#Databricks Platform
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs




Fun Fact
Mobile Tumblr US users spend an average of 4.04 minutes per session on the app.
Text
Maximizing Manufacturing Efficiency with Databricks Platform
Databricks Platform is a game-changer for the manufacturing industry. Its ability to integrate and process vast amounts of data, provide predictive maintenance, offer real-time analytics, and enhance quality control makes it an essential tool for modern manufacturers.
#Databricks Platform#Databricks#databricks developers#databricks solutions#databricks services#lagozon technologies
0 notes
Text
Unlocking Business Potential with Databricks: Comprehensive Solutions for the Modern Enterprise
In the era of big data and cloud computing, the Databricks platform stands out as a transformative force, enabling businesses to unlock the full potential of their data. With its robust capabilities, Databricks empowers organizations across various sectors to harness data-driven insights and drive innovation. From Databricks cloud solutions to specialized Databricks financial services, Databricks professional services, and Databricks managed services, we explore how this powerful platform can revolutionize business operations and strategies.
Understanding the Databricks Platform: A Unified Approach to Data and AI
The Databricks platform is a cloud-based solution designed to streamline and enhance data engineering, data science, and machine learning processes. It offers a unified interface that integrates various data tools and technologies, making it easier for businesses to manage their data pipelines, perform analytics, and deploy machine learning models. Key features of the Databricks platform include:
Unified Analytics: Bringing together data processing, analytics, and machine learning in a single workspace, facilitating collaboration across teams.
Scalability: Leveraging cloud infrastructure to scale resources dynamically, accommodating growing data volumes and complex computations.
Interactive Workspaces: Providing a collaborative environment where data scientists, engineers, and business analysts can work together seamlessly.
Advanced Security: Ensuring data protection with robust security measures and compliance with industry standards.
Leveraging the Power of Databricks Cloud Solutions
Databricks cloud solutions are integral to modern enterprises looking to maximize their data capabilities. By utilizing the cloud, businesses can achieve:
Flexible Resource Management: Allocate and scale computational resources as needed, optimizing costs and performance.
Enhanced Collaboration: Cloud-based platforms enable global teams to collaborate in real-time, breaking down silos and fostering innovation.
Rapid Deployment: Implement and deploy solutions quickly without the need for extensive on-premises infrastructure.
Continuous Availability: Ensure data and applications are always accessible, providing resilience and reliability for critical operations.
Databricks Financial Services: Transforming the Financial Sector
Databricks financial services are tailored to meet the unique needs of the financial industry, where data plays a pivotal role in decision-making and risk management. These services provide:
Risk Analytics: Leveraging advanced analytics to identify and mitigate financial risks, enhancing the stability and security of financial institutions.
Fraud Detection: Using machine learning models to detect fraudulent activities in real-time, protecting businesses and customers from financial crimes.
Customer Insights: Analyzing customer data to gain deep insights into behavior and preferences, driving personalized services and engagement.
Regulatory Compliance: Ensuring compliance with financial regulations through robust data management and reporting capabilities.
Professional Services: Expert Guidance and Support with Databricks
Databricks professional services offer specialized expertise and support to help businesses fully leverage the Databricks platform. These services include:
Strategic Consulting: Providing insights and strategies to integrate Databricks into existing workflows and maximize its impact on business operations.
Implementation Services: Assisting with the setup and deployment of Databricks solutions, ensuring a smooth and efficient implementation process.
Training and Enablement: Offering training programs to equip teams with the skills needed to effectively use Databricks for their data and AI projects.
Ongoing Support: Delivering continuous support to address any technical issues and keep Databricks environments running optimally.
Databricks Managed Services: Streamlined Data Management and Operations
Databricks managed services take the complexity out of managing data environments, allowing businesses to focus on their core activities. These services provide:
Operational Management: Handling the day-to-day management of Databricks environments, including monitoring, maintenance, and performance optimization.
Security and Compliance: Ensuring that data systems meet security and compliance requirements, protecting against threats and regulatory breaches.
Cost Optimization: Managing cloud resources efficiently to control costs while maintaining high performance and availability.
Scalability Solutions: Offering scalable solutions that can grow with the business, accommodating increasing data volumes and user demands.
Transforming Data Operations with Databricks Solutions
The comprehensive range of Databricks solutions enables businesses to address various challenges and opportunities in the data landscape. These solutions include:
Data Engineering
Pipeline Automation: Automating the extraction, transformation, and loading (ETL) processes to streamline data ingestion and preparation.
Real-Time Data Processing: Enabling the processing of streaming data for real-time analytics and decision-making.
Data Quality Assurance: Implementing robust data quality controls to ensure accuracy, consistency, and reliability of data.
Data Science and Machine Learning
Model Development: Supporting the development and training of machine learning models to predict outcomes and automate decision processes.
Collaborative Notebooks: Providing interactive notebooks for collaborative data analysis and model experimentation.
Deployment and Monitoring: Facilitating the deployment of machine learning models into production environments and monitoring their performance over time.
Business Analytics
Interactive Dashboards: Creating dynamic dashboards that visualize data insights and support interactive exploration.
Self-Service Analytics: Empowering business users to perform their own analyses and generate reports without needing extensive technical skills.
Advanced Reporting: Delivering detailed reports that combine data from multiple sources to provide comprehensive insights.
Maximizing the Benefits of Databricks: Best Practices for Success
To fully leverage the capabilities of Databricks, businesses should adopt the following best practices:
Define Clear Objectives: Establish specific goals for how Databricks will be used to address business challenges and opportunities.
Invest in Training: Ensure that teams are well-trained in using Databricks, enabling them to utilize its full range of features and capabilities.
