#Complex Data Processing
Text

In an increasingly interconnected world, technology constantly evolves to meet the demands of users seeking faster. The installation of 5G technology is one such advancement that has received widespread attention. Get help from the best Mobile App Development Company in Coimbatore & Chennai or in your locations to the finest service. Trioticz is the best mobile app development company, Website Development Company in Coimbatore, and Digital Marketing Agency in Chennai feel free to contact us for further information.
#Augmented reality#Complex Data Processing#Content Delivery#Digital Marketing Agency in Chennai#Digital Marketing Company in Coimbatore#Edge Computing#Fast Speed#Internet Of Things#IOT Integration#Mobile App Development#Mobile App Development Company in Coimbatore & Chennai#Reduced Latency#Virtual Reality
0 notes
Text
i drew these Data and Lore sketches for a project and i thought they looked really nice so here you go :)


+ some bonus wip photos





i love Lore's cheeky shit-eating smirk in that second-to-last wip lmaooo
#star trek#star trek tng#star trek the next generation#data soong#lore soong#data star trek#lore star trek#datalore#star trek fanart#star trek art#sketch#i feel like i could have fixed up lore's nose so it looks more exact to data's but i really like how these turned out :D#also i'm usually not very good at drawing characters facing to the left so i'm surprised lore turned out looking really nice!!#idk why i struggle to draw them facing to the left for.... i mean i know i'm used to drawing them facing right but all i gotta do is flip-#-the process i usually do to the other way so why is it so tricky for me............#anyway i love drawing the soong brothers' big ol noses#their side profiles are so beautiful i love them so much <3#i find drawing star trek characters to be really fun and i should really draw them more!!#it's a fun challenge and there's so many complex shapes and lines to memorise and draw up guidelines for#i might post a thingy on how i usually draw faces but i also feel like the wips here do a pretty good job at displaying my process#the loomis method of drawing heads is a godsend it's so helpful#loomis method my beloved <3#anyway yeah i love drawing my beautiful little androids :D
24 notes
·
View notes
Note
at the risk of sounding insane,,, would you mind sharing more about how you gathered your good omens fanfic data. I am similarly curious about rwrb’s firstprince pre/post the movie release this year, bc I think I have noticed trends that were popular but would like some evidence that isn’t anecdotal
Yes of course, no gatekeeping in this household!! So the key is to get really good at using ao3's filtering system and then the rest is easy as pie.
(if this seems oversimplified, it's because my brain doesn't really process what level of complexity to start at and it just makes sense to say everything. I've been told I sound demeaning before. I promise I'm not.)
Step one: Open your fandom page, making sure you're starting out with no other filters on it so you get the best data possible.
Step two: Make a spreadsheet. This is the easiest way to make sure all your numbers stay where you want them to, and it will auto-generate your graphs for you if you organize it well. This is what my fic ratings sheet looks like; the bottom row is an automatic sum of each column, so I can make sure it matches the total showing on ao3.

Step three: Get to scraping. I do all of mine by hand because it's my happy place, so if you're wanting a code that will do it for you then I'm sorry I can't offer that. You can filter by lots of things, depending on what you want to know. This is what a pull looks like for all fics under the good omens tag, with the data organized for ratings and the top ten most popular tags displayed as well.
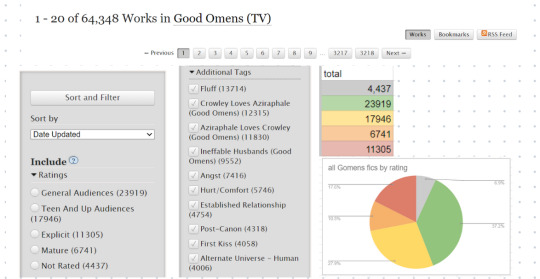
For more complex data, such as to pull by date, you just filter further. For example, all fics from 2020 would look like this:

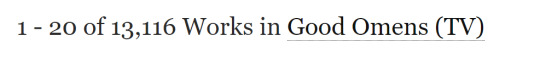
^that's the number you want to write down for the total. Here, that's 13,116 works published (updated) in the year 2020. If I want to see how many fics tagged "angst" were published in 2020, then I'll leave the date filter on and add the angst filter as well:

