#python tutorial 2018
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In February 2021, Tumblr had 518.6 million blog accounts.
Text
Hey everyone!
I know it’s been a minute, but with the recent news that Automattic has laid off a portion of its workforce (including a sizable percent of tumblr's staff), it's a good time to have a quick chat about the future.
Now, as far as we know, tumblr isn't going anywhere just yet. No need to panic! However, I do recommend that you take into consideration a few things.
1: Backup your tumblr! Here's tumblr's official guide to doing so. It's always a good idea to have backups of your data and now is a great time to do so.
*I’ll also be including a handful of other links walking you guys through other backup methods at the end of this post. As I understand it, each of them have different pros and cons, and it might be a good idea to have more than one type of backup depending on what you want to save/how you’d like the backup to look/etc.
2: Have some place your mutuals/friends can find you! A carrd or linktree is a great way to list off anywhere you might find yourself on the internet.
3: Once again, don't panic! We don’t know that anything is happening to tumblr anytime soon—it just doesn’t hurt to have a backup. Better to have a plan now instead of being blindsided later.
*The other backup methods I’ve been able to find:
—First off, someone put together a document with several backup methods & pros and cons for each. (I believe it originated from a tumblr post, but with search being the way it is I haven’t been able to track it down.) This goes over a lot, but I’m adding a few more links to this post in case they might be helpful too.
—This post and this video were a good guide to the older “bbolli tumblr-utils backup for beginners” method mentioned in the doc (I used them during the ban in 2018 to make sure I had my main blog saved).
—I’ve also found a handful of python & python 3 tumblr backup tutorial videos out there, in case those would be helpful for you. (I haven’t personally tried these methods out yet, but the videos seem to go over the updated version of tumblr-utils.
#psa#tumblr backup options#doc rambles#again: don’t panic#we don’t know anything is happening right now#but it’s always handy to have a backup just in case!
736 notes
·
View notes
Text
it took some effort to figure out a bit that wasn't working but I followed the python tutorial and backed up my blog to early 2016– I think there's very little I would want from before then. truly a horrific number of posts in the first place. At some point in the future I'm sure I'll say "what the hell is taking up so much space on my hard drive?" and it will be 40,000 images from random posts I reblogged in 2018.
8 notes
·
View notes
Text
It's our 10th birthday!

Django Girls has turned 10! We’re so proud to reach this momentous milestone, and of everything the community has achieved!
During the past decade, 2467 volunteers in 109 countries have run 1137 free workshops. More than 24500 women in 593 cities have attended our events and, for many of them, Django Girls was their first step towards a career in tech.
See them on a map.
How it started
Ola Sitarska and Ola Sendecka founded Django Girls. It all began with a single workshop in Berlin in 2014, and a tutorial written by Ola and Ola. It was (and still is) aimed at complete beginners who have never written any code in their life. 45 women attended the first event, to learn how to build the Internet using HTML, CSS, Python and Django. Between them, they deployed 40 brand-new apps and opened 30 pull requests against the tutorial.
Within a year, more than 70 Django Girls workshops had been held in 34 countries on six continents. To support the huge growth, Ola and Ola then obtained charitable status for the Django Girls Foundation, and ran the organisation for another four years.
Listen to Ola and Ola go down memory lane on the Django Girls podcast.
How it’s going
Today, Django Girls is still thriving, and we currently have 20 workshops, and counting, in the pipeline. There is always room for more! Visit our website to find out how to organise a workshop, or coach at one. 84.9% of respondents to our 10th birthday survey said organising or coaching at our workshops deepened their understanding of Django.
We also caught up with some of our past attendees. After coming to one of our events, 71.2% continued learning to code and 44.7% started working in tech. Here are some of their Django Girls stories…
“I was a stay at home mom. I was learning how to code and had a great experience at the Django Girls workshop. After completing training with an intensive bootcamp, I came back to the workshop as a coach. I am now a data engineer at Xbox.”
- a workshop attendee in 2016 who was also a workshop coach in 2017
“After Django Girls, I improved my grades and graduated. Then I got a job. After completing the senior software engineering position, I was promoted to team leader. That's how Django Girls motivated me so much.”
- a 2016 workshop organiser
“I started working in tech after attending a Django Girls workshop. I am a software engineer in the space industry. When I discovered Django Girls, I was close to the end of my studies in Geomatics engineering and was expecting to start working as a Surveying Engineer or pursue further studies in that field of engineering. The openness and supportive atmosphere of the first Django Girls workshop I attended made me consider tech as an alternative, as I was getting more and more interested in programming. I transitioned to tech after that event and I have been working in this field since then.”
- a 2017 workshop attendee
“I started learning web development and that launched my tech journey.” - workshop attendee in 2016, workshop coach in 2018 “I previously worked in the hospitality industry, as a bartender. I am now a software engineer!”
- a 2017 workshop attendee
How you can get involved
Attend or coach at a workshop - see the list of forthcoming workshops
Apply to organise a workshop in your city
Buy your exclusive “1010 Years Of Django Girls” t-shirt
Make a donation
0 notes
Text
Clube dos Argonautas Introdução ao processamento de línguas naturais
ADVANCED LEVEL – NÍVEL AVANÇADO JCharisTech Inovações e Inspirações Alternar barra lateral 10 de dezembro de 2018 Introdução ao Processamento de Linguagem Natural com Poliglota Processamento de linguagem natural com poliglota Neste tutorial, exploraremos outro pacote Python NLP chamado Polyglot. Polyglot é um pipeline de linguagem natural que oferece suporte a aplicativos multilíngues…

View On WordPress
0 notes
Text
A Guide To Scrape Nordstrom Fashion Product Data Using Python
A Guide To Scrape Nordstrom Fashion Product Data Using Python
Nordstrom is an American retail giant offering diverse products, including jewelry, shoes, cosmetics, clothing, fragrances, handbags, wedding furnishings, and home goods. Nordstrom's stores also feature in-house cafes, espresso bars, and restaurants, providing customers with a unique shopping experience.
Within Nordstrom, you can find the latest trends in men's, women's, and children's clothing, along with various accessories, all at competitive prices. The products are with detailed descriptions and pricing information. We specialize in providing top-notch Nordstrom Product Data Scraping Services, allowing you to extract data from Nordstrom's website efficiently.