Foster Collaboration: Promote a collaborative culture where data scientists, engineers, and business analysts work together to drive data initiatives.
Implement Governance Policies: Develop data governance policies to manage data access, quality, and security effectively.
Continuously Optimize: Regularly review and optimize Databricks environments to maintain high performance and cost-efficiency.
The Future of Databricks Services and Solutions
As data continues to grow in volume and complexity, the role of Databricks in managing and leveraging this data will become increasingly critical. Future trends in Databricks services and solutions may include:
Enhanced AI Integration: More advanced AI tools and capabilities integrated into the Databricks platform, enabling even greater automation and intelligence.
Greater Emphasis on Security: Continued focus on data security and privacy, ensuring robust protections in increasingly complex threat landscapes.
Expanded Cloud Ecosystem: Deeper integrations with a broader range of cloud services, providing more flexibility and choice for businesses.
Real-Time Insights: Greater emphasis on real-time data processing and analytics, supporting more immediate and responsive business decisions.
#databricks platform#databricks cloud#databricks financial services#databricks professional services#databricks managed services
0 notes
Text

Contact CT Shift - Automate Migration from SAS (celebaltech.com)
0 notes
Text
0 notes
Text
From Siloed Systems to Scalable Agility: A Financial Services Company's Journey Migrating Teradata and Hadoop to Google Cloud Platform
For many financial services companies, managing data sprawl across disparate systems like Teradata and Hadoop can be a significant hurdle. This was the case for one such company, facing challenges with:
Limited Scalability: Traditional on-premises infrastructure struggled to handle the ever-growing volume and complexity of financial data.
Data Silos: Siloed data across Teradata and Hadoop hindered a holistic view of customer information and market trends.
High Operational Costs: Maintaining and managing separate systems proved expensive and resource-intensive.
Seeking a Modernized Data Architecture:
Recognizing the need for a more agile and scalable solution, the company embarked on a strategic migration journey to Google Cloud Platform (GCP). This migration involved:
Teradata to GCP Migration: Leveraging GCP's data warehousing solutions, the company migrated its data from Teradata, consolidating it into a central and scalable platform.
Hadoop Migration to GCP: For its big data processing needs, the company migrated its Hadoop workloads to Databricks on GCP. Databricks, a cloud-native platform, offered superior scalability and integration with other GCP services.
Benefits of Moving to GCP:
Migrating to GCP yielded several key benefits:
Enhanced Scalability and Agility: GCP's cloud-based infrastructure provides the scalability and elasticity needed to handle fluctuating data volumes and processing demands.
Unified Data Platform: Consolidated data from Teradata and Hadoop within GCP enables a holistic view of customer information, market trends, and risk factors, empowering data-driven decision-making.
Reduced Operational Costs: By eliminating the need to maintain separate on-premises infrastructure, the company achieved significant cost savings.
Advanced Analytics Capabilities: GCP's suite of data analytics tools allows the company to extract deeper insights from their data, driving innovation and improving risk management strategies.
Lessons Learned: Planning and Partnership are Key
The success of this migration hinged on two crucial aspects:
Meticulous Planning: A thorough assessment of the existing data landscape, along with a well-defined migration strategy, ensured a smooth transition.
Partnership with a Cloud Migration Expert: Collaborating with a Google Cloud Partner provided the necessary expertise and resources to navigate the migration process efficiently.
Conclusion:
teradata to databricks migration and Hadoop to Databricks Migration provided financial services company achieved a more scalable, agile, and cost-effective data architecture. The consolidated data platform and access to advanced analytics empower them to make informed decisions, optimize operations, and gain a competitive edge in the ever-evolving financial landscape. Their story serves as a testament to the transformative power of cloud migration for the financial services industry.
0 notes
Text
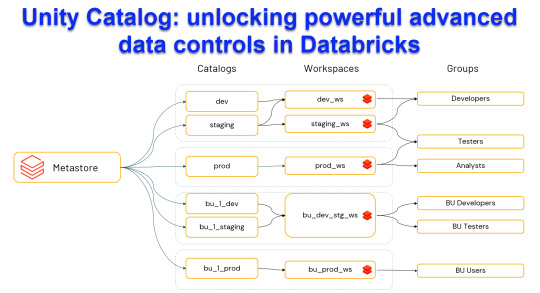
Unity Catalog: Unlocking Powerful Advanced Data Control in Databricks
Harness the power of Unity Catalog within Databricks and elevate your data governance to new heights. Our latest blog post, "Unity Catalog: Unlocking Advanced Data Control in Databricks," delves into the cutting-edge features
View On WordPress
#Advanced Data Security#Automated Data Lineage#Cloud Data Governance#Column Level Masking#Data Discovery and Cataloging#Data Ecosystem Security#Data Governance Solutions#Data Management Best Practices#Data Privacy Compliance#Databricks Data Control#Databricks Delta Sharing#Databricks Lakehouse Platform#Delta Lake Governance#External Data Locations#Managed Data Sources#Row Level Security#Schema Management Tools#Secure Data Sharing#Unity Catalog Databricks#Unity Catalog Features
0 notes
Text
Multiple current and former government IT sources tell WIRED that it would be easy to connect the IRS’s Palantir system with the ICE system at DHS, allowing users to query data from both systems simultaneously. A system like the one being created at the IRS with Palantir could enable near-instantaneous access to tax information for use by DHS and immigration enforcement. It could also be leveraged to share and query data from different agencies as well, including immigration data from DHS. Other DHS sub-agencies, like USCIS, use Databricks software to organize and search its data, but these could be connected to outside Foundry instances simply as well, experts say. Last month, Palantir and Databricks struck a deal making the two software platforms more interoperable.