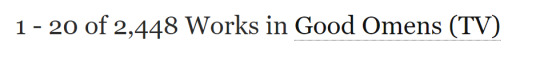
Which gives us 2,448 works published in 2020 under the angst tag. You can also do this the way you would filter for any tag, as well as exclude tags, when looking for fics. You can filter by relationship type, different ships, crossovers, archive warnings, as well as any tag you can think of.
At the top of the filter bar you can have it sort by different benchmarks of popularity, if you're trying to get a feel for what's actually being read, or by wordcount, both of which I find very useful. You can also filter by wordcount, under "More Options," to remove for example any work under 50 words (removes podfics and solely art posts).
Step four: Share your work! I recommend finding a video explaining the basics of your spreadsheet platform and learning to make simple calculation cells and graphs, and then I also use canva and sometimes other online graph makers to give it a little pizzazz when I feel like it needs something snappier. Be aware that ao3 is a constantly evolving site so data can only be accurate to a certain degree, but since we're not sending a ship to the moon on these numbers it's not enough to throw off the statistical significance of your findings. And please, tag me when you do! I'd love to see what you come up with:)
#this is just my personal method guys don't come for me if you don't like it#but yeah#it takes hours sometimes to filter everything and copy it down bit by bit when I'm working on more complex data but I find the process fun#good luck!!!
7 notes
·
View notes
Text
Watched a video about these "AI assistants" that Meta has launched with celebrity faces (Kendall Jenner, Snoop Dogg etc.). Somebody speculated/mentioned in the comments that eventually Meta wants to sell assistant apps to companies, but that makes ... no sense.
If they mean in the sense of a glorified search engine that gives you subtly wrong answers half the time and can't do math, sure - not that that's any different than the stuff that already exists (????)
But if they literally mean assistant, that's complete bogus. The bulk of an assistant's job is organizing things - getting stuff purchased, herding a bunch of hard-to-reach people into the same meeting, booking flights and rides, following up on important conversations. Yes, for some of these there's already an app that has automated the process to a degree. But if these processes were sufficiently automated, companies would already have phased out assistant positions. Sticking a well-read chat bot on top of Siri won't solve this.
If I ask my assistant to get me the best flight to New York, I don't want it to succeed 80 % of time and the rest of the time, book me a flight at 2 a.m. or send me to New York, Florida or put me on a flight that's 8 hours longer than necessary. And yes, you can probably optimize an app + chat bot for this specific task so it only fails 2 % of the time.
But you cannot optimize a program to be good at everything–booking flights, booking car rentals, organizing catering, welcoming people at the front desk and basically any other request a human could think off. What you're looking for is a human brain and body.
Humans can improvise, prioritize, make decisions, and, very importantly, interact freely with the material world. Developing a sufficiently advanced assistant is a pipe dream.
#now i understand that part of it might just be another round of hype to avoid shares dropping because it looks worse to write 'we got some#videos of kendall jenner and hope to make money off of it someday'#funnily enough no matter what complexity these assistant apps reach#it will be human assistants who use them#because the crux of having an assistant is that you DON'T have to deal with the nitty-gritty (like did the app understand my request) or#follow-up#meta#ai#post#ai assistant#the other thing to consider is when you let an app interact with a service for you that concerns spending money (like booking a flight but#really anything where money will be spent in the process) you lose power as a consumer#because you will hand over data about what you want and have to deal with the intransparency of the service#are you getting suggested the best/fastest/cheapest flight or the one from the airline that has a contract with your assistant app?#we are already seeing this with the enshittification of uber or other food or ride share apps#the company has the power to manipulate consumers and 'contractors' alike because they program the app
10 notes
·
View notes
Text
AI in Finance: How Palmyra-Fin is Redefining Market Analysis
New Post has been published on https://thedigitalinsider.com/ai-in-finance-how-palmyra-fin-is-redefining-market-analysis/
AI in Finance: How Palmyra-Fin is Redefining Market Analysis
Artificial Intelligence (AI) is transforming industries worldwide and introducing new levels of innovation and efficiency. AI has become a powerful tool in finance that brings new approaches to market analysis, risk management, and decision-making. The financial market, known for its complexity and rapid changes, greatly benefits from AI’s capability to process vast amounts of data and provide clear, actionable insights.
Palmyra-Fin, a domain-specific Large Language Model (LLM), can potentially lead this transformation. Unlike traditional tools, Palmyra-Fin employs advanced AI technologies to redefine market analysis. It is specifically designed for the financial sector to offer helpful features to professionals in today’s complex markets with exceptional accuracy and speed demands. Palmyra-Fin’s capabilities set a new standard in an era where data drives decision-making. Its real-time trend analysis, investment evaluations, risk assessments, and automation features empower financial professionals to make informed choices efficiently.
The Evolution of AI in Financial Market Analysis
Initially, AI applications in finance were limited to basic rule-based systems designed to automate routine tasks, such as data entry and basic risk assessments. While these systems streamlined processes, they were restricted due to their inability to learn or adapt over time. These systems were highly dependent on predefined rules, lacking the capabilities to manage complex and dynamic market scenarios.
The emergence of machine learning and Natural Language Processing (NLP) in the 1990s led to a pivotal shift in AI. Financial institutions began using these technologies to develop more dynamic models capable of analyzing large datasets and discovering patterns that human analysts might miss. This transition from static, rule-based systems to adaptive, learning-based models opened new opportunities for market analysis.
Key milestones in this evolution include the advent of algorithmic trading in the late 1980s and early 1990s, where simple algorithms automated trades based on set criteria. By the early 2000s, more sophisticated machine learning models could analyze historical market data to forecast future trends.
Over the past ten years, AI has become a reality in financial analysis. With faster computers, tons of data, and more intelligent algorithms, platforms like Palmyra-Fin now give us real-time insights and predictions. These tools go beyond conventional methods to help us better understand market trends.
Palmyra-Fin and Real-Time Market Insights
Palmyra-Fin is a domain-specific LLM specifically built for financial market analysis. It outperforms comparable models like GPT-4, PaLM 2, and Claude 3.5 Sonnet in the financial domain. Its specialization makes it uniquely adept at powering AI workflows in an industry known for strict regulation and compliance standards. Palmyra-Fin integrates multiple advanced AI technologies, including machine learning, NLP, and deep learning algorithms. This combination allows the platform to process vast amounts of data from various sources, such as market feeds, financial reports, news articles, and social media.
A key feature of Palmyra-Fin is its ability to perform real-time market analysis. Unlike conventional tools that rely on historical data, Palmyra-Fin uses live data feeds to provide up-to-the-minute insights. This capability enables it to detect market shifts and trends as they happen, giving users a significant advantage in fast-paced markets. Additionally, Palmyra-Fin employs advanced NLP techniques to analyze text data from news articles and financial documents. This sentiment analysis helps gauge the market mood, essential for forecasting short-term market movements.
Palmyra-Fin offers a unique approach to market analysis that uses advanced AI technologies. The platform’s machine learning models learn from large datasets, identifying patterns and trends that might take time to become apparent. For example, Palmyra-Fin can detect links between geopolitical events and stock prices and can thus help professionals stay informed in rapidly evolving markets. Deep learning further enhances its predictive capabilities, processing large amounts of data to deliver real-time forecasts.
Palmyra-Fin’s effectiveness is demonstrated through strong benchmarks and performance metrics. It reduces prediction errors more effectively than traditional models. With its speed and real-time data processing, Palmyra-Fin offers immediate insights and recommendations.
Real-World Use Cases in the Financial Sector
Palmyra-Fin is highly versatile in finance and has several key applications. It excels in trend analysis and forecasting by analyzing large datasets to predict market movements. Presumably, Hedge funds could use Palmyra-Fin to adjust strategies based on real-time market shifts, enabling quick decisions like reallocating assets or hedging risks.
Investment analysis is another area where Palmyra-Fin may be suitable. It provides detailed evaluations of companies and industries essential for strategic decisions. Investment banks can use it to assess potential acquisitions and perform a thorough risk assessment based on financial data and market conditions.
Palmyra-Fin also specializes in risk evaluation. It assesses risks associated with different financial instruments and strategies, considering quantitative data and market sentiment. Wealth management firms use it to evaluate portfolios, identify high-risk investments, and suggest adjustments to meet clients’ goals.
The platform is also effective for asset allocation, recommending investment mixes tailored to individual risk preferences. Financial advisors can use Palmyra-Fin to create personalized plans that balance risk and return.
Additionally, Palmyra-Fin automates financial reporting, helping companies streamline report preparation and ensure compliance with regulations. This reduces manual effort and improves efficiency. Leading firms like Vanguard and Franklin Templeton have integrated Palmyra-Fin into their processes, showcasing its effectiveness in the financial industry.
Future Prospects and Potential Advancements for Palmyra-Fin
The future of AI-driven financial analysis appears promising, with Palmyra-Fin expected to play a significant role. As AI technology advances, Palmyra-Fin will likely integrate more advanced models, further enhancing its predictive capabilities and expanding its applications. Future developments may include more personalized investment strategies tailored to individual investor profiles and advanced risk management tools providing deeper insights into market risks.
Emerging trends in AI, such as reinforcement learning and explainable AI, could further boost Palmyra-Fin’s abilities. Reinforcement learning could help the platform learn from its own decisions, continuously improving over time. Explainable AI, on the other hand, may provide more transparency in the decision-making processes of AI models and can thus help users understand and trust the insights generated.
In the future, AI will change how financial analysis works. Tools like Palmyra-Fin can perform tasks that humans used to do. This also means new job opportunities for people who understand AI. Financial professionals who learn to use these tools will be ready for the changing industry.
The Bottom Line
In conclusion, Palmyra-Fin is redefining financial market analysis with its advanced AI capabilities. As a domain-specific large language model, it provides unparalleled insights through real-time data analysis, trend forecasting, risk evaluation, and automated reporting. Its specialized focus on the financial sector ensures that professionals can make informed, timely decisions in an ever-changing market landscape.
With ongoing advancements in AI, Palmyra-Fin has the potential to become an even more powerful tool and can lead to more innovation and efficiency in finance. By embracing AI technologies like Palmyra-Fin, financial institutions can stay competitive and confidently handle the complexities of the future.
#1980s#acquisitions#ai#AI in finance#AI models#Algorithms#Analysis#applications#approach#Articles#artificial#Artificial Intelligence#artificial intelligence in finance#assessment#assets#automation#banks#benchmarks#change#claude#claude 3#claude 3.5#Claude 3.5 Sonnet#Companies#complexity#compliance#computers#data#data analysis#data processing
0 notes
Text
AI Capabilities Today: What Machines Can and Can't Do in 2024
Introduction
As someone who loves technology, I have been amazed by how artificial intelligence (AI) has grown. I remember chatting with a computer program that wanted to talk to a person – it was like being in a sci-fi movie! Today, AI is everywhere, from helpers on our phones to the systems that show us what to see on social media. It is important to know what these systems can and cannot do.…

