#python – How can I sort a dictionary by key
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Premium Tumblr themes are available from anywhere between $9 to $49.
Text
python – How can I sort a dictionary by key
Standard Python dictionaries are unordered (until Python 3.7). Even if you sorted the (key,value) pairs, you wouldnt be able to store them in a dict in a way that would preserve the ordering.
The easiest way is to use OrderedDict, which remembers the order in which the elements have been inserted:
0 notes
Note
Okay okay. Headcanon for you. So Bruce just being Done With Everything is damn hilarious, especially to his sons. My headcanon is that they have their own secret little competitions to see who can get him the Most Done. Surprisingly? Tim has won twice in a row.
Bruce being Done is my favorite! 😂 I like the way you think @nxxttime
—
Unsurprisingly, it was Dick and Jason who started the game with the simple question: ‘just how many Space Jam references can I fit into this League Briefing before B loses it in front of all his Super Friends?’ (answer: 13)
And from there, it all just sort of escalated.
Batman is Tired™ and Done™ 105% of the time, but getting a rise out of him is surprisingly rare. Cracking the stoic man like an egg is one of the kids’ favorite pastimes, but while it’s fun to see their dad Lose It…bonus points are given for the I Give Up Face.
What is the I Give Up Face, you may ask? Simple: It’s what happens with Bruce Wayne has transcended anger and annoyance completely and is now on a whole ‘nother plane of apathy. It’s a beautiful thing to see.
And every Batkid has one objective–to be the first person to get the poor man to make that spiritual transition.
As a rule, Dick goes errs on the side of subtlety–little buttons that he just knows to press in order to get a rise out of Bruce. Thrown-in references, irksome words and phrases (i.e. moist, slurp, lugubrious, etc. Alfred got him a dictionary for Christmas, and Bruce’s jaw almost popped out of alignment.) But when he’s in the mood for something a little more noticeable, he sings pop songs off-key over the comms or in Bruce’s ear while he’s trying to study case files. (The most effective ones include Toxic, Call Me Maybe, Mama Mia, and anything by Ke$ha) He’s also not above poking Bruce when he’s being ignored.
Jason, though he can be subtle when the situation calls for it, absolutely thrives on brute force. How many times can he shove Damian off a roof or toss Tim out a window before Bruce busts a blood vessel or five? How many times can he go ‘undercover’ wearing nothing but street clothes and a stick-on dollar-store mustache before he makes his dad look into the camera like he’s on the Office? How many times can he leak ‘confidential information’ to the press in the form of macaroni art and Cut-And-Paste notes before incurring Bruce’s wrathful frustration? The answer might surprise you.
Barbara’s method involves strategy and finesse. For instance, why send Bruce that data he asked for right off the bat (pardon the pun) when she could send a blank file with this:

Or even with this gif, if she’s feeling particularly devious:

Admittedly, Barbara’s the one who gets the least I Give Up Faces out of Bruce. But she gets bonus points for getting him to scream the loudest. The man’s lost five phones to the Gotham City Streets after throwing them in blinding fits of rage.
Damian is like a cat, in that his strategy involves metaphorically placing his finger on Bruce’s metaphorical coffee mug and slowly edging it off his metaphorical desk.
Never. Breaking. Eye. Contact.
He does this with almost everything. Deliberately breaking rules or bending guidelines in just the right way. Pressing that button. Flipping that switch. Diving off that building. All as he makes absolutely certain that Bruce is there to watch him do it. For Damian, it’s all in the eye-contact. The forceful, yet silent declaration of ‘I can do whatever I want, and there’s not a thing you can do to stop me, father,’ is one of the most surefire ways to get Bruce to Lose It.
Cass is Bruce’s sweet angel child, and would never do any of this to him!
(She totally has, but nothing they can prove. Nothing’s ever been successfully traced back to her.)
Duke’s backtalk is usually Guaranteed to get the I Give Up Face. Not that it’s disrespectful or overly snarky–quite the opposite, in fact. No, no. It’s phrases like ‘I see your point, but why do we have to jump off a roof. Wouldn’t jetpacks make more sense?’ or ‘Maybe I’m wrong, but the giant dinosaur’s kind of an eye-sore, don’t you think?’ that send Bruce off into a dissociating silence.
Duke is 100% aware of what he’s doing, but he gets supreme satisfaction from the ‘naively innocent’ routine. The key is to say his piece at just the right moment. Duke is exceptionally good at gauging Bruce’s level of volatility. So much so, that his new siblings will often come to him to ask just how far away Bruce is from the tipping point.