“I think it's hard to overstate what a significant departure this is and the reshaping of longstanding norms and expectations that people have about what the government does with their data,” says Elizabeth Laird, director of equity in civic technology at the Center for Democracy and Technology, who noted that agencies trying to match different datasets can also lead to errors. “You have false positives and you have false negatives. But in this case, you know, a false positive where you're saying someone should be targeted for deportation.”
Mistakes in the context of immigration can have devastating consequences: In March, authorities arrested and deported Kilmar Abrego Garcia, a Salvadoran national, due to, the Trump administration says, “an administrative error.” Still, the administration has refused to bring Abrego Garcia back, defying a Supreme Court ruling.
“The ultimate concern is a panopticon of a single federal database with everything that the government knows about every single person in this country,” Venzke says. “What we are seeing is likely the first step in creating that centralized dossier on everyone in this country.”
DOGE Is Building a Master Database to Surveil and Track Immigrants
21 notes
·
View notes
Text
Mythbusting Generative AI: The Ethical ChatGPT Is Out There
I've been hyperfixating learning a lot about Generative AI recently and here's what I've found - genAI doesn’t just apply to chatGPT or other large language models.
Small Language Models (specialised and more efficient versions of the large models)
are also generative
can perform in a similar way to large models for many writing and reasoning tasks
are community-trained on ethical data
and can run on your laptop.

"But isn't analytical AI good and generative AI bad?"
Fact: Generative AI creates stuff and is also used for analysis
In the past, before recent generative AI developments, most analytical AI relied on traditional machine learning models. But now the two are becoming more intertwined. Gen AI is being used to perform analytical tasks – they are no longer two distinct, separate categories. The models are being used synergistically.
For example, Oxford University in the UK is partnering with open.ai to use generative AI (ChatGPT-Edu) to support analytical work in areas like health research and climate change.

"But Generative AI stole fanfic. That makes any use of it inherently wrong."
Fact: there are Generative AI models developed on ethical data sets
Yes, many large language models scraped sites like AO3 without consent, incorporating these into their datasets to train on. That’s not okay.
But there are Small Language Models (compact, less powerful versions of LLMs) being developed which are built on transparent, opt-in, community-curated data sets – and that can still perform generative AI functions in the same way that the LLMS do (just not as powerfully). You can even build one yourself.

No it's actually really cool! Some real-life examples:
Dolly (Databricks): Trained on open, crowd-sourced instructions
RedPajama (Together.ai): Focused on creative-commons licensed and public domain data
There's a ton more examples here.
(A word of warning: there are some SLMs like Microsoft’s Phi-3 that have likely been trained on some of the datasets hosted on the platform huggingface (which include scraped web content like from AO3), and these big companies are being deliberately sketchy about where their datasets came from - so the key is to check the data set. All SLMs should be transparent about what datasets they’re using).
"But AI harms the environment, so any use is unethical."
Fact: There are small language models that don't use massive centralised data centres.
SLMs run on less energy, don’t require cloud servers or data centres, and can be used on laptops, phones, Raspberry Pi’s (basically running AI locally on your own device instead of relying on remote data centres)
If you're interested -
You can build your own SLM and even train it on your own data.

Let's recap
Generative AI doesn't just include the big tools like chatGPT - it includes the Small Language Models that you can run ethically and locally
Some LLMs are trained on fanfic scraped from AO3 without consent. That's not okay
But ethical SLMs exist, which are developed on open, community-curated data that aims to avoid bias and misinformation - and you can even train your own models
These models can run on laptops and phones, using less energy
AI is a tool, it's up to humans to wield it responsibly

It means everything – and nothing
Everything – in the sense that it might remove some of the barriers and concerns people have which makes them reluctant to use AI. This may lead to more people using it - which will raise more questions on how to use it well.
It also means that nothing's changed – because even these ethical Small Language Models should be used in the same way as the other AI tools - ethically, transparently and responsibly.
So now what? Now, more than ever, we need to be having an open, respectful and curious discussion on how to use AI well in writing.
In the area of creative writing, it has the potential to be an awesome and insightful tool - a psychological mirror to analyse yourself through your stories, a narrative experimentation device (e.g. in the form of RPGs), to identify themes or emotional patterns in your fics and brainstorming when you get stuck -
but it also has capacity for great darkness too. It can steal your voice (and the voice of others), damage fandom community spirit, foster tech dependency and shortcut the whole creative process.

Just to add my two pence at the end - I don't think it has to be so all-or-nothing. AI shouldn't replace elements we love about fandom community; rather it can help fill the gaps and pick up the slack when people aren't available, or to help writers who, for whatever reason, struggle or don't have access to fan communities.
People who use AI as a tool are also part of fandom community. Let's keep talking about how to use AI well.
Feel free to push back on this, DM me or leave me an ask (the anon function is on for people who need it to be). You can also read more on my FAQ for an AI-using fanfic writer Master Post in which I reflect on AI transparency, ethics and something I call 'McWriting'.
#fandom#fanfiction#ethical ai#ai discourse#writing#writers#writing process#writing with ai#generative ai#my ai posts
4 notes
·
View notes
Text
What EDAV does:
Connects people with data faster. It does this in a few ways. EDAV:
Hosts tools that support the analytics work of over 3,500 people.
Stores data on a common platform that is accessible to CDC's data scientists and partners.
Simplifies complex data analysis steps.
Automates repeatable tasks, such as dashboard updates, freeing up staff time and resources.