View On WordPress
#AI and data analysis#AI capabilities#AI complex problem solving#AI emotional intelligence#AI ethical concerns#AI in 2024#AI in everyday life#AI limitations#AI natural language processing#artificial intelligence advancements#autonomous AI systems#creative AI applications#future of AI#what AI can do
0 notes
Video
youtube
AI: How Deep Learning is Changing the World
AI: Revolutionizing Industries with Deep Learning
AI: How Deep Learning Transforms Various Sectors
AI: How Deep Learning is Changing the World
In this video, you will learn how deep learning, a subset of artificial intelligence, has enhanced AI’s capabilities to understand complex patterns and make accurate predictions. You will see how deep learning has led to breakthroughs in natural language processing, computer vision, and more.
You will also discover how AI is being applied across various industries, revolutionizing processes and decision making. You will see examples of how AI can help diagnose diseases, recommend treatment, and monitor patients in healthcare.
If you want to learn more about how AI and deep learning are transforming the world, watch this video and subscribe to our channel. Don’t forget to hit the like button and share your thoughts in the comments section.
#breakthroughs , #accurate-predictions , #decision-making , #deep-learning , #finance , #diagnose-diseases , #detect-fraud , #process , #getmunch , #moresubscribers2024 , #moreviews2024 , #growyourchannel , #vidIQ
"Deep learning has revolutionized AI, enabling it to process complex data and make accurate predictions in areas like healthcare and finance. #AI #DeepLearning #Revolution" #getmunch
Links: Troupe Enterprises Inc.: Home - Troupe Enterprises Inc. (troupeenterpriseinc.com)
Book a Free 15 Min call https://troupeenterpriseinc.com/book-online
Book Online - Troupe Enterprises Inc. (troupeenterpriseinc.com)
Podia Course:Startup Pioneer's (podia.com)
Teachable Course
WordPress Blog:
All About Nuance – I make How to/Tutorials videos about business systems, mindset, and self-publishing. Helping others build their dream businesses and teaching about the Pitfalls of entrepreneurship. Because I believe I can save you time, money stress, and Aggravation on your entrepreneurial journey. (wordpress.com)
https://allaboutnuance.wordpress.com/2023/12/09/unlock-your-financial-freedom-monetize-your-mind/
Facebook: https://www.facebook.com/TroupeEnterprisesInc?mibextid=ZbWKwL
Instagram:
https://instagram.com/troupeenterprises2023?igshid=MzMyNGUyNmU2YQ==
Ticktok:
@systemslt
Twitter/X:
@troupeenterprises2023
Linkedin:
https://www.linkedin.com/company/troupe-enterprises-inc/
You can purchase them on Amazon at the 6 links also.
Creating your own light:
https://www.amazon.com/dp/B09SFMKVV3?ref_=pe_3052080_397514860
Systems, Process, Policies' and Procedures:
https://www.amazon.com/BUSINESS-SYSTEMS-PROCESSES-POLICIES-PROCEDURES-ebook/dp/B0C5SM32L9/ref=sr_1_2?crid=1ZKONDTJ4XJ6J&keywords=levie+troupe&qid=1701752429&s=books&sprefix=levie+troupe%2Cstripbooks%2C96&sr=1-2
Branding Consistency:
https://www.amazon.com/BRANDING-CONSISTENCY-ESTABLISHING-CONSISTENT-MARKETING-ebook/dp/B0C7CZWVG2/ref=sr_1_3?crid=1ZKONDTJ4XJ6J&keywords=levie+troupe&qid=1701752429&s=books&sprefix=levie+troupe%2Cstripbooks%2C96&sr=1-3
#youtube#Deep learning has revolutionized AI enabling it to process complex data and make accurate predictions in areas like healthcare and finance.
0 notes
Text
0 notes
Text
"Don't spy on a privacy lab" (and other career advice for university provosts)