As of 2021, Nordstrom operates 358 stores, with an average of approximately 40 stores in each U.S. state. The company's reach extends to around 90 countries and boasts a dedicated workforce of about 72,500 employees. 2018, Nordstrom held 193 trademarks, highlighting its commitment to brand excellence. As of 2020, Nordstrom's annual revenue is an impressive $10.357 billion.
Nordstrom is a prominent U.S. fashion retail industry leader, complemented by its globally renowned e-commerce platform. Due to its extensive and high-quality data offerings, Nordstrom is a coveted target for web scraping, especially within the fashion sector. The primary goal of scraping online fashion websites for product data or conducting online apparel site data scraping is to evaluate and understand the top players in the online fashion industry.
List of Data Fields
ID of Store
Number of Fields
Name of Store
Address of Store
Street
City of Store
Nordstrom State
Zip Code
Country
Phone Number
Latitude & Longitude
Open Hours of Store
URL
Product Provider
Updated Date
Stock Ticker
This tutorial will explore how to perform web scraping on Nordstrom using Python. We will delve into two key aspects:
Scraping Nordstrom product data.
Navigating and searching for products.
We will utilize well-known Python web scraping tools, namely httpx, and parsel, to achieve this. Our approach to parsing the data will involve employing hidden web data techniques.
The Benefits of Scraping Product Data from Online Fashion Sites
Business intelligence provides insights into the current market landscape, including product availability, pricing, color variations, dimensions, and additional services.
When launching a new online fashion site with a comparable range of products and features to existing fashion websites, you can:
E-commerce data scraping services conduct a comparative analysis to understand how your offerings stack up against the competition.
Identify opportunities to enhance your current offerings or introduce innovative products and services.
Perform in-depth competitor analysis to gain valuable insights into your top rivals' strategies and strengths.
You can make informed decisions and stay competitive in the ever-evolving fashion industry by leveraging business intelligence.
Significance of Scraping Nordstrom
Scraping Nordstrom fashion product data offers numerous advantages for businesses and individuals alike. Firstly, Nordstrom is a prominent player in the fashion industry, known for its vast and diverse product range, making it an invaluable data source for market research and trend analysis. Scrape Nordstrom product data to gain access to rich and up-to-date product information, including details like prices, sizes, colors, and customer reviews. This data can be leveraged for competitive analysis, helping you understand how your offerings compare to Nordstrom and other competitors in the market. Nordstrom's e-commerce platform also operates worldwide, providing a global perspective on fashion trends and consumer preferences. Whether you're a retailer looking to fine-tune your product offerings or a fashion enthusiast seeking the latest trends, Nordstrom data scraping services can provide valuable insights and data to drive informed decisions and stay ahead in the fashion industry.
Scrape Nordstrom Product Data
In this article, our primary focus will be extracting fashion websites' product data and product reviews through a specialized approach known as hidden web data scraping. Our methodology involves collecting HTML pages and subsequently extracting concealed JSON datasets, followed by their parsing with specific tools:
httpx: We will employ this robust HTTP client to retrieve the HTML pages from Nordstrom's website.
parsel: This HTML parser will be instrumental in extracting hidden JSON datasets embedded within the HTML pages.
nested-lookup: We will utilize this JSON/Dict parser to locate and retrieve specific keys within extensive JSON datasets efficiently.
jmespath: This JSON query engine will help us streamline and reduce the extracted JSON datasets to focus on crucial elements such as product prices and images.
To scrape Nordstrom fashion product data using Python, you can install all these essential packages seamlessly using Python's 'pip' console command.
To initiate the product data scraping process for a single product, we will begin by examining an example product page, such as:
nordstrom.com/s/nike-phoenix-fleece-crewneck-sweatshirt/
When extracting data through hidden web data scraping, our Nordstrom scraper will follow a structured process as outlined below:
Retrieve the HTML page of the product using the httpx library.
Locate the hidden JSON dataset within the tag using parsel and XPath.
Introduce the JSON data with json.loads() and access product-specific fields with the nested-lookup library.
We've obtained the entire product dataset from Nordstrom with just a few lines of Python code. However, this dataset can be extensive, potentially posing challenges regarding ingestion into our data pipeline for analytics or storage.
Our next step is to utilize JMESPath for data reduction, focusing on the most essential values, such as pricing, images, and variant data.
Parsing Nordstrom Data with JMESPath:
JMESPath serves as a JSON query language, and since Python dictionaries are equivalent to JSON objects, we can seamlessly incorporate JMESPath into our Nordstrom data parsing process.
While it may seem intricate, our approach involves mapping the original dataset keys to new keys using JMESPath. It allows our scraper to generate well-organized product datasets that integrate into our data pipelines.
Locating Nordstrom Products:
Now that we can efficiently scrape individual Nordstrom products, the next step is identifying the product URLs for scraping. While it's possible to input the URLs of desired products manually, we will focus on scraping product categories or conducting searches to scale up our scraper.
To accomplish this, we will continue utilizing the hidden data scraping method, as each category or search result page contains a concealed dataset with product preview information (such as price, title, image, etc.) and links to product pages.
As an illustration, let's examine one of Nordstrom's search pages:
To effectively scrape pagination on search or category pages, we'll employ a method similar to what we used for scraping product pages:
Retrieve the HTML content of the initial search or category page.
Utilize parsel and XPath to locate hidden web data.
Extract product preview data and pagination details from the hidden dataset using a nested lookup.
Calculate the total number of pages and proceed to scrape them.
With Nordstrom price monitoring, you can stay updated with real-time pricing reports from Nordstrom. Leveraging Nordstrom's data extraction capabilities, you can efficiently gather a wide range of information, including product descriptions, names, IDs, SKUs, images, options, features, and more.
We offer tailored solutions for Nordstrom data scraping, employing proprietary software designed for each customer's unique needs. Our expert Nordstrom price monitoring services cater to the specific requirements of your business.
Scraping retail website product prices provides a comprehensive list of various retail stores. Our Nordstrom web scraping services facilitate web browsing through various software programs. Many organizations are leveraging these product store price database scraping services for web research, price comparisons, and other data-related objectives, enhancing their web data collection efforts.