Keeps data secure. Data represent people, and the privacy of people's information is critically important to CDC. EDAV is hosted on CDC's Cloud to ensure data are shared securely and that privacy is protected.
Saves time and money. EDAV services can quickly and easily scale up to meet surges in demand for data science and engineering tools, such as during a disease outbreak. The services can also scale down quickly, saving funds when demand decreases or an outbreak ends.
Trains CDC's staff on new tools. EDAV hosts a Data Academy that offers training designed to help our workforce build their data science skills, including self-paced courses in Power BI, R, Socrata, Tableau, Databricks, Azure Data Factory, and more.
Changes how CDC works. For the first time, EDAV offers CDC's experts a common set of tools that can be used for any disease or condition. It's ready to handle "big data," can bring in entirely new sources of data like social media feeds, and enables CDC's scientists to create interactive dashboards and apply technologies like artificial intelligence for deeper analysis.
4 notes
·
View notes
Text
Google Cloud’s BigQuery Autonomous Data To AI Platform

BigQuery automates data analysis, transformation, and insight generation using AI. AI and natural language interaction simplify difficult operations.
The fast-paced world needs data access and a real-time data activation flywheel. Artificial intelligence that integrates directly into the data environment and works with intelligent agents is emerging. These catalysts open doors and enable self-directed, rapid action, which is vital for success. This flywheel uses Google's Data & AI Cloud to activate data in real time. BigQuery has five times more organisations than the two leading cloud providers that just offer data science and data warehousing solutions due to this emphasis.
Examples of top companies:
With BigQuery, Radisson Hotel Group enhanced campaign productivity by 50% and revenue by over 20% by fine-tuning the Gemini model.
By connecting over 170 data sources with BigQuery, Gordon Food Service established a scalable, modern, AI-ready data architecture. This improved real-time response to critical business demands, enabled complete analytics, boosted client usage of their ordering systems, and offered staff rapid insights while cutting costs and boosting market share.
J.B. Hunt is revolutionising logistics for shippers and carriers by integrating Databricks into BigQuery.
General Mills saves over $100 million using BigQuery and Vertex AI to give workers secure access to LLMs for structured and unstructured data searches.
Google Cloud is unveiling many new features with its autonomous data to AI platform powered by BigQuery and Looker, a unified, trustworthy, and conversational BI platform:
New assistive and agentic experiences based on your trusted data and available through BigQuery and Looker will make data scientists, data engineers, analysts, and business users' jobs simpler and faster.
Advanced analytics and data science acceleration: Along with seamless integration with real-time and open-source technologies, BigQuery AI-assisted notebooks improve data science workflows and BigQuery AI Query Engine provides fresh insights.
Autonomous data foundation: BigQuery can collect, manage, and orchestrate any data with its new autonomous features, which include native support for unstructured data processing and open data formats like Iceberg.
Look at each change in detail.
User-specific agents
It believes everyone should have AI. BigQuery and Looker made AI-powered helpful experiences generally available, but Google Cloud now offers specialised agents for all data chores, such as:
Data engineering agents integrated with BigQuery pipelines help create data pipelines, convert and enhance data, discover anomalies, and automate metadata development. These agents provide trustworthy data and replace time-consuming and repetitive tasks, enhancing data team productivity. Data engineers traditionally spend hours cleaning, processing, and confirming data.
The data science agent in Google's Colab notebook enables model development at every step. Scalable training, intelligent model selection, automated feature engineering, and faster iteration are possible. This agent lets data science teams focus on complex methods rather than data and infrastructure.
Looker conversational analytics lets everyone utilise natural language with data. Expanded capabilities provided with DeepMind let all users understand the agent's actions and easily resolve misconceptions by undertaking advanced analysis and explaining its logic. Looker's semantic layer boosts accuracy by two-thirds. The agent understands business language like “revenue” and “segments” and can compute metrics in real time, ensuring trustworthy, accurate, and relevant results. An API for conversational analytics is also being introduced to help developers integrate it into processes and apps.
In the BigQuery autonomous data to AI platform, Google Cloud introduced the BigQuery knowledge engine to power assistive and agentic experiences. It models data associations, suggests business vocabulary words, and creates metadata instantaneously using Gemini's table descriptions, query histories, and schema connections. This knowledge engine grounds AI and agents in business context, enabling semantic search across BigQuery and AI-powered data insights.
All customers may access Gemini-powered agentic and assistive experiences in BigQuery and Looker without add-ons in the existing price model tiers!
Accelerating data science and advanced analytics
BigQuery autonomous data to AI platform is revolutionising data science and analytics by enabling new AI-driven data science experiences and engines to manage complex data and provide real-time analytics.
First, AI improves BigQuery notebooks. It adds intelligent SQL cells to your notebook that can merge data sources, comprehend data context, and make code-writing suggestions. It also uses native exploratory analysis and visualisation capabilities for data exploration and peer collaboration. Data scientists can also schedule analyses and update insights. Google Cloud also lets you construct laptop-driven, dynamic, user-friendly, interactive data apps to share insights across the organisation.
This enhanced notebook experience is complemented by the BigQuery AI query engine for AI-driven analytics. This engine lets data scientists easily manage organised and unstructured data and add real-world context—not simply retrieve it. BigQuery AI co-processes SQL and Gemini, adding runtime verbal comprehension, reasoning skills, and real-world knowledge. Their new engine processes unstructured photographs and matches them to your product catalogue. This engine supports several use cases, including model enhancement, sophisticated segmentation, and new insights.
Additionally, it provides users with the most cloud-optimized open-source environment. Google Cloud for Apache Kafka enables real-time data pipelines for event sourcing, model scoring, communications, and analytics in BigQuery for serverless Apache Spark execution. Customers have almost doubled their serverless Spark use in the last year, and Google Cloud has upgraded this engine to handle data 2.7 times faster.