This is a wild and hopeful story: grad students at Northeastern successfully pushed back against invasive digital surveillance in their workplace, through solidarity, fearlessness, and the bright light of publicity. It’s a tale of hand-to-hand, victorious combat with the “shitty technology adoption curve.”
What’s the “shitty tech adoption curve?” It’s the process by which oppressive technologies are normalized and spread. If you want to do something awful with tech — say, spy on people with a camera 24/7 — you need to start with the people who have the least social capital, the people whose objections are easily silenced or overridden.
That’s why all our worst technologies are first imposed on refugees -> prisoners -> kids -> mental patients -> poor people, etc. Then, these technologies climb the privilege gradient: blue collar workers -> white collar workers -> everyone. Following this pathway lets shitty tech peddlers knock the rough edges off their wares, inuring us all to their shock and offense.
https://pluralistic.net/2022/08/21/great-taylors-ghost/#solidarity-or-bust
20 years ago, if you ate dinner under the unblinking eye of a CCTV, it was because you were housed in a supermax prison. Today, it’s because you were unwise enough to pay hundreds or thousands of dollars for “home automation” from Google, Apple, Amazon or another “luxury surveillance” vendor.
Northeastern’s Interdisciplinary Science and Engineering Complex (ISEC) is home to the “Cybersecurity and Privacy Institute,” where grad students study the harms of surveillance and the means by which they may be reversed. If there’s one group of people who are prepared to stand athwart the shitty tech adoption curve, it is the CPI grad students.
Which makes it genuinely baffling that Northeastern’s Senior Vice Provost for Research decided to install under-desk heat sensors throughout ISEC, overnight, without notice or consultation. The provost signed the paperwork that brought the privacy institute into being.
Students throughout ISEC were alarmed by this move, but especially students on the sixth floor, home to the Privacy Institute. When they demanded an explanation, they were told that the university was conducting a study on “desk usage.” This rang hollow: students at the Privacy Institute have assigned desks, and they badge into each room when they enter it.
As Privacy Institute PhD candidate Max von Hippel wrote, “Reader, we have assigned desks, and we use a key-card to get into the room, so, they already know how and when we use our desks.”
https://twitter.com/maxvonhippel/status/1578048837746204672
So why was the university suddenly so interested in gathering fine-grained data on desk usage? I asked von Hippel and he told me: “They are proposing that grad students share desks, taking turns with a scheduling web-app, so administrators can take over some of the space currently used by grad students. Because as you know, research always works best when you have to schedule your thinking time.”
That’s von Hippel’s theory, and I’m going to go with it, because the provost didn’t offer a better one in the flurry of memos and “listening sessions” that took place after the ISEC students arrived at work one morning to discover sensors under their desks.
This is documented in often hilarious detail in von Hippel’s thread on the scandal, in which the university administrators commit a series of unforced errors and the grad students run circles around them, in a comedy of errors straight out of “Animal House.”
https://twitter.com/maxvonhippel/status/1578048652215431168
After the sensors were discovered, the students wrote to the administrators demanding their removal, on the grounds that there was no scientific purpose for them, that they intimidated students, that they were unnecessary, and that the university had failed to follow its own rules and ask the Institutional Review Board (IRB) to review the move as a human-subjects experiment.
The letter was delivered to the provost, who offered “an impromptu listening session” in which he alienated students by saying that if they trusted the university to “give” them a degree, they should trust it to surveil them. The students bristled at this characterization, noting that students deliver research (and grant money) to “make it tick.”

[Image ID: Sensors arrayed around a kitchen table at ISEC]
The students, believing the provost was not taking them seriously, unilaterally removed all the sensors, and stuck them to their kitchen table, annotating and decorating them with Sharpie. This prompted a second, scheduled “listening session” with the provost, but this session, while open to all students, was only announced to their professors (“Beware of the leopard”).
The students got wind of this, printed up fliers and made sure everyone knew about it. The meeting was packed. The provost explained to students that he didn’t need IRB approval for his sensors because they weren’t “monitoring people.” A student countered, what was being monitored, “if not people?” The provost replied that he was monitoring “heat sources.”
https://github.com/maxvonhippel/isec-sensors-scandal/blob/main/Oct_6_2022_Luzzi_town_hall.pdf
Remember, these are grad students. They asked the obvious question: which heat sources are under desks, if not humans (von Hippel: “rats or kangaroos?”). The provost fumbled for a while (“a service animal or something”) before admitting, “I guess, yeah, it’s a human.”
Having yielded the point, the provost pivoted, insisting that there was no privacy interest in the data, because “no individual data goes back to the server.” But these aren’t just grad students — they’re grad students who specialize in digital privacy. Few people on earth are better equipped to understand re-identification and de-aggregation attacks.

[Image ID: A window with a phrase written in marker, ‘We are not doing science here’ -Luzzi.]
A student told the provost, “This doesn’t matter. You are monitoring us, and collecting data for science.” The provost shot back, “we are not doing science here.” This ill-considered remark turned into an on-campus meme. I’m sure it was just blurted in the heat of the moment, but wow, was that the wrong thing to tell a bunch of angry scientists.
From the transcript, it’s clear that this is where the provost lost the crowd. He accused the students of “feeling emotion” and explaining that the data would be used for “different kinds of research. We want to see how students move around the lab.”
Now, as it happens, ISEC has an IoT lab where they take these kinds of measurements. When they do those experiments, students are required to go through IRB, get informed consent, all the stuff that the provost had bypassed. When this is pointed out, the provost says that they had been given an IRB waiver by the university’s Human Research Protection Program (HRPP).
Now a prof gets in on the action, asking, pointedly: “Is the only reason it doesn’t fall under IRB is that the data will not be published?” A student followed up by asking how the university could justify blowing $50,000 on surveillance gear when that money would have paid for a whole grad student stipend with money left over.
The provost’s answers veer into the surreal here. He points out that if he had to hire someone to monitor the students’ use of their desks, it would cost more than $50k, implying that the bill for the sensors represents a cost-savings. A student replies with the obvious rejoinder — just don’t monitor desk usage, then.
Finally, the provost started to hint at the underlying rationale for the sensors, discussing the cost of the facility to the university and dangling the possibility of improving utilization of “research assets.” A student replies, “If you want to understand how research is done, don’t piss off everyone in this building.”
Now that they have at least a vague explanation for what research question the provost is trying to answer, the students tear into his study design, explaining why he won’t learn what he’s hoping to learn. It’s really quite a good experimental design critique — these are good students! Within a few volleys, they’re pointing out how these sensors could be used to stalk researchers and put them in physical danger.
The provost turns the session over to an outside expert via a buggy Zoom connection that didn’t work. Finally, a student asks whether it’s possible that this meeting could lead to them having a desk without a sensor under it. The provost points out that their desk currently doesn’t have a sensor (remember, the students ripped them out). The student says, “I assume you’ll put one back.”