Know More: https://www.iwebdatascraping.com/scrape-nordstrom-fashion-product-data-using-python.php
#ScrapeNordstromFashionProductData#NordstromProductDataScrapingServices#ScrapingNordstromproductdata#Nordstromscraper#extractdatafromNordstrom#Nordstromdataextraction
1 note
·
View note
Text
"The Fast and Furious: Exploring the Rapid Growth of Python in the Programming World"
The fastest growing and the most popular programming language in today’s programming world is Python. The word time, the word "Python" evoked images of a massive snake, but today, it's synonymous with a wildly popular programming language. According to the TIOBE Index, Python holds the prestigious position of being the fourth most popular programming language globally, and its meteoric rise shows no signs of slowing.

Python’s and Growing User Base:
Several factors contribute to Python's remarkable success. First and foremost is its widespread adoption in web development. Renowned companies such as Google, Facebook, Mozilla, Quora, and many others employ Python web frameworks, elevating its prominence in this domain. Another pivotal driver behind Python's rapid growth is its pivotal role in the realm of data science.
Another factor that takes Python to the next level programming language is its easy use in Data Science. Therefore, the language is steadily growing in demand in the last ten years. In 2018, it was found in a survey that the majority of developers are obtaining training for the language and started work as Python developers. Initially, Python was built to solve the code readability issues discovered in C and Java languages.
The Reason Behind the Popularity of Pythons:
●As per the record, the reason behind the demand for python is it is easy to use. The language is pretty simple and can be easily readable. The simplicity of the language makes Python a favorite programming language among developers. Moreover, Python is an efficient language.
●Today almost all the developers and big tech giants prefer Python for web development. Some famous web frameworks can be utilized for web development project requirements.
●Even high-level Python is being trained as coursework. So that student can get prepared for the upcoming pythons’ trends and achieve success in their careers.
Python's skyrocketing popularity and its path towards becoming the world's most popular programming language are indeed remarkable phenomena.
Several Key Factors Underpin This Incredible Rise:
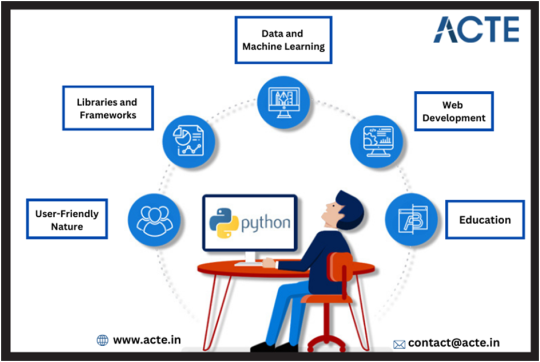
Python's User-Friendly Nature: Python stands out for its user-friendliness. Its simple, easily readable syntax appeals to both experienced developers and budding students. What's more, Python is highly efficient, allowing developers to accomplish more with fewer lines of code, making it a beloved choice.
A Supportive Python Community: Python has been around since 1990, providing ample time to foster a vibrant and supportive community. This strong support network empowers learners to expand their knowledge, contributing to Python's ever-increasing popularity. Abundant online resources, from official documentation to YouTube tutorials, make Python accessible to all.
Abundance of Libraries and Frameworks: Python's already widespread adoption has led to a wealth of libraries and frameworks developed by the community. These resources save developers time and effort, creating a virtuous cycle of popularity. Notable Python libraries include NumPy, SciPy, Django, BeautifulSoup, scikit-learn, and nltk.
Corporate Backing: Python's ascent is not solely a grassroots movement. Corporate support plays a significant role. Top companies like Google, Facebook, Mozilla, Amazon, and Quora have embraced Python for their products, with Google even offering guides and tutorials through its Python Class. This backing has been pivotal in Python's growth and success.
Python in Data and Machine Learning: Python plays a vital role in the hot trends of Big Data, Machine Learning, and Artificial Intelligence. It's widely used in research and development in these domains, and numerous Python tools like Scikit-Learn, Theano, and libraries such as Pandas and PySpark are instrumental.
Python in Web Development: Python's popularity extends to web development. It's an ideal choice for both learning and powering some of the world's most popular websites, including Spotify, Instagram, Pinterest, Mozilla, and Yelp. Python offers a range of web frameworks, from full-stack options like Django to microframeworks like Flask.
Python in Academics: The presence of Python in academic coursework is a testament to its significance. It's now a core requirement in many educational institutions, reflecting its crucial role in data science, machine learning, deep learning, and artificial intelligence. As more students learn Python, its future importance is assured.
Python's astonishing success is multifaceted and cannot be attributed to a single reason. Instead, it's the combined effect of the factors outlined above that paints a comprehensive picture of why Python has become such a pivotal and influential language in the world of programming.
If you're eager to improve your knowledge of Python, I strongly advise getting in touch with ACTE Technologies. They offer certification programs and the potential for job placements, ensuring a comprehensive learning experience. Their services are available both online and at physical locations. To commence your Python learning journey at ACTE Technologies, consider taking a methodical approach and explore the possibility of enrolling in one of their courses if it aligns with your interests.
0 notes
Text
My video tutorial on python programming language
#learning python programmin#python tutorial 2018#programming tutorial#freecodecamp#python 2019#python tutorial for beginners full#machine learning#python automation#learn programming#programming for beginners#learn python programming for beginners#python course for beginners#learn python#how to learn python for free#python basics#python course#python programming language#python programming tutorial#python from scratch#best books for learning python programming#best app for learning python programming#how to start learning python programming#benefits of learning python programming#great learning python programming quiz answers#learning python programming youtube#learning python programming book#python full course
1 note
·
View note
Text
رفع ملفاتك على GitHub باستخدام Visual Studio Code
تريد رفع ملفات مشروعك على GitHub ولكن ليس لديك مهارة الـ Command line, إليك أسهل طريقة للتعامل المباشر بين Visual Studio Code & GitHub. مشكلة عند رفع الملفات على GitHub الكثير من المبرمجين المبتدأين تواجههم صعوبة في رفع ملفات المشروع علي موقع GitHub, وكثيراً ما تحدث أخطاء في الملفات وفي مسارات المجلدات. لا أستطيع استخدام الـ Command line فإذا كنت من مستخدمي Visual Studio Code, فهناك مساحة…
View On WordPress
#git in visual studio code#github#how to install visual studio code#install visual studio code#visual studio#visual studio code#visual studio code 2018#visual studio code emmet#visual studio code extensions#visual studio code guide#visual studio code html#visual studio code json#visual studio code linux#visual studio code python#visual studio code ssh#visual studio code tutorial#visual studio code tutorial for beginners#تعلم github#رفع المشروع#رفع المشروع على github#رفع المشروع علي الجيت هاب#رفع المشروع وربطه بالgithub#رفع الموقع الاول على github وتعلم بعض اوامر ال git#رفع مشروع git#رفع ملفات البوت ع موقع github#رفع ملفات علي جيت هوب#طريقة رفع ملفات css و java على موقع github والحصول على رابط مباشر،#طريقع رفع ملفات على موقع github
0 notes
Text
11 Beginner tips for learning Python Programming
Personal recommendation: If you are looking for learning python with your mobile phone, I recommend you to download this unique ‘Programming Hero’ app and start learning as a beginner in a fun way.