BigQuery lets data scientists utilise SQL, Spark, or foundation models on Google's serverless and scalable architecture to innovate faster without the challenges of traditional infrastructure.
An independent data foundation throughout data lifetime
An independent data foundation created for modern data complexity supports its advanced analytics engines and specialised agents. BigQuery is transforming the environment by making unstructured data first-class citizens. New platform features, such as orchestration for a variety of data workloads, autonomous and invisible governance, and open formats for flexibility, ensure that your data is always ready for data science or artificial intelligence issues. It does this while giving the best cost and decreasing operational overhead.
For many companies, unstructured data is their biggest untapped potential. Even while structured data provides analytical avenues, unique ideas in text, audio, video, and photographs are often underutilised and discovered in siloed systems. BigQuery instantly tackles this issue by making unstructured data a first-class citizen using multimodal tables (preview), which integrate structured data with rich, complex data types for unified querying and storage.
Google Cloud's expanded BigQuery governance enables data stewards and professionals a single perspective to manage discovery, classification, curation, quality, usage, and sharing, including automatic cataloguing and metadata production, to efficiently manage this large data estate. BigQuery continuous queries use SQL to analyse and act on streaming data regardless of format, ensuring timely insights from all your data streams.
Customers utilise Google's AI models in BigQuery for multimodal analysis 16 times more than last year, driven by advanced support for structured and unstructured multimodal data. BigQuery with Vertex AI are 8–16 times cheaper than independent data warehouse and AI solutions.
Google Cloud maintains open ecology. BigQuery tables for Apache Iceberg combine BigQuery's performance and integrated capabilities with the flexibility of an open data lakehouse to link Iceberg data to SQL, Spark, AI, and third-party engines in an open and interoperable fashion. This service provides adaptive and autonomous table management, high-performance streaming, auto-AI-generated insights, practically infinite serverless scalability, and improved governance. Cloud storage enables fail-safe features and centralised fine-grained access control management in their managed solution.
Finaly, AI platform autonomous data optimises. Scaling resources, managing workloads, and ensuring cost-effectiveness are its competencies. The new BigQuery spend commit unifies spending throughout BigQuery platform and allows flexibility in shifting spend across streaming, governance, data processing engines, and more, making purchase easier.
Start your data and AI adventure with BigQuery data migration. Google Cloud wants to know how you innovate with data.
#technology#technews#govindhtech#news#technologynews#BigQuery autonomous data to AI platform#BigQuery#autonomous data to AI platform#BigQuery platform#autonomous data#BigQuery AI Query Engine
2 notes
·
View notes
Text
Datasets Matter: The Battle Between Open and Closed Generative AI is Not Only About Models Anymore
New Post has been published on https://thedigitalinsider.com/datasets-matter-the-battle-between-open-and-closed-generative-ai-is-not-only-about-models-anymore/
Datasets Matter: The Battle Between Open and Closed Generative AI is Not Only About Models Anymore
Two major open source datasets were released this week.
Created Using DALL-E
Next Week in The Sequence:
Edge 403: Our series about autonomous agents continues covering memory-based planning methods. The research behind the TravelPlanner benchmark for planning in LLMs and the impressive MemGPT framework for autonomous agents.
The Sequence Chat: A super cool interview with one of the engineers behind Azure OpenAI Service and Microsoft CoPilot.
Edge 404: We dive into Meta AI’s amazing research for predicting multiple tokens at the same time in LLMs.
You can subscribe to The Sequence below:
TheSequence is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
📝 Editorial: Datasets Matter: The Battle Between Open and Closed Generative AI is Not Only About Models Anymore
The battle between open and closed generative AI has been at the center of industry developments. From the very beginning, the focus has been on open vs. closed models, such as Mistral and Llama vs. GPT-4 and Claude. Less attention has been paid to other foundational aspects of the model lifecycle, such as the datasets used for training and fine-tuning. In fact, one of the limitations of the so-called open weight models is that they don’t disclose the training datasets and pipeline. What if we had high-quality open source datasets that rival those used to pretrain massive foundation models?
Open source datasets are one of the key aspects to unlocking innovation in generative AI. The costs required to build multi-trillion token datasets are completely prohibitive to most organizations. Leading AI labs, such as the Allen AI Institute, have been at the forefront of this idea, regularly open sourcing high-quality datasets such as the ones used for the Olmo model. Now it seems that they are getting some help.
This week, we saw two major efforts related to open source generative AI datasets. Hugging Face open-sourced FineWeb, a 44TB dataset of 15 trillion tokens derived from 96 CommonCrawl snapshots. Hugging Face also released FineWeb-Edu, a subset of FineWeb focused on educational value. But Hugging Face was not the only company actively releasing open source datasets. Complementing the FineWeb release, AI startup Zyphra released Zyda, a 1.3 trillion token dataset for language modeling. The construction of Zyda seems to have focused on a very meticulous filtering and deduplication process and shows remarkable performance compared to other datasets such as Dolma or RedefinedWeb.
High-quality open source datasets are paramount to enabling innovation in open generative models. Researchers using these datasets can now focus on pretraining pipelines and optimizations, while teams using those models for fine-tuning or inference can have a clearer way to explain outputs based on the composition of the dataset. The battle between open and closed generative AI is not just about models anymore.
🔎 ML Research
Extracting Concepts from GPT-4
OpenAI published a paper proposing an interpretability technique to understanding neural activity within LLMs. Specifically, the method uses k-sparse autoencoders to control sparsity which leads to more interpretable models —> Read more.