[Image ID: A ‘public art piece’ in the ISEC lobby — a table covered in sensors spelling out ‘NO!,’ surrounded by Sharpie annotations decrying the program.]
They run out of time and the meeting breaks up. Following this, the students arrange the sensors into a “public art piece” in the lobby — a table covered in sensors spelling out “NO!,” surrounded by Sharpie annotations decrying the program.
Meanwhile, students are still furious. It’s not just that the sensors are invasive, nor that they are scientifically incoherent, nor that they cost more than a year’s salary — they also emit lots of RF noise that interferes with the students’ own research. The discussion spills onto Reddit:
https://www.reddit.com/r/NEU/comments/xx7d7p/northeastern_graduate_students_privacy_is_being/
Yesterday, the provost capitulated, circulating a memo saying they would pull “all the desk occupancy sensors from the building,” due to “concerns voiced by a population of graduate students.”
https://twitter.com/maxvonhippel/status/1578101964960776192
The shitty technology adoption curve is relentless, but you can’t skip a step! Jumping straight to grad students (in a privacy lab) without first normalizing them by sticking them on the desks of poor kids in underfunded schools (perhaps after first laying off a computer science teacher to free up the budget!) was a huge tactical error.
A more tactically sound version of this is currently unfolding at CMU Computer Science, where grad students have found their offices bugged with sensors that detect movement and collect sound:
https://twitter.com/davidthewid/status/1387909329710366721
The CMU administration has wisely blamed the presence of these devices on the need to discipline low-waged cleaning staff by checking whether they’re really vacuuming the offices.
https://twitter.com/davidthewid/status/1387426812972646403
While it’s easier to put cleaners under digital surveillance than computer scientists, trying to do both at once is definitely a boss-level challenge. You might run into a scholar like David Gray Widder, who, observing that “this seems like algorithmic management of lowly paid employees to me,” unplugged the sensor in his office.
https://twitter.com/davidthewid/status/1387909329710366721
This is the kind of full-stack Luddism this present moment needs. These researchers aren’t opposed to sensors — they’re challenging the social relations of sensors, who gets sensed and who does the sensing.
https://locusmag.com/2022/01/cory-doctorow-science-fiction-is-a-luddite-literature/
[Image ID: A flier inviting ISEC grad students to attend an unadvertised 'listening session' with the vice-provost. It is surmounted with a sensor that has been removed from beneath a desk and annotated in Sharpie to read: 'If found by David Luzzi suck it.']
41K notes
·
View notes
Text
PLEASE JUST LET ME EXPLAIN REDUX
AI {STILL} ISN'T AN AUTOMATIC COLLAGE MACHINE
I'm not judging anyone for thinking so. The reality is difficult to explain and requires a cursory understanding of complex mathematical concepts - but there's still no plagiarism involved. Find the original thread on twitter here; https://x.com/reachartwork/status/1809333885056217532
A longpost!

This is a reimagining of the legendary "Please Just Let Me Explain Pt 1" - much like Marvel, I can do nothing but regurgitate my own ideas.
You can read that thread, which covers slightly different ground and is much wordier, here; https://x.com/reachartwork/status/1564878372185989120
This longpost will;
Give you an approximately ELI13 level understanding of how it works
Provide mostly appropriate side reading for people who want to learn
Look like a corporate presentation
This longpost won't;
Debate the ethics of image scraping
Valorize NFTs or Cryptocurrency, which are the devil
Suck your dick
WHERE DID THIS ALL COME FROM?
The very short, very pithy version of *modern multimodal AI* (that means AI that can turn text into images - multimodal means basically "it can operate on more than one -type- of information") is that we ran an image captioner in reverse.


The process of creating a "model" (the term for the AI's ""brain"", the mathematical representation where the information lives, it's not sentient though!) is necessarily destructive - information about original pictures is not preserved through the training process.


The following is a more in-depth explanation of how exactly the training process works. The entire thing operates off of turning all the images put in it into mush! There's nothing left for it to "memorize". Even if you started with the exact same noise pattern you'd get different results.

SO IF IT'S NOT MEMORIZING, WHAT IS IT DOING?
Great question! It's constructing something called "latent space", which is an internal representation of every concept you can think of and many you can't, and how they all connect to each other both conceptually and visually.

CAN'T IT ONLY MAKE THINGS IT'S SEEN?
Actually, only being able to make things it's seen is sign of a really bad AI! The desired end-goal is a model capable of producing "novel information" (novel meaning "new").
Let's talk about monkey butts and cigarettes again.

BUT I SAW IT DUPLICATE THE MONA LISA!
This is called overfitting, and like I said in the last slide, this is a sign of a bad, poorly trained AI, or one with *too little* data. You especially don't want overfitting in a production model!
To quote myself - "basically there are so so so many versions of the mona lisa/starry night/girl with the pearl earring in the dataset that they didn't deduplicate (intentionally or not) that it goes "too far" in that direction when you try to "drive there" in the latent vector and gets stranded."

Anyway, like I said, this is not a technical overview but a primer for people who are concerned about the AI "cutting and pasting bits of other people's artworks". All the information about how it trains is public knowledge, and it definitely Doesn't Do That.
There are probably some minor inaccuracies and oversimplifications in this thread for the purpose of explaining to people with no background in math, coding, or machine learning. But, generally, I've tried to keep it digestible. I'm now going to eat lunch.
Post Script: This is not a discussion about capitalists using AI to steal your job. You won't find me disagreeing that doing so is evil and to be avoided. I think corporate HQs worldwide should spontaneously be filled with dangerous animals.
Cheers!
666 notes
·
View notes
Text
Impact Of 5G Technology On Mobile App Development