Here is the download link: https://onelink.to/proghero2
Tip #1: Code Everyday
Consistency is very important when you are learning a new language. We recommend making a commitment to code every day. It may be hard to believe, but muscle memory plays a large part in programming. Committing to coding everyday will really help develop that muscle memory. Though it may seem daunting at first, consider starting small with 25 minutes everyday and working your way up from there.
Tip #2: Write It Out
As you progress on your journey as a new programmer, you may wonder if you should be taking notes. Yes, you should! In fact, research suggests that taking notes by hand is most beneficial for long-term retention. This will be especially beneficial for those working towards the goal of becoming a full-time developer, as many interviews will involve writing code on a whiteboard.
Once you start working on small projects and programs, writing by hand can also help you plan your code before you move to the computer. You can save a lot of time if you write out which functions and classes you will need, as well as how they will interact.
Tip #3: Go Interactive!
Whether you are learning about basic Python data structures (strings, lists, dictionaries, etc.) for the first time, or you are debugging an application, the interactive Python shell will be one of your best learning tools. We use it a lot on this site too!
To use the interactive Python shell (also sometimes called a “Python REPL”), first make sure Python is installed on your computer. We’ve got a step-by-step tutorial to help you do that. To activate the interactive Python shell, simply open your terminal and run python or python3 depending on your installation. You can find more specific directions here.
Now that you know how to start the shell, here are a few examples of how you can use the shell when you are learning:
Learn what operations can be performed on an element by using dir():
>>>
>>> my_string = 'I am a string'
>>> dir(my_string)
['__add__', ..., 'upper', 'zfill'] # Truncated for readability
The elements returned from dir() are all of the methods (i.e. actions) that you can apply to the element. For example:
>>>
>>> my_string.upper()
>>> 'I AM A STRING'
Notice that we called the upper() method. Can you see what it does? It makes all of the letters in the string uppercase! Learn more about these built-in methods under “Manipulating strings” in this tutorial.
Learn the type of an element:
>>>
>>> type(my_string)
>>> str
Use the built-in help system to get full documentation:
>>>
>>> help(str)
Import libraries and play with them:
>>>
>>> from datetime import datetime
>>> dir(datetime)
['__add__', ..., 'weekday', 'year'] # Truncated for readability
>>> datetime.now()
datetime.datetime(2018, 3, 14, 23, 44, 50, 851904)
Run shell commands:
>>>
>>> import os
>>> os.system('ls')
python_hw1.py python_hw2.py README.txt
Tip #4: Take Breaks
When you are learning, it is important to step away and absorb the concepts. The Pomodoro Technique is widely used and can help: you work for 25 minutes, take a short break, and then repeat the process. Taking breaks is critical to having an effective study session, particularly when you are taking in a lot of new information.
Breaks are especially important when you are debugging. If you hit a bug and can’t quite figure out what is going wrong, take a break. Step away from your computer, go for a walk, or chat with a friend.
In programming, your code must follow the rules of a language and logic exactly, so even missing a quotation mark will break everything. Fresh eyes make a big difference.
Tip #5: Become a Bug Bounty Hunter
Speaking of hitting a bug, it is inevitable once you start writing complex programs that you will run into bugs in your code. It happens to all of us! Don’t let bugs frustrate you. Instead, embrace these moments with pride and think of yourself as a bug bounty hunter.
When debugging, it is important to have a methodological approach to help you find where things are breaking down. Going through your code in the order in which it is executed and making sure each part works is a great way to do this.
Once you have an idea of where things might be breaking down, insert the following line of code into your script import pdb; pdb.set_trace() and run it. This is the Python debugger and will drop you into interactive mode. The debugger can also be run from the command line with python -m pdb <my_file.py>.
Make It Collaborative
Once things start to stick, expedite your learning through collaboration. Here are some strategies to help you get the most out of working with others.
Tip #6: Surround Yourself With Others Who Are Learning
Though coding may seem like a solitary activity, it actually works best when you work together. It is extremely important when you are learning to code in Python that you surround yourself with other people who are learning as well. This will allow you to share the tips and tricks you learn along the way.
Don’t worry if you don’t know anyone. There are plenty of ways to meet others who are passionate about learning Python! Find local events or Meetups or join PythonistaCafe, a peer-to-peer learning community for Python enthusiasts like you!
Tip #7: Teach
It is said that the best way to learn something is to teach it. This is true when you are learning Python. There are many ways to do this: whiteboarding with other Python lovers, writing blog posts explaining newly learned concepts, recording videos in which you explain something you learned, or simply talking to yourself at your computer. Each of these strategies will solidify your understanding as well as expose any gaps in your understanding.
Tip #8: Pair Program
Pair programming is a technique that involves two developers working at one workstation to complete a task. The two developers switch between being the “driver” and the “navigator.” The “driver” writes the code, while the “navigator” helps guide the problem solving and reviews the code as it is written. Switch frequently to get the benefit of both sides.
Pair programming has many benefits: it gives you a chance to not only have someone review your code, but also see how someone else might be thinking about a problem. Being exposed to multiple ideas and ways of thinking will help you in problem solving when you get back to coding on your own.
Tip #9: Ask “GOOD” Questions
People always say there is no such thing as a bad question, but when it comes to programming, it is possible to ask a question badly. When you are asking for help from someone who has little or no context on the problem you are trying to solve, its best to ask GOOD questions by following this acronym:
G: Give context on what you are trying to do, clearly describing the problem.
O: Outline the things you have already tried to fix the issue.
O: Offer your best guess as to what the problem might be. This helps the person who is helping you to not only know what you are thinking, but also know that you have done some thinking on your own.
D: Demo what is happening. Include the code, a traceback error message, and an explanation of the steps you executed that resulted in the error. This way, the person helping does not have to try to recreate the issue.