Transformer are SSMs
Researchers from Princeton University and Carnegie Mellon University published a paper outlining theoretical connections between transformers and SSMs. The paper also proposes a framework called state space duality and a new architecture called Mamba-2 which improves the performance over its predecessors by 2-8x —> Read more.
Believe or Not Believe LLMs
Google DeepMind published a paper proposing a technique to quantify uncertainty in LLM responses. The paper explores different sources of uncertainty such as lack of knowledge and randomness in order to quantify the reliability of an LLM output —> Read more.
CodecLM
Google Research published a paper introducing CodecLM, a framework for using synthetic data for LLM alignment in downstream tasks. CodecLM leverages LLMs like Gemini to encode seed intrstructions into the metadata and then decodes it into synthetic intstructions —> Read more.
TinyAgent
Researchers from UC Berkeley published a detailed blog post about TinyAgent, a function calling tuning method for small language models. TinyAgent aims to enable function calling LLMs that can run on mobile or IoT devices —> Read more.
Parrot
Researchers from Shanghai Jiao Tong University and Microsoft Research published a paper introducing Parrot, a framework for correlating multiple LLM requests. Parrot uses the concept of a Semantic Variable to annotate input/output variables in LLMs to enable the creation of a data pipeline with LLMs —> Read more.
🤖 Cool AI Tech Releases
FineWeb
HuggingFace open sourced FineWeb, a 15 trillion token dataset for LLM training —> Read more.
Stable Audion Open
Stability AI open source Stable Audio Open, its new generative audio model —> Read more.
Mistral Fine-Tune
Mistral open sourced mistral-finetune SDK and services for fine-tuning models programmatically —> Read more.
Zyda
Zyphra Technologies open sourced Zyda, a 1.3 trillion token dataset that powers the version of its Zamba models —> Read more.
🛠 Real World AI
Salesforce discusses their use of Amazon SageMaker in their Einstein platform —> Read more.
📡AI Radar
Cisco announced a $1B AI investment fund with some major positions in companies like Cohere, Mistral and Scale AI.
Cloudera acquired AI startup Verta.
Databricks acquired data management company Tabular.
Tektonic, raised $10 million to build generative agents for business operations —> Read more.
AI task management startup Hoop raised $5 million.
Galileo announced Luna, a family of evaluation foundation models.
Browserbase raised $6.5 million for its LLM browser-based automation platform.
AI artwork platform Exactly.ai raised $4.3 million.
Sirion acquired AI document management platform Eigen Technologies.
Asana added AI teammates to complement task management capabilities.
Eyebot raised $6 million for its AI-powered vision exams.
AI code base platform Greptile raised a $4 million seed round.
TheSequence is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
#agents#ai#AI-powered#amazing#Amazon#architecture#Asana#attention#audio#automation#automation platform#autonomous agents#azure#azure openai#benchmark#Blog#browser#Business#Carnegie Mellon University#claude#code#Companies#Composition#construction#data#Data Management#data pipeline#databricks#datasets#DeepMind
0 notes
Text
Move over, Salesforce and Microsoft! Databricks is shaking things up with their game-changing AI/BI tool. Get ready for smarter, faster insights that leave the competition in the dust.
Who's excited to see what this powerhouse can do?
2 notes
·
View notes
Text
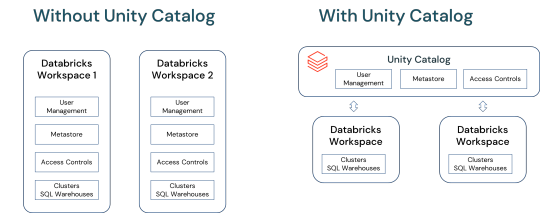
Unlocking Full Potential: The Compelling Reasons to Migrate to Databricks Unity Catalog
In a world overwhelmed by data complexities and AI advancements, Databricks Unity Catalog emerges as a game-changer. This blog delves into how Unity Catalog revolutionizes data and AI governance, offering a unified, agile solution .
View On WordPress
#Access Control in Data Platforms#Advanced User Management#AI and ML Data Governance#AI Data Management#Big Data Solutions#Centralized Metadata Management#Cloud Data Management#Data Collaboration Tools#Data Ecosystem Integration#Data Governance Solutions#Data Lakehouse Architecture#Data Platform Modernization#Data Security and Compliance#Databricks for Data Scientists#Databricks Unity catalog#Enterprise Data Strategy#Migrating to Unity Catalog#Scalable Data Architecture#Unity Catalog Features
0 notes
Text
Azure Data Factory Training In Hyderabad
Key Features:
Hybrid Data Integration: Azure Data Factory supports hybrid data integration, allowing users to connect and integrate data from on-premises sources, cloud-based services, and various data stores. This flexibility is crucial for organizations with diverse data ecosystems.
Intuitive Visual Interface: The platform offers a user-friendly, visual interface for designing and managing data pipelines. Users can leverage a drag-and-drop interface to effortlessly create, monitor, and manage complex data workflows without the need for extensive coding expertise.

Data Movement and Transformation: Data movement is streamlined with Azure Data Factory, enabling the efficient transfer of data between various sources and destinations. Additionally, the platform provides a range of data transformation activities, such as cleansing, aggregation, and enrichment, ensuring that data is prepared and optimized for analysis.
Data Orchestration: Organizations can orchestrate complex workflows by chaining together multiple data pipelines, activities, and dependencies. This orchestration capability ensures that data processes are executed in a logical and efficient sequence, meeting business requirements and compliance standards.
