! What they use are a type of layer called net dot and it’s considered as a Ben Day dot effect and not halftone! Here’s a graph to show the distinction:
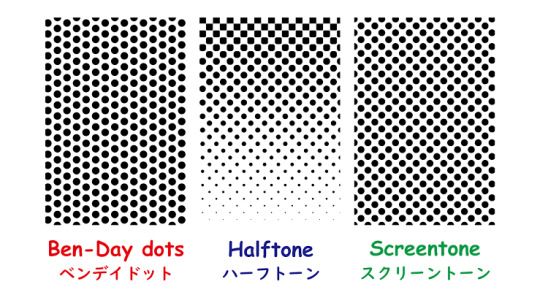
What i use however are a type of pattern brush you can download from the program cloud. It’s still Ben-Day dot and not halftone as you can see.

Here’s how to find it and modify it to your liking!

Look for this pattern brush.


Then go to edit brush. Go down to shape and move it to 0 which give you circle! This brush is great because they also give you 13 shapes to choose from if you want to make other pattern! Then you can edit the shape size and spacing to your liking and even tilt the pattern grid it’s base on. And voila!

You can use opacity by pressure as well but it might be a bit blotchy. I really wish medibang have a halftone brush but this is an ok alternative to it!
270 notes
·
View notes
Text
How I feel about formal speech in Japanese, as a halfie 🇦🇺🇯🇵
How much are one’s values and philosophy forced to be tied to the language you speak? Having grown up in Australia, I live in a culture where there’s no hierarchy-based formality built into the language. Our service workers never call us “sir” or “ma’am” (in fact it feels very off-putting whenever you get a usamerican waiter who does). Calling out to a perfect stranger on the street is done with a “hey, mate” or “hey, excuse me!”. Our speech patterns don’t change too much depending on our familiarity with whoever we’re talking to - and we certainly don’t have separate verb conjugations depending on formality.
Contrast this with Japanese which has several different speech registers depending on familiarity and hierarchy of the person you’re talking to.
Red: Keigo. Used by service staff. Used by low ranking staff to high ranking bosses in workplace situations.
Orange: Formal speech (sentence ending ます, です, ません, etc). Used by younger people when speaking to older people. Used by almost everyone when speaking to a stranger off the street.
Green: Semi-formal speech (sentence ending っす, しないです, etc). Used by people around the same age when speaking to someone they have only recently met, or to work acquaintances and similar.
Blue: Casual speech (sentence ending naked adjectives and nouns, だ, plain form verbs). Used by everyone to their own family. Used between good friends, even if one is a fair amount older. Used by bosses to their employees, teachers to their students.
(Please note this is graph was made by a me, a non-native japanese speaker, and is not backed up by any research. It’s based purely on vibes and its primary purpose is to assist in the explanation of my feelings about being australian-japanese. Also note that in reality there are not hard lines between each of these registers or strict definitions. If this were more accurate it would be more like a gradient)
I don’t want to be seen as rude, so when I’m in Japan I make an effort to speak in a formal register in certain situations (e.g. speaking to service workers, strangers on the street). I’m ok with the far left side of the graph. However, the purple dotted section is the part I have the hardest time with: people around my age who I am not (yet) friends with. As an Australian, I immediately want to speak in a casual register with anyone who has friend-potential — in my culture it’s polite and respectful to treat people like a friend from the start. Unfortunately, this has the reverse meaning in Japanese culture - it’s polite to keep people at arm’s length until you know they’re comfortable being closer with you. To use casual speech with an acquaintance carries an undertone of imposing a friendship on them that they may not want.
Culture and language are intimately linked, but is it possible to speak a language while being informed by a different cultural worldview? Is it possible to speak Japanese with both feet firmly planted in Australian culture? Does doing such a thing transform it into a different language altogether?
It’s certainly possible to speak English with my feet in Australian culture, and I would say that Australian English is a different dialect (with respect to formality registers) when compared to British English or US English. In fact I think US English is more similar to Japanese than it is to Australian English, if we’re just looking at formality.