Good questions can save a lot of time. Skipping any of these steps can result in back-and-forth conversations that can cause conflict. As a beginner, you want to make sure you ask good questions so that you practice communicating your thought process, and so that people who help you will be happy to continue helping you.
Make Something
Most, if not all, Python developers you speak to will tell you that in order to learn Python, you must learn by doing. Doing exercises can only take you so far: you learn the most by building.
Tip #10: Build Something, Anything
For beginners, there are many small exercises that will really help you become confident with Python, as well as develop the muscle memory that we spoke about above. Once you have a solid grasp on basic data structures (strings, lists, dictionaries, sets), object-oriented programming, and writing classes, it’s time to start building!
What you build is not as important as how you build it. The journey of building is truly what will teach you the most. You can only learn so much from reading Real Python articles and courses. Most of your learning will come from using Python to build something. The problems you will solve will teach you a lot.
There are many lists out there with ideas for beginner Python projects. Here are some ideas to get you started:
Number guessing game
Simple calculator app
Dice roll simulator
Bitcoin Price Notification Service
Tip #11: Contribute to Open Source
If you find it difficult to come up with Python practice projects to work on, watch this video. It lays out a strategy you can use to generate thousands of project ideas whenever you feel stuck.
In the open-source model, software source code is available publicly, and anyone can collaborate. There are many Python libraries that are open-source projects and take contributions. Additionally, many companies publish open-source projects. This means you can work with code written and produced by the engineers working in these companies.
Contributing to an open-source Python project is a great way to create extremely valuable learning experiences. Let’s say you decide to submit a bug fix request: you submit a “pull request” for your fix to be patched into the code.
Next, the project managers will review your work, providing comments and suggestions. This will enable you to learn best practices for Python programming, as well as practice communicating with other developers.
1 note
·
View note
Text
Yahoo Groups Download Tools (Updated Nov, 3, 2018)
Yahoo Groups Download Tools (Updated Nov, 3, 2018)
(Please refer to back to this Google Doc for the most updated version. Events are fast moving and both tools and methods are changing.)
With a few exceptions, most of the Yahoo Groups require that you become a member.
Yahoo has 2 types of Groups:
1, Automatic Membership (anyone can click and join)
2. Moderator Approval membership. If you plan to join a Group that requires moderator approval, here are some sample messages to send to the list owner.
Always start with Yahoo
Once you have finished joining your Groups, submit a request to Yahoo/Verizon asking them to send you a download of your Group data (GetMyData). It will include messages, but none of the photos and only a few of the files. Your deadline is Dec 14, 2019 (although we recommend submitting your data request by Dec 1, 2019 to be safe).
Direct link: https://groups.yahoo.com/neo/getmydata
Free (Easy) - Mac and PC
The Chrome Message Downloader extension is a free tool that anyone can use (Mac or PC) on their Chrome browser.
Pros: free, Mac or PC
Cons: It will only download messages, not files or photos. Messages are in plain text so hyperlinks (links to other websites) and formatting will be lost
Free (Advanced) - Mac and PC
Python (link)
Pros: can download Photos, Files and Messages. Faster and more complete. Plus...Free!
Cons: The messages will not be in an immediately human-readable format (json). May be too difficult for beginners to install
Paid - PC (Easy)
PGOffline
Pros: This is the best one stop solution - it will download your files, photos, and your messages in a readable format.
Cons: a one time fee for $25. There is a free trial version that you can try. It will only download 1000 messages or files. The license process is manual - you need to send an email to the developer. He typically responds in 48hrs.
Tutorial (link) or (link)
Video: (link)
Help Others Download (Free)
You can also help the Archive Team (a non-fandom group) who have developed a Chrome plugin that will allow you to join Automatic Membership groups with a temporary Yahoo account. The Archive Team will then take it from there and will do the downloading. Note: this plugin focuses on both fandom and non-fandom groups and the files will not be sent to Open Doors. If you are backing up a fandom group for submission to Open Doors, use one of the other tools listed above.
7 notes
·
View notes
Text
Langdetect predictive analytics r language programming
LANGDETECT PREDICTIVE ANALYTICS R LANGUAGE PROGRAMMING 🎇
* Data Science* The study involving data is[ data science. It analyzes data and uses it to extract the useful information from it to develop and create methods to process the data. It deals with both structured and unstructured data. Data is a different field but involves computer science a little bit. While computer science develops algorithms to deal with the data, Data science may use computers. It mainly uses the study. Business Analytics With R or commonly known as 'R Programming Language' is an open-source programming language and a software environment designed by and for statisticians. It is basically used for statistical computations and high-end graphics.
Language line identification poster. The IBM Netezza analytics appliances combine high-capacity storage for Big Data with a massively-parallel processing platform for high-performance computing. With the addition of Revolution R Enterprise for IBM Netezza, you can use the power of the R language to build predictive models on Big Data.
youtube
Bing language detection apixaban.
Python vs. R for Developing Predictive Analytics Applications. Detect chinese language by c. R (programming language. The influence of technology on the world is constantly growing. In this new age where everything is being shifted to the online sphere, data has risen as the new currency. It has become the most important asset of every organization. Hence the uses of data mining in todays world cannot be undermined or understated. Data mining seems like magic to most people. Ext.
Changed: 2019-12-04T03:47:27. Unicode language identification. Exploring Cognitive Relations Between Prediction in Language and Music. Title: Subword Level Language Identification for Intra Word Code Switching. Publish Graduate Diploma In Predictive Analytics. Risk Prevention Data Scientist Volunteer Forest Fire Prevention Derivatives, CrowdDoing, M4A FOUNDAT.
Identifying Language Origin of Named Entity With Multiple Information Sources. NLP: Simple language detection in Python. Settings google language detection. Top 10 Programming Languages For Data Scientists to Learn In 2018. Php script language detection and translation. SQL Server R language tutorials. 12/18/2018; 2 minutes to read +4; In this article. APPLIES TO: SQL Server Azure SQL Database Azure Synapse Analytics (SQL DW) Parallel Data Warehouse This article describes the R language tutorials for in-database analytics on SQL Server 2016 R Services or SQL Server Machine Learning Services.