Integration with Azure Services: Azure Data Factory seamlessly integrates with other Azure services, including Azure Synapse Analytics, Azure Databricks, Azure Machine Learning, and more. This integration enhances the platform's capabilities, allowing users to leverage additional tools and services to derive deeper insights from their data.
Monitoring and Management: Robust monitoring and management capabilities provide real-time insights into the performance and health of data pipelines. Users can track execution details, diagnose issues, and optimize workflows to enhance overall efficiency.
Security and Compliance: Azure Data Factory prioritizes security and compliance, implementing features such as Azure Active Directory integration, encryption at rest and in transit, and role-based access control. This ensures that sensitive data is handled securely and in accordance with regulatory requirements.
Scalability and Reliability: The platform is designed to scale horizontally, accommodating the growing needs of organizations as their data volumes increase. With built-in reliability features, Azure Data Factory ensures that data processes are executed consistently and without disruptions.
2 notes
·
View notes
Text
From Math to Machine Learning: A Comprehensive Blueprint for Aspiring Data Scientists
The realm of data science is vast and dynamic, offering a plethora of opportunities for those willing to dive into the world of numbers, algorithms, and insights. If you're new to data science and unsure where to start, fear not! This step-by-step guide will navigate you through the foundational concepts and essential skills to kickstart your journey in this exciting field. Choosing the Best Data Science Institute can further accelerate your journey into this thriving industry.

1. Establish a Strong Foundation in Mathematics and Statistics
Before delving into the specifics of data science, ensure you have a robust foundation in mathematics and statistics. Brush up on concepts like algebra, calculus, probability, and statistical inference. Online platforms such as Khan Academy and Coursera offer excellent resources for reinforcing these fundamental skills.
2. Learn Programming Languages
Data science is synonymous with coding. Choose a programming language – Python and R are popular choices – and become proficient in it. Platforms like Codecademy, DataCamp, and W3Schools provide interactive courses to help you get started on your coding journey.
3. Grasp the Basics of Data Manipulation and Analysis
Understanding how to work with data is at the core of data science. Familiarize yourself with libraries like Pandas in Python or data frames in R. Learn about data structures, and explore techniques for cleaning and preprocessing data. Utilize real-world datasets from platforms like Kaggle for hands-on practice.
4. Dive into Data Visualization
Data visualization is a powerful tool for conveying insights. Learn how to create compelling visualizations using tools like Matplotlib and Seaborn in Python, or ggplot2 in R. Effectively communicating data findings is a crucial aspect of a data scientist's role.
5. Explore Machine Learning Fundamentals
Begin your journey into machine learning by understanding the basics. Grasp concepts like supervised and unsupervised learning, classification, regression, and key algorithms such as linear regression and decision trees. Platforms like scikit-learn in Python offer practical, hands-on experience.
6. Delve into Big Data Technologies
As data scales, so does the need for technologies that can handle large datasets. Familiarize yourself with big data technologies, particularly Apache Hadoop and Apache Spark. Platforms like Cloudera and Databricks provide tutorials suitable for beginners.
7. Enroll in Online Courses and Specializations
Structured learning paths are invaluable for beginners. Enroll in online courses and specializations tailored for data science novices. Platforms like Coursera ("Data Science and Machine Learning Bootcamp with R/Python") and edX ("Introduction to Data Science") offer comprehensive learning opportunities.
8. Build Practical Projects
Apply your newfound knowledge by working on practical projects. Analyze datasets, implement machine learning models, and solve real-world problems. Platforms like Kaggle provide a collaborative space for participating in data science competitions and showcasing your skills to the community.
9. Join Data Science Communities
Engaging with the data science community is a key aspect of your learning journey. Participate in discussions on platforms like Stack Overflow, explore communities on Reddit (r/datascience), and connect with professionals on LinkedIn. Networking can provide valuable insights and support.
10. Continuous Learning and Specialization
Data science is a field that evolves rapidly. Embrace continuous learning and explore specialized areas based on your interests. Dive into natural language processing, computer vision, or reinforcement learning as you progress and discover your passion within the broader data science landscape.

Remember, your journey in data science is a continuous process of learning, application, and growth. Seek guidance from online forums, contribute to discussions, and build a portfolio that showcases your projects. Choosing the best Data Science Courses in Chennai is a crucial step in acquiring the necessary expertise for a successful career in the evolving landscape of data science. With dedication and a systematic approach, you'll find yourself progressing steadily in the fascinating world of data science. Good luck on your journey!
3 notes
·
View notes
Text
Elon Musk’s so-called Department of Government Efficiency (DOGE) has plans to stage a “hackathon” next week in Washington, DC. The goal is to create a single “mega API”—a bridge that lets software systems talk to one another—for accessing IRS data, sources tell WIRED. The agency is expected to partner with a third-party vendor to manage certain aspects of the data project. Palantir, a software company cofounded by billionaire and Musk associate Peter Thiel, has been brought up consistently by DOGE representatives as a possible candidate, sources tell WIRED.
Two top DOGE operatives at the IRS, Sam Corcos and Gavin Kliger, are helping to orchestrate the hackathon, sources tell WIRED. Corcos is a health-tech CEO with ties to Musk’s SpaceX. Kliger attended UC Berkeley until 2020 and worked at the AI company Databricks before joining DOGE as a special adviser to the director at the Office of Personnel Management (OPM). Corcos is also a special adviser to Treasury Secretary Scott Bessent.
Since joining Musk’s DOGE, Corcos has told IRS workers that he wants to pause all engineering work and cancel current attempts to modernize the agency’s systems, according to sources with direct knowledge who spoke with WIRED. He has also spoken about some aspects of these cuts publicly: "We've so far stopped work and cut about $1.5 billion from the modernization budget. Mostly projects that were going to continue to put us down the death spiral of complexity in our code base," Corcos told Laura Ingraham on Fox News in March.