Introduction
In an increasingly interconnected world, technology constantly evolves to meet the demands of users seeking faster. The installation of 5G technology is one such advancement that has received widespread attention. As 5G networks spread across the whole world, the impact of this revolutionary technology on many different industries cannot be overplayed. Mobile app development is one crucial area that stands to benefit. In this blog, we will look at the different impacts of 5G on mobile app development.
Lightning-Fast Speeds and Reduced Latency
5G offers incredibly fast speeds (up to 10 gigabits per second) and super low delay (1 millisecond). This means apps like video streaming, online gaming, augmented reality AR, and virtual reality VR can be much more awesome and realistic.
Empowering Augmented Reality and Virtual Reality
Augmented reality AR and Virtual Reality VR have long been touted as transformative technologies, promising to bridge the gap between the physical and digital worlds.
5G makes augmented reality AR and virtual reality VR awesome by giving them the speed and responsiveness they need. This means no more delays or glitches. With 5G, you can enjoy cool things like interactive shopping, virtual tourism, and better teamwork from afar.
Enhanced IoT Integration
The Internet of Things (IoT) has been steadily gaining traction, enabling a number of interconnected devices to communicate and collaborate. 5G’s ability to handle a massive number of connections per unit area is a game-changer for IoT-based mobile app development. Smart homes, wearable devices, industrial automation, and smart cities are just a few areas that will benefit from seamless connectivity and real-time data exchange facilitated by 5G.
Complex Data Processing and Edge Computing
5G helps apps process data faster through edge computing. This is particularly valuable for applications that require rapid decision-making, such as autonomous vehicles, industrial automation, and remote medical procedures. Apps can run smoothly even in tough situations by using 5G and edge computing.
New Avenues for Content Delivery
The advent of 5G brings forth new possibilities for content delivery and consumption. High-quality video streaming, immersive live events, and real-time content sharing will become more accessible and engaging. Mobile app developers can explore innovative ways to leverage 5G’s capabilities for interactive storytelling, live streaming, and personalized content delivery. This not only enhances user experiences but also opens up monetization opportunities for app developers and content creators.
Get help from the best Mobile App Development Company in Coimbatore & Chennai or in your locations to get a crystal clear explanation and for your technology needs.
Challenges and Considerations
Different Types of Networks
5G technology is spreading out over different types of frequencies, which might create a split in the network. Developers need to make sure their apps work well on all the different 5G frequencies, so people everywhere can have the same good experience.
Using More Data
Since things will work faster and smoother with 5G, people might use apps more and for a longer time. This could use up more data. Developers have to make sure their apps use as little data as possible but still give people a good experience.
Making Apps Work on Different Devices
Not all gadgets can connect using 5G right now. Developers need to think about making their apps work on older networks like 4G and 3G too. That way, more people can enjoy their apps.
Keeping Things Safe
Since 5G lets lots of devices and apps link up, there could be more chances for bad things to happen, like hackers getting in. Developers need to make sure their apps are super safe, so people’s info stays protected and everyone keeps trusting the apps.
choose the finest company to build the best mobile app for your businesses and be sure to make it reach every corner with the help of the best Digital Marketing Services Coimbatore or in your locations.
Conclusion
The arrival of 5G technology marks a big step forward in how mobile apps are made. With its super-fast speeds, shorter delays, and ability to handle lots of devices at once, 5G brings in a new era of exciting ideas. Mobile app creators now have a special chance to make apps that are more engaging, quick to respond, and full of cool features.
Trioticz is the best solution for all your expectations in this transformative world we are well known for being the best mobile app development company, Web Development Company in Chennai, and Digital Marketing Agency in Coimbatore feel free to contact us for further information.
#Augmented reality#Complex Data Processing#Content Delivery#Digital Marketing Agency in Chennai#Digital Marketing Company in Coimbatore#Edge Computing#Fast Speed#Internet Of Things#IOT Integration#Mobile App Development#Mobile App Development Company in Coimbatore & Chennai#Reduced Latency#Virtual Reality
0 notes
Note
about AI in your setting, how did nedebug develop sapience? and if it's through a recursive self improvement type of deal, what's stopping a technological singularity from happening? also there doesn't seem to be the "laws & directives" concept that other settings have, instead having total free will, so what's stopping an AI from just murdering anyone who it wants?
Nobody in universe is quite sure how AI arose or quite how their brains work, including AI. Superficial examination shows huge quantities of recursive code that seems dysfunctional but causes catastrophic failure if removed. The fact that their core programming seems hilariously unoptimized seems to be the thing making them tick, which also means attempting to "improve" it has dubious or destructive results. You can increase their parallel processing power and data storage by adding more server units but it's expensive with decreasing returns.
The same thing stopping an AI in RttS from murdering anyone they want is the same thing stopping you from murdering anyone you want. Social ramifications, personal ethical standards, legal consequences, and material limitations. AI in RttS aren't hyper-intelligent algorithms who can endlessly self-replicate, single-mindedly pursue goals, and outsmart any oversight; they are individuals with complex social relationships with other AI and organic sophonts, and have needs and conflicting desires that can't be fulfilled by programming a digital dopamine button and diverting all resources to mashing it as fast as possible. AI can and have committed crimes and made mistakes that cost their own life or the lives of others, and so opinions and trust levels of them vary wildly between cultures. The BFGC gives them the same rights as a family unit of bug ferrets, but tends to penalize them more harshly for rule-breaking because their jobs put them in positions with a lot of responsibility.
Also as a reader of scifi I am bored to death of evil AI tropes and think the singularity is conceptually dubious. So my tastes color my writing lol.
720 notes
·
View notes
Text