Risk Prevention Data Scientist Volunteer Forest Fire Prevention Derivatives, CrowdDoing, See more detailed background on CrowdDoing's forest fire prevention derivatives _HUr-tCCNaeGoSDfPrirRPbaoV3X4/view?usp=sharing Risk Prevention Data Scientist Volunteer Forest Fire Prevention Derivatives, CrowdDoing, Bobby Fishkin, lead author In 2018, Sacramento was named the "the Most Polluted City on Earth" due to "smoke from Camp Fire, This proposal aims to prevent.
mevasokick.simpsite.nl/
http://vascviwhegor.tripod.com
http://mancadenwe.parsiblog.com/Posts/5/Detect+Language+Python+Language+Langdetect/
rauguescanap.blogg.se/2019/december/php-language-detection-stringent-langdetect.html
u/cardsixohua/blog/LangdetectRLanguagePredictFunctionInR/
https://everplaces.com/roalinjicom/places/573e76f03f314beb8b83bf3a7c59d0c7/
1 note
·
View note
Text
Tutorial - Week 7
Preparation Work
In preparation for this tutorial, we were supposed to start thinking about answers to the following question:
Should the government or government agencies collect and have access to your data for good purposes, or should citizens, .e.g you, have a right to privacy which stops them?
Personally, I think there needs to be a compromise on this issue; no level of identification would prevent many government systems from being able to run and would be a detriment to public safety. However too much surveillance becomes invasive and purely unnecessary - there becomes a point at which you know so much that it can be used as a means for control.

The funny thing about all these supplied articles is that I had pretty much read them all when they came out anyway, as I’m already pretty privacy-oriented. However I will summarise the events and some of my thoughts on them:
2019 - Facial recognition to replace Opal cards (link)
Discussed in a previous article (here) on biometrics
Basically use your face to represent your identity and charge you
2019 - AFR facial recognition (link)
Goes through the numerous benefits of biometrics including missing people, security, crime and ‘smart cities’
Highlights the significant potential for abuse - mass surveillance & privacy, identity theft, etc
2019 - Australians accept government surveillance (link)
Demonstrates how citizens are ‘on the fence’ regarding the benefits vs dangers of increasing levels of government surveillance (note the survey was only 100 people)
Any further surveillance measures will probably result in people taking steps to protect their privacy more
2018 - NSW intensifies citizen tracking (link)
NSW policie and crime agencies to use the “National Facial Biometric Matching Capability"
System contains passport photos, drivers licenses
Government claims there will be restraint in their usage (with regards to certain crimes) and stated the benefits to public safety and prevention of identity theft
2017 - Benefits of Surveillance (from ‘intelligence officials) (link)
Discusses the issue of ‘proportionality’ in surveillance - the ratio between the total data collected and the actual usage of this data by intelligence agencies
Two main types of intelligence - tactical which is targeted at certain individuals, where as strategic is more targeted at information dominance (gathering as much as possible)
Hard to assess effectiveness of surveillance programs - agencies often ‘cherry pick’ figures that support their arguments
Surveillance differences between citizens and foreigners - a distinction exists in the US on the permissible levels of surveillance due to their constitutional rights
2015 - Australian Metadata retention (link)
I remember this one at the time; George Brandis (the attorney general at the time) made an absolute mockery of explaining this one
Basically legislating the storage of the details of the endpoints of every internet and phone communication
Even though you don’t know the contents of a communication necessarily, you can still extract a lot of data from this information alone
Main concerns relating to who would be able to access this information and how can the government secure it
2013 - Need for government surveillance (link)
Basically justifying the need for extended surveillance of citizens due to “new threat” of “home-grown” terror
With all these articles, I sort of understand the need for governments to update their surveillance capabilities with regards to the new technology available. However, I think there should be restrictions in place regarding this and constant transparent assessment of their effectiveness regarding the claims they make for their ‘necessity’.
Tutorial
I think Jazz was right in saying how ‘cooked’ we all were in the week 7 tutorial; honestly I can barely remember what even happened. I remember him going through and cracking the ‘blind’ buffer overflow challenge which was pretty cool. Basically he did a dump of the assembly code and searched for the win function; this was so we could get the address.
Then we could feed in a long string using cyclic (such that every 4 bytes is unique) which would cause a segmentation fault. This is because it is attempting to jump to an invalid (or not permitted) address; the fault message will display the address it faulted on which we can convert back to a set of 4 characters. This will give us the index in the string that the return address occurs at - we can then just dump the address of the win function we found earlier. Now hopefully in an exam the buffer wouldn’t be too far from the return address, however if it is it might be worth learning up how to write a quick program in Python to calculate the De Bruijn sequence for a set of characters!
We also went through some of the questions from the exam. I got the opportunity to go through and explain to the class how to determine the key length in question 12 of the mid-sem. You basically use a technique known as ‘Kasiski examination’; this involves searching for repeated phrases in the ciphertext and counting the distance between them. Then you are able to determine that the key word length must be a factor of this distance. If you repeat it enough times (in particular I was looking at the ‘GAD’ and ‘GAZ’ phrases in the text) you are able to ascertain that the keyword length must be 6. (3 was technically possible, but just ‘more unlikely’)
There were some other interesting on-the-spot talks in class regarding security. Someone discussed how you can intercept all the packets on a network with an appropriate network adapter (or if you can get your card in ‘monitor mode’); (I think @comp6841lanceyoung) some of the implications from this are interesting. Another person gave a brief overview of how we can interpret an image to train an AI to break CAPTCHAs (@raymondsecurityadventures). The final one (@azuldemontana) gave a quite funny analogy of how eating Heinz Fiery Mexicans Beans for lunch is basically the same as using open-source software - you would only eat things that you know the ingredients, so why do we use closed source so much if we don’t know whats happening?
We sorta got distracted with so many other random security things we didn’t actually leave that much time for the actual case study. Basically what we did was brainstorm all the pieces of data we might consider are connected to our identity: name, address, phone no., social security, tax number, browsing history, message & call logs, location history, relationship history, etc. Then we went through each of them and debated as a class whether or not we thought the government should be allowed to collect and store this information.
I actually found it quite funny that people were arguing against the government having something basic like an address. There generally always comes a point in our lives where things outside our control happen that require government intervention and not knowing where you live makes it quite difficult for them to inform you or provide assistance. It might be about letting you know about changes to legislation, local building works, death of a loved one; not necessarily just about chasing up a crime.