A lot of what makes this a hard question is how homogenous Japan is, and how people in the Japanese diaspora (e.g. me and my family) don’t have a meaningfully different culture from mainland Japan, unlike other diasporas like Italian Americans. Since basically everyone who speaks Japanese is culturally and ethnically Japanese, the question of separating some of the cultural aspects from the language becomes almost unthinkable, and I would like to shake this unthinkable foundation of thought a bit.
Also, language is a collaborative thing. If I’m the only one speaking single-formality-register Japanese, I’m not speaking a new dialect, I’m just speaking normal Japanese in a weird way. It would take multiple people to understand the nuance of what I mean (not rude, just casual) for my single-register manner of speech to go from speaking normal Japanese rudely to speaking Australian Japanese normally. If I was to somehow assemble a bunch of Japanese-Australians raised in Australia, who learned Japanese with their family as their only input source (casual register only), would we be speak Japanese or some kind of new thing - Australian Japanese?
I wanna speak how I would normally speak in English, when I’m speaking in Japanese. But to do so carries subtext that I’m not trying to convey. If I want to speak without loading my speech with additional subtext I have to conform to the norms. But to do that would be to temporarily cast aside my cultural values on egalitarianism and respect!
So what’s more important - being true to myself and culture when speaking Japanese, or conveying the meaning I intend? Is it the responsibility of Japanese people to understand that people of different cultural backgrounds will speak their language, or is it my responsibility to conform to the way the language is spoken?
#opinion#langblr#japanese#japanese language#linguistics#language#learning japanese#日本語#jimmy blogthong#official blog post
91 notes
·
View notes
Text
got into horse race tests thanks to ronnie and um. uh. well i didnt get into the lore much yet but i am writing a bunch of obscure notes with them
@gotmyass2marz i dont know if me writing this many notes is just me being paranoid that something importants gonna happen with these obscure facts but um,, take my notes :D
race 1
there was a small lag at the beginning starting the race but then cutting back to when the creatures were in the starting area
out of curiosity i colorpicked some stuff and heres what i got (im two frickin seconds in and im already taking notes wtf)
#14FE09 - green for background #EC0105 - red for bet area
i bet blue or white is gonna win ngl
yellow obsessed with that weird area and brown comes to join. then the others come in, blue runs away, and eventually yellow leaves leaving brown alone. then yellow comes again and leaves and comes in again wtf
blue and white are progressing and bounce in sync for JUST A SPLIT SECOND but nope they stopped. yellow and brown ended up leaving and moving around along with white and blue. white is more random, flying up and about and then hopping back in.
at this point im getting faith in yellow and blue
yep blue won
race 2
ten seconds this time for the bet countdown BUT accelerates at the seven second mark
again color picking cause im paranoid for no reason
the green gradient for the background is from #04FF05 to #035505 the brown gradient for the racing grounds is #908D07 (ew thats green gold what the hecl) to #D7B48E which is literally just tan skin
my bets on orange
THERES SOUND FOR EVERYTIME SOMETHING BOUNCES
the sound pitches up and down in a round up graph if i hear correctly and then repeats every third of a second ish
theres a time counter in the lower right corner
its the same map and most of the “horses” hang out at the same circle thing as last round. grey white and cyan are hanging out a lot i like them!!
blue and yellow are much more singled out this time
cyan white and grey are still hanging out a lot but im probably looking too much into this
yellow and orange have a funny dynamic too as yellows movement patterns seem as if its trying to bonk orange
they are much more spread out at the 1:46 mark and yellow is still annoying orange
at the end cyan is the closest to it with yellow trailing it and YELLOW GRABS IT WHAT THE HELL. WHAT THE HELL. I MEAN I BET ON YELLOW BUT LIFE ISNT FAIR MAN I HATE THIS BRO WHAT (hated by life by mafumafu starts playing)
it zooms in on yellow and cyan and it leaves the time tracker behind implying this is a 4th wall break
zooms into the ground and..
what in the unholy hell is that
6 notes
·
View notes