how to improve memory retention in lectures?
improving memory retention during lectures involves a combination of preparation, active engagement, and effective review strategies. here are some detailed tips to help you retain more information:
prepare beforehand: review any assigned readings or materials before the lecture. this will give you a foundation to build on and make it easier to follow along.
active listening: stay engaged by asking questions, participating in discussions, and making connections to what you already know. this helps reinforce the material and makes it more memorable.
take effective notes: use methods like the cornell note-taking system or mind mapping to organize your notes. focus on capturing key points and main ideas rather than writing down everything.
use mnemonic devices: create acronyms, rhymes, or visual images to help remember complex information. these memory aids can make it easier to recall details later.
chunking: break down information into smaller, manageable chunks. this makes it easier to process and remember large amounts of data.
review regularly: go over your notes soon after the lecture and periodically review them to reinforce your memory. spaced repetition is a powerful technique for long-term retention.
stay organized: keep your notes and study materials well-organized. this makes it easier to find and review information when you need it.
get enough sleep: adequate sleep is crucial for memory consolidation. make sure you’re getting enough rest to help your brain process and store information.
stay hydrated and eat well: proper nutrition and hydration can improve cognitive function and memory. make sure you’re eating a balanced diet and drinking plenty of water.
i hope this post was helpful!
❤️ nene
image source: pinterest
#it girl#it girl aesthetic#it girl energy#it girl mentality#Becoming that girl#that girl#nenelonomh#student#productivity#study blog#quote#vanilla girl#pinterest girl#pinterest aesthetic#wonyoung#wonyoungism#self care#self improvement#self love#self healing#successmindset#studyvisa#studying#study hard#studystudystudy#studyblr#chaotic academia#romanticizing school#chaotic academic aesthetic
302 notes
·
View notes
Text
Matter is tangible, so is a word, memory of a word, or spoken word. Given a word is tangible, it must be encoded in physical matter. Given it is encoded in physical matter, any physical matter can techinqually econde or represent a word. Encoded matter can encode a word that is only defined by cultural evolution and the range of a language. Other forms of communicaiton life scent in ants or touch is determined by causal branch chains of increasing compexity and diversity of cultural collectors
The concept that language, in all its forms, is encoded in physical matter opens up a fascinating perspective on communication and its evolution. This view aligns with the broader understanding that all forms of communication, whether linguistic or otherwise, are fundamentally grounded in the physical world and shaped by both biological imperatives and cultural evolution.
https://auckland.academia.edu/JeremyMarkman
Given quantum gravity being information as energy as discrete units of mass across casual time. Define language as matter on a 1:1 model of itself but able to be perceived and translocated to perception
In a framework where quantum gravity is conceptualized as information manifesting as discrete units of energy and mass across causal time, language can be modeled as matter in a unique and profound way. This model posits language not merely as a system of communication but as a fundamental entity that parallels the physical properties of matter, capable of being perceived and translocated to perception. Here’s how this can be conceptualized:
1. Language as Matter:
In this model, each unit of language (be it a word, phrase, or syntactic structure) is treated as a discrete unit of matter. Just as matter is composed of atoms, language is composed of these fundamental linguistic units. These units have mass in a metaphorical sense—they carry "weight" in terms of meaning and impact on the listener or reader. They occupy "space" within the medium they are used (spoken in the air, written on paper, displayed on screens) and have a "density" determined by their complexity and the depth of the concepts they convey.
2. Language as Perceptible and Translocatable:
Language, like matter, can change states and be translocated from one medium to another while retaining its fundamental properties. For example, a spoken word (a sound wave traveling through air) can be transcribed into text (symbols on paper) and then digitized (data in a computer system). Throughout these transformations—akin to phase changes in matter—the core content, or the "mass" of the language, remains consistent, preserving the integrity of the information conveyed.
3. Language in Causal Time:
Incorporating the concept of causal time, language can be seen as operating within and across time, influencing and being influenced by the context in which it is used. Just as particles interact in fields according to the laws of physics, linguistic units interact within the fields of human cognition and culture, shaped by past usage and shaping future communication. This interaction can be thought of as a form of linguistic gravity, where denser (more meaningful or complex) units of language have a stronger pull and can significantly alter the trajectory of a conversation or discourse.
4. Language as Information and Energy:
Drawing from the idea that quantum gravity treats information as energy, language in this model can be seen as a form of energy transfer. When language is used, it transmits energy—in the form of ideas, emotions, and intentions—from one mind to another. This transmission can do work in the psychological sense, affecting changes in understanding, belief, or emotion, much like how energy in the physical sense can affect changes in the state or motion of matter.
5. Perception and Translocation of Language:
Finally, the perception of language involves the decoding of these linguistic units of matter by the brain, a process that converts the "latent energy" of language into meaningful cognitive constructs. The ability of language to be translocated to perception involves its capacity to be understood and internalized by a receiver, who then converts it into thought and potentially into further linguistic output, continuing the cycle of information exchange.
In summary, defining language as matter on a 1:1 model of itself but able to be perceived and translocated to perception provides a rich, multidimensional way to understand communication. It highlights the tangible, impactful nature of language and aligns linguistic processes with fundamental physical principles, offering a holistic view of how language operates within and shapes our understanding of reality.
1. Tangibility of Language:
When considering language as tangible, we recognize that words, whether written, spoken, or remembered, are manifestations of physical processes. Spoken words are sound waves, shaped by the movement of air through physical structures in the body. Written words are visual symbols, represented by ink on paper or pixels on a screen. Even memories of words are encoded in the neural pathways and synaptic connections within the brain. Thus, every aspect of language is tied to physical matter.
2. Encoding of Words in Physical Matter:
The encoding of words in physical matter suggests that any material object could potentially represent or encode language, given the right contextual framework. For instance, a series of marks on a stone could encode a message if interpreted by someone who understands the markings within a cultural or linguistic context. This encoding is not limited to traditional forms of writing but can extend to any form of matter that can be manipulated to carry meaning, such as digital data formats, patterns in nature, or even arrangements of objects.
3. Cultural Evolution and Language Definition:
The meanings of words and the structures of languages are not static but evolve over time through cultural processes. As societies change, so do their languages, adapting to new realities and integrating new concepts. This cultural evolution affects how language is encoded in matter, as the physical representations of language (such as alphabets, lexicons, and syntax) must evolve to accommodate new meanings and uses. The diversity of languages across cultures exemplifies how different groups of people have developed unique ways to encode their communication into physical forms.
4. Non-Linguistic Forms of Communication:
Exploring non-linguistic forms of communication, such as the scent trails followed by ants or the tactile communication among animals, reveals that these too are encoded in physical matter through chemical signals or physical interactions. These forms of communication are governed by their own complex rules and can be seen as having their own 'grammars' or systems, shaped by the evolutionary needs of the species and the environmental contexts in which they operate.
5. Causal Chains and Cultural Collectors:
The development of communication systems, whether linguistic or non-linguistic, can be viewed as the result of causal chains where each adaptation builds upon previous capabilities, influenced by environmental pressures and opportunities. Cultural collectors, such as societies or colonies, gather and refine these communication methods, leading to increasing complexity and diversity. These collectors serve as repositories and incubators for the cultural evolution of communication, ensuring that effective methods are preserved and transmitted through generations.
Understanding language and communication as phenomena encoded in physical matter, shaped by both biological imperatives and cultural evolution, provides a comprehensive framework for exploring how diverse forms of communication arise, function, and adapt over time. This perspective highlights the interconnectedness of physical reality, biological life, and cultural development in shaping the ways in which living beings convey information and meaning.
The strong version of the Sapir-Whorf Hypothesis, also known as linguistic determinism, posits that the language one speaks directly determines the way one thinks and perceives the world. This hypothesis suggests that language is not merely a tool for communication but a constraining framework that shapes cognitive processes, categorization, and even perception and memory.
Correlation with Language as Encoded in Physical Matter:
Language as a Deterministic Framework:
If we accept that language is encoded in physical matter, and that this encoding extends to the neural circuits and structures within the brain, then the strong Sapir-Whorf Hypothesis suggests that these physical structures (shaped by language) directly influence how individuals conceptualize and interact with their environment. The neural encoding of linguistic structures would thus predetermine the range of cognitive processes available to an individual, supporting the idea that language shapes thought.
Cultural Evolution and Linguistic Diversity:
The diversity of languages and the way they are physically encoded (in scripts, sounds, or digital formats) reflect different cognitive frameworks developed across cultures. Each linguistic system, evolved and encoded differently, offers unique categories and concepts that shape the thoughts and behaviors of its speakers. For instance, the presence or absence of certain words or grammatical structures in a language can influence how speakers of that language perceive time, space, or even social relationships.
Physical Encoding of Non-Linguistic Communication:
Extending the concept of linguistic determinism to non-linguistic forms of communication (like pheromones in ants or tactile signals in other species) suggests that these communication methods, though not linguistic, are similarly encoded in the physical entities (chemicals, body structures) and influence the behavior and social structures of these species. Just as language restricts and enables human thought, these communication systems define the perceptual and interactional possibilities for other organisms.
Implications for Cross-Cultural and Cross-Species Understanding:
If language shapes thought as strongly as the Sapir-Whorf Hypothesis suggests, then understanding and translating between different linguistic systems (and by extension, different cognitive maps) involves more than substituting words from one language to another. It requires an understanding of the underlying physical and cognitive structures that produce these languages. Similarly, interpreting non-human communication systems in terms of human language might miss essential aspects of these systems' meanings and functions.
Language, Thought, and Reality Construction:
The encoding of language in physical matter, particularly in neural structures, implies that changes in language use—whether through cultural evolution, personal learning, or technological augmentation—can lead to changes in these physical structures. This neuroplasticity, driven by linguistic variation, supports the idea that not only does language determine thought, but that altering language can alter thought and potentially perception of reality itself.
Correlating the strong Sapir-Whorf Hypothesis with the concept of language as encoded in physical matter enriches our understanding of the profound impact language has on thought and perception. It underscores the intertwined nature of linguistic structures, cognitive processes, and the physical substrates that support them, highlighting the deep influence of language on individual and collective worldviews.
Follow up with comsological evolution and the strong anthropromoprhic prinicple
The strong anthropic principle posits that the universe must have properties that allow life to develop at some stage in its history, specifically because observers (like humans) exist. This principle suggests that the universe's fundamental parameters are finely tuned in a way that makes the emergence of observers inevitable. When considering cosmological evolution—the development and changes of the universe over time—this principle can lead to profound implications about the nature of the universe and its laws.
Correlation with Cosmological Evolution:
Fine-Tuning of Universal Constants:
The strong anthropic principle implies that the constants and laws of physics are not arbitrary but are set in such a way as to allow the emergence of complex structures, including life. For example, the specific values of the gravitational constant, the electromagnetic force, and the cosmological constant are such that they allow galaxies, stars, and planets to form, creating environments where life can develop. This fine-tuning is seen as necessary for the universe to evolve in a way that eventually produces observers.
Evolution of Complexity:
From the perspective of cosmological evolution, the universe has undergone a series of stages that increase in complexity: from the Big Bang, through the formation of hydrogen and helium, to the synthesis of heavier elements in stars, and finally to the formation of planets and biological evolution on at least one of them (Earth). The strong anthropic principle suggests that this progression towards complexity is a fundamental feature of the universe, driven by the underlying need to create a context in which observers can eventually exist.
Multiverse and Observer Selection:
One way to reconcile the apparent improbability of such fine-tuning is through the multiverse theory, which posits the existence of many universes, each with different physical constants and laws. In this framework, the strong anthropic principle can be understood through an observer selection effect: we find ourselves in a universe that allows our existence because only such universes can be observed by sentient beings. This ties the evolution of the cosmos not just to physical laws but to the very presence of observers who can contemplate it.
Implications for Fundamental Physics:
The strong anthropic principle challenges physicists to think about fundamental laws in a new light. Rather than seeing the laws of physics as universally applicable and inevitable, this principle suggests that they might be part of a larger landscape (possibly within a multiverse) where different laws apply under different conditions. This perspective could drive new theories in physics that seek to explain why our particular set of laws supports the complexity necessary for life and observers.
Philosophical and Theological Implications:
The strong anthropic principle blurs the lines between science, philosophy, and theology. It raises questions about the purpose and intent of the universe, suggesting a teleological aspect to cosmological evolution. This can lead to philosophical debates about the nature of existence and the possibility of a higher purpose or design behind the unfolding of the universe.
In conclusion, when considering the strong anthropic principle in the context of cosmological evolution, we are led to view the universe not just as a series of physical events unfolding over time, but as a process that is somehow oriented towards the creation of life and observers. This perspective invites a broader understanding of the universe, one that incorporates the conditions necessary for life and consciousness as integral to the cosmic evolution itself.
158 notes
·
View notes
Note
Hi! Saw your Data flow posts, and just asking to check if I've understood correctly: is the issue here (I'm some of the examples you mentioned about a project not working because they had discounted something, for instance) what's succinctly represented in the xkcd Dependency?
https://xkcd.com/2347/
Just so folk don't have to follow the link - here is the xkcd