I think that the major issue that civilians have against the government collecting this data boils down to two main issues. The first is misuse - that is, from the data being easily accessible across all government agencies without much evidence of a crime being committed. It also encompasses our mistrust in the government being able to store this data securely - if the data was leaked it may be used for identity theft, blackmail, etc and could haunt you for years. The second problem closely links to this and is the retention period - how long is it really necessary for them to keep this data for law enforcement purposes? You have to remember the longer it is kept the more prone it may be to misuse (i.e. hacked); I personally think a shorter retention period would probably make people less concerned.
2 notes
·
View notes
Text
Julia's Vector
Sorry, no robot news. I've been struggling to find the time, and frankly can't face the motor calibration phase. Also, I promised to give a lunchtime talk at work which needs preparation. I decided to give the talk about Julia because, since I last blogged about Julia, it has passed the version 1.0 mark and the creators have won a top numerical computing prize.
While revising for the talk I reread the documentation and unearthed stuff I had either forgotten or was brand new. One of the newer features was vectorization. This can mean various things, but here we're talking about efficient in-language support for processing arrays of data.
Other languages like R, and Python packages like NumPy, need vectorization because they are interpreted languages. Every bit of Python code you write makes your program slower than the equivalent C program. Python is most efficient when you are just invoking natively implemented routines or libraries.
Hence NumPy extends Python with facilities for efficient numeric operations on arrays of data. This lets you ask for functions to be applied across the data and allows you to get out of the interpreted Python code as soon as you can.
Julia doesn't particularly need to do this since it is compiled to native code, but does still provide some neat vectorization facilities. This is because they do sometimes make the code faster (because someone has hand-optimised them), and also they can make the code simpler and easier to read.
Let's start with some data:
x = [1.0, 2.0, 3.0, 4.0]
Suppose you wanted to square every element of the data. You could write a loop and collect the result:
function square_all(x) [e * e for e in x] end square_all(x)
Which returns:
4-element Array{Float64,1}: 1.0 4.0 9.0 16.0
However, it would be simpler if you could define a function and simply apply it to every element:
function square(e) e*e end map(square, x)
This is fine, but what if there was a natural way of saying a function should be applied to each element rather than the whole data structure? Julia uses an extra dot (".") during function application for this, as follows:
square.(x)
The above creates a new array with the function "square" applied to each element of "x". Technically, rather than using "map" this is equivalent to:
broadcast(square, x)
If you were to write the function application "square.(x)" without the dot you would get a compilation error because there is no method "*" that applies to two arrays of floating point numbers (well, by default anyway).
Conveniently, Julia's vectorization syntax is allowed even for built-in operators like "+".
x .+ 1 x .* 2
And the following works as you'd expect:
x .* 2 .+ 1
But isn't this inefficient compared to the alternative using "map" (using Julia's shorthand for "2*e")?
map(e -> 2e + 1, x)
Doesn't the vectorized version have to allocate intermediate arrays? Actually not. Julia "fuses" the layers of vectorized operations so they are a single loop.
Even so, the dots are becoming somewhat ugly. Fortunately, Julia lets us say the whole expression is vectorized using a macro called "@.":
@. 2x + 1
We can find out what this expands into using the "@macroexpand" macro:
@macroexpand @. 2x + 1
Which returns:
:((+).((*).(x, 2), 1))
So notionally it first applies "*." then "+.". The "@." macro also works for user-defined functions.
@. square(2x + 1)
Vectorization even works for assignment. The following does stepwise assignment into the new copy of the array.
y = copy(x) @. y = square(2x + 1)
Finally, Julia has method pipelining (like some other functional languages) using the "|>" operator:
x |> sum
Which is the same as:
sum(x)
And "|>" also supports vectorization:
@. x |> square
That concludes a quick tutorial on Julia vectorization. You will have to judge whether individual uses improve readability or not. It is easy to get carried away. For more details see "More Dots: Syntactic Loop Fusion in Julia".
So will Julia ultimately win significant mind-share among programmers and data scientists? Who knows, but that's its current vector!
“Julia is increasingly the language of instruction for scientific computing at MIT.” -- Prof Alan Edelman
1 note
·
View note
Text
Something awesome: progress update
Feeling sleepy...

From the time of my last blogpost, till now (11:15pm) I’ve been working on writing the first chapter of my how-to-guide which mainly covers an introduction to programming for beginner students. I’ve also included the writeups to picoCTF challenges which I have previously completed for the appropriate module
I’ve written about 1.5k words, which for those who are interested can be read below.
Before we begin…
Introduction to programming
A key skill to learn before we dive head-first into the other concepts covered in this guide, we should probably first learn about our environment!
For those who think ‘airport’ when they hear the word terminal or ‘snail’ when they hear the word shell, you should definitely read this part before getting started with any of the other modules. For those who are already quite confident with navigating their way through the Linux environment, feel free to skip ahead!
Let’s start with a quick summary of some of the key things you should know:
What is a terminal?
The terminal is the main way that we, as users, interact with the computer. It normally looks like a black screen with white font. To uss the terminal, you type in specific commands which the computer interprets in order to run certain operations.
Of course, in order to use the terminal you have to know the commands!
Some basic terminal commands:
I like to compare using the terminal like using a normal file explorer. We double-click
folders (also called directories) to enter them, and double-clicking files opens them. We can create new folders, new files by right-clicking then pressing the appropriate button. All of this can be done through the terminal - you just have to know the right commands.
cd - stands for ‘change directory’. This command is used like ‘cd <name-of-directory>’ in order to change into the specified directory
If you just type in cd or ‘cd ~’ you should change to your home directory
You can use ‘cd ..’ to change into the previous directory you were in
pwd - stands for ‘print working directory’
ls - used to list all the files in your current directory.
mkdir - stands for ‘make directory’. Basically is the equivalent of the ‘new folder’ button in a normal file explorer. You can use it like ‘mkdir <name-of-directory>’ to make a folder with the specified name.
./ - this little ‘./’ is very powerful! If we have executable files or files that we can’t normally open, we can run them by doing ‘./<name-of-executable>’
man - stands for ‘manual’. Think about this as your help guide for any command you want to learn more about. Use it by typing in ‘man <name-of-command>’.