Corcos has discussed plans for DOGE to build “one new API to rule them all,” making IRS data more easily accessible for cloud platforms, sources say. APIs, or application programming interfaces, enable different applications to exchange data, and could be used to move IRS data into the cloud. The cloud platform could become the “read center of all IRS systems,” a source with direct knowledge tells WIRED, meaning anyone with access could view and possibly manipulate all IRS data in one place.
Over the last few weeks, DOGE has requested the names of the IRS’s best engineers from agency staffers. Next week, DOGE and IRS leadership are expected to host dozens of engineers in DC so they can begin “ripping up the old systems” and building the API, an IRS engineering source tells WIRED. The goal is to have this task completed within 30 days. Sources say there have been multiple discussions about involving third-party cloud and software providers like Palantir in the implementation.
Corcos and DOGE indicated to IRS employees that they intended to first apply the API to the agency’s mainframes and then move on to every other internal system. Initiating a plan like this would likely touch all data within the IRS, including taxpayer names, addresses, social security numbers, as well as tax return and employment data. Currently, the IRS runs on dozens of disparate systems housed in on-premises data centers and in the cloud that are purposefully compartmentalized. Accessing these systems requires special permissions and workers are typically only granted access on a need-to-know basis.
A “mega API” could potentially allow someone with access to export all IRS data to the systems of their choosing, including private entities. If that person also had access to other interoperable datasets at separate government agencies, they could compare them against IRS data for their own purposes.
“Schematizing this data and understanding it would take years,” an IRS source tells WIRED. “Just even thinking through the data would take a long time, because these people have no experience, not only in government, but in the IRS or with taxes or anything else.” (“There is a lot of stuff that I don't know that I am learning now,” Corcos tells Ingraham in the Fox interview. “I know a lot about software systems, that's why I was brought in.")
These systems have all gone through a tedious approval process to ensure the security of taxpayer data. Whatever may replace them would likely still need to be properly vetted, sources tell WIRED.
"It's basically an open door controlled by Musk for all American's most sensitive information with none of the rules that normally secure that data," an IRS worker alleges to WIRED.
The data consolidation effort aligns with President Donald Trump’s executive order from March 20, which directed agencies to eliminate information silos. While the order was purportedly aimed at fighting fraud and waste, it also could threaten privacy by consolidating personal data housed on different systems into a central repository, WIRED previously reported.
In a statement provided to WIRED on Saturday, a Treasury spokesperson said the department “is pleased to have gathered a team of long-time IRS engineers who have been identified as the most talented technical personnel. Through this coalition, they will streamline IRS systems to create the most efficient service for the American taxpayer. This week the team will be participating in the IRS Roadmapping Kickoff, a seminar of various strategy sessions, as they work diligently to create efficient systems. This new leadership and direction will maximize their capabilities and serve as the tech-enabled force multiplier that the IRS has needed for decades.”
Palantir, Sam Corcos, and Gavin Kliger did not immediately respond to requests for comment.
In February, a memo was drafted to provide Kliger with access to personal taxpayer data at the IRS, The Washington Post reported. Kliger was ultimately provided read-only access to anonymized tax data, similar to what academics use for research. Weeks later, Corcos arrived, demanding detailed taxpayer and vendor information as a means of combating fraud, according to the Post.
“The IRS has some pretty legacy infrastructure. It's actually very similar to what banks have been using. It's old mainframes running COBOL and Assembly and the challenge has been, how do we migrate that to a modern system?” Corcos told Ingraham in the same Fox News interview. Corcos said he plans to continue his work at IRS for a total of six months.
DOGE has already slashed and burned modernization projects at other agencies, replacing them with smaller teams and tighter timelines. At the Social Security Administration, DOGE representatives are planning to move all of the agency’s data off of legacy programming languages like COBOL and into something like Java, WIRED reported last week.
Last Friday, DOGE suddenly placed around 50 IRS technologists on administrative leave. On Thursday, even more technologists were cut, including the director of cybersecurity architecture and implementation, deputy chief information security officer, and acting director of security risk management. IRS’s chief technology officer, Kaschit Pandya, is one of the few technology officials left at the agency, sources say.
DOGE originally expected the API project to take a year, multiple IRS sources say, but that timeline has shortened dramatically down to a few weeks. “That is not only not technically possible, that's also not a reasonable idea, that will cripple the IRS,” an IRS employee source tells WIRED. “It will also potentially endanger filing season next year, because obviously all these other systems they’re pulling people away from are important.”
(Corcos also made it clear to IRS employees that he wanted to kill the agency’s Direct File program, the IRS’s recently released free tax-filing service.)
DOGE’s focus on obtaining and moving sensitive IRS data to a central viewing platform has spooked privacy and civil liberties experts.
“It’s hard to imagine more sensitive data than the financial information the IRS holds,” Evan Greer, director of Fight for the Future, a digital civil rights organization, tells WIRED.
Palantir received the highest FedRAMP approval this past December for its entire product suite, including Palantir Federal Cloud Service (PFCS) which provides a cloud environment for federal agencies to implement the company’s software platforms, like Gotham and Foundry. FedRAMP stands for Federal Risk and Authorization Management Program and assesses cloud products for security risks before governmental use.
“We love disruption and whatever is good for America will be good for Americans and very good for Palantir,” Palantir CEO Alex Karp said in a February earnings call. “Disruption at the end of the day exposes things that aren't working. There will be ups and downs. This is a revolution, some people are going to get their heads cut off.”
15 notes
·
View notes