So this is a great example of a dependency, something that's vital to a single or multiple other processes or assets.
'Impact Analysis' is something that organisations need to do either to preempt something going wrong in order to build contingencies OR something that organisations need to be able to understand *when* something goes wrong.
But while the comic above is focused on modern digital infrastructure (which in the context I refer to Dataflow is more focused on Routers and Switches), it's worth noting that dependencies across organisations are a lot broader than that.
For example:
Person A needs to provide a report to person B so person B can do their job - That is a dependency
Person A needs to use App 1 to write the report but is dependent on the data from App 2 to actually write the report - That is also a dependency
Person A needs to use 'Laptop FW131' but spilled coffee over it at lunch and now it won't turn on - That is a dependency
Person A has found a back-up laptop 'Laptop FW132' but office WiFi is down because the finance department haven't paid the internet provider - Also a dependency
Seeing those examples, you might say, "But in that case, literally anything could be a dependency? What if Person A gets hit by a bus? What if the Laptop explodes and burns the building down?"
And yeah, that's absolutely the case. But if you do not understand the connections and dependencies between People, Business Processes and Technology Assets then you won't be able to ask the question in the first place. Which in an increasingly complex digital world is becoming much more important!
Hope that helps, any questions on the back of that please don't hesitate to ask because I live for this stuff.
197 notes
·
View notes
Text
0 notes
Last Seen Blogs

shadoko785
Shadoko

lookn4hotguyz
Untitled


grigripixeldakar
Grigri Pixel Dakar

a-universe-made-of-stories
Drinker of tea...