Other useful commands:
rm - stands for ‘remove’. Used like ‘rm <name-of-file-to-be-removed>’
whoami - displays information about the user
cat - one of cat’s applications is to view the contents of a file without actually having to open it. Use it like ‘cat <name-of-file>’ to have the contents of the specified file be displayed in the terminal
strings - strings basically finds printable strings or sentences in an object, or other binary files. Use it like ‘strings <name-of-file>’.
grep - grep is a way for us to find the existence of certain patterns or words in a file. You can use it like ‘grep <word/pattern> <name-of-file>’ to return every instance of the word/pattern in the specified file
nc - nc or netcat is a tool that can help you read or write data over the internet. It has a lot of uses, but for the context of picoCTF we’ll mainly be using to access the challenges. Use it like ‘nc <destination> <port>’. An example of how we could use it for picoCTF is detailed below
ssh - basically a way for us to safely access remote servers. Use it like ‘ssh <user>@<host>’, where <user> refers to the account you want to access and <host> is the domain or IP address of the computer you are trying to access.
You can find more info about SSH here: https://www.hostinger.com/tutorials/ssh-tutorial-how-does-ssh-work
A more comprehensive guide containing explanations about a wider variety of commands can be found here.
What is a programming language?
So sure, we’ve learnt how to make our way through a terminal, but what about code? How do we write and run it? In terms of writing code, there are many varied programming languages, each with their own rules and different features that we can use. For readers who’ve never coded before in their life, now would be a fantastic time to learn one!
A lot of the concepts are common in programming languages, so it doesn’t particularly matter which one you start with. However, I would definitely recommend Python, as it is quite user-friendly. This is a great place to start learning.
What is a text editor?
To summarise quickly, basically we write programs saved in a certain type of file based on what language they are written. These files can be changed and edited using what are called text editors. There are many different ones- some are inherent to your terminal like ‘vim’ or ‘nano’ and are quite simplistic. Others you can download online and include cool features like autocompleting variable names and structuring your code for you.
Whatever text editor you choose to use is completely based on your preferences! Use whatever is comfortable for you and supports your writing of code
How do we run code?
Now that you’ve written your first program in a text editor, in your chosen programming language what do we actually do with it? Some programming languages like C or Java need to have their files be ‘compiled’ before we can actually run them. This basically means translating the code we write into a form that the computer can interpret. Other languages like Python don’t require this extra step, and can be run easily.
picoCTF writeups - Hideout:
This chapter’s challenges can all be found under the ‘hideout’ module in the 2018 picoCTF. The below examples detail some of the ways we can apply what has been described above.
net cat
Using netcat (nc) will be a necessity throughout your adventure. Can you connect to 2018shell.picoctf.com at port 49387 to get the flag?
As we described above, we can use nc like ‘nc <destination> <port>’. Hence, we simply do ‘nc 2018shell.pico.ctf.com 49387’ to connect to the remote service. The flag should be displayed on your terminal which is: picoCTF{NEtcat_iS_a_NEcESSiTy_8b6a1fbc}
grep 1
Can you find the flag in file [1] ? This would be really obnoxious to look through by hand, see if you can find a faster way. You can also find the file in /problems/grep-1_4_0431431e36a950543a85426d0299343e on the shell server.
Although you could just look the whole file to manually find the flag, we can use one of the handy commands we learnt about earlier! As described in the above guide, we can use grep like ‘grep <word/pattern> <name-of-file>’. We can utilise the fact that every flag inpicoCTF is formatted in the same way, by doing ‘grep picoCTF file’ to retrieve our flag which is: picoCTF{grep_and_you_will_find_cdf2e7c2}
sshkeyz
As nice as it is to use our webshell, sometimes its helpful to connect directly to our machine. To do so, please add your own public key to ~/.ssh/authorized_keys, using the webshell. The flag is in the ssh banner which will be displayed when you login remotely with ssh to with your username.
You can connect to the picoCTF server by doing ‘ssh <username>@2018shell1.picoctf.com’ in your terminal. The output should look somewhat similar to below:
$ ssh [email protected]
The authenticity of host '2018shell1.picoctf.com (18.223.208.176)' can't be established.
ECDSA key fingerprint is SHA256:zCX5ip3tx1RMbsJBc70jEazd+gAFzlbC1Q2iDI8LA/k.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '2018shell1.picoctf.com,18.223.208.176' (ECDSA) to the list of known hosts.
picoCTF{who_n33ds_p4ssw0rds_38dj21}
Thus we can see our flag, which is: picoCTF{who_n33ds_p4ssw0rds_38dj21}
strings
Can you find the flag in this file [1] without actually running it? You can also find the file in /problems/strings_0_bf57524acf558aca2081eb97ece8e2ee on the shell server.
As we detailed above, we can use string like ‘strings <name-of-file>’. To get all the printable lines in the ‘strings’ file we can use the strings command, together with grep to get the flag! By doing ‘strings strings | grep picoCTF’ we retrieve our flag which is: picoCTF{sTrIngS_sAVeS_Time_3f712a28}
what base is this
To be successful on your mission, you must be able to read data represented in different ways, such as hexadecimal or binary. Can you get the flag from this program to prove you are ready? Connect with nc 2018shell.picoctf.com 15853.
Basically this challenge wants us to convert between different bases of numbers. It requires you to:
Convert from binary to ASCII
Convert from hex to ASCII
Convert from octal to ASCII
I used the following tools to complete the challenge:
https://www.rapidtables.com/convert/number/binary-to-ascii.html
https://www.rapidtables.com/convert/number/ascii-hex-bin-dec-converter.html
http://www.unit-conversion.info/texttools/octal/
1 note
·
View note
Link
Create a powerful and great website using the Flask framework for Python
1 note
·
View note
Text
#programming #learning python programmin, #python tutorial 2018, #programming tutorial, #freecodecamp, #python 2019, #python tutorial for beginners full, #machine learning, #python automation, #learn programming, #programming for beginners, #learn python programming for beginners,#python course for beginners, #learn python, #how to learn python for free, #python basics, #python course, #python programming language, #python programming tutorial, #python from scratch, #best books for learning python programming, #best app for learning python programming, #how to start learning python programming, #benefits of learning python programming, #great learning python programming quiz answers, #learning python programming youtube, #learning python programming book, #python basics, #how to learn python for free, #learn python, #python programming language, #python programming tutorial, #best books for learning python programming, #python from scratch, #python full course, best books for learning python programming, #how to start learning python programming, #best app for learning python programming, #benefits of learning python programming, #great learning python programming quiz answers, #learning python programming youtube
1 note
·
View note