Stephanie is a ‘Jack of All Trades’, you might say. She picks and chooses from her siblings’ strategies and methods. And then she amps up the ante. To Steph, ‘bigger is better’ isn’t just a turn of phrase–it’s gospel.
Dick’s blasting ‘Dancing Queen’ over the comms? Cool, cool, but what if we broad-casted it over the League’s party line at ten times the volume? Jason’s coated the batarangs with pink glitter? Let’s set a spring-loaded trigger in the Batmobile, rigged with forty-eight pounds of the stuff. Barbara’s screwing with Bruce’s data feed? Hack his visual feed with an eighteen-hour loop of Rick Astley’s Never Gonna Give You Up.
Out of all of them, Stephanie is the one with the most I Give Up Face wins.
But Tim?
Tim is a force of chaos that is not to be trifled with. As unpredictable as the elements, and twice as frightening when the occasion calls for it. The only reason that he doesn’t have the most wins is simply because he never actively participates in the game. But he’s done everything from sleepwalking, to publicly embarrassing Bruce, to T-Posing in places where he shouldn’t. (i.e. on top of a GCPD patrol car or barrel of toxic chemicals.)
Twice, Tim committed acts that triggered the I Give Up Face so quickly, so completely, that the others could only gape, and declare him the winner.
The first was during a bank robbery. The gun-toting thieves pointed their weapons at Batman, Nightwing, and Red Robin and screamed, “Don’t move or we’ll shoot!”
Tim proceeded to Fortnite Dance enthusiastically.
Bruce could only stare off into the distance (the thugs were watching, transfixed, with expressions of horrified fascination) and contemplate his life choices. After the fact, Dick swore to anyone who’d listen that he’d never seen Bruce dissociate that quickly.
The second time it happened, Tim was once again on Live Television (a foolish decision that the Wayne Enterprises higher-ups have finally learned from and vowed never to repeat). He was supposed to be giving a speech, but instead, blankly stared at the crowd, and proceeded to recite the entire script of the 1975 cinematic classic, Monty Python and the Holy Grail. Tim refused to be removed from the stand, and managed to fight off security while somehow keeping his mouth close to the mic.
Bruce came to terms with the fact years ago: he may lead a dangerous life. He may put his life on the line daily, nightly, and every moment in between. But it won’t be the villains or the thugs that finally kill him–
–it’ll be his children.
#batfam#dc#batfamily#batman headcanons#bruce wayne#batman#dick grayson#nightwing#red hood#jason todd#stephanie brown#spoiler#cassandra cain#batgirl#barbara gordon#oracle#damian wayne#robin#duke thomas#signal#thanks @nxxttime!#this was really fun#i know you said just the boys#but i couldn't resist
2K notes
·
View notes
Text
Version 324
youtube
windows
zip
exe
os x
app
tar.gz
linux
tar.gz
source
tar.gz
I had a great week. The downloader overhaul is almost done.
pixiv
Just as Pixiv recently moved their art pages to a new phone-friendly, dynamically drawn format, they are now moving their regular artist gallery results to the same system. If your username isn't switched over yet, it likely will be in the coming week.
The change breaks our old html parser, so I have written a new downloader and json api parser. The way their internal api works is unusual and over-complicated, so I had to write a couple of small new tools to get it to work. However, it does seem to work again.
All of your subscriptions and downloaders will try to switch over to the new downloader automatically, but some might not handle it quite right, in which case you will have to go into edit subscriptions and update their gallery manually. You'll get a popup on updating to remind you of this, and if any don't line up right automatically, the subs will notify you when they next run. The api gives all content--illustrations, manga, ugoira, everything--so there unfortunately isn't a simple way to refine to just one content type as we previously could. But it does neatly deliver everything in just one request, so artist searching is now incredibly faster.
Let me know if pixiv gives any more trouble. Now we can parse their json, we might be able to reintroduce the arbitrary tag search, which broke some time ago due to the same move to javascript galleries.
twitter
In a similar theme, given our fully developed parser and pipeline, I have now wangled a twitter username search! It should be added to your downloader list on update. It is a bit hacky and may be ultimately fragile if they change something their end, but it otherwise works great. It discounts retweets and fetches 19/20 tweets per gallery 'page' fetch. You should be able to set up subscriptions and everything, although I generally recommend you go at it slowly until we know this new parser works well. BTW: I think twitter only 'browses' 3200 tweets in the past, anyway. Note that tweets with no images will be 'ignored', so any typical twitter search will end up with a lot of 'Ig' results--this is normal. Also, if the account ever retweets more than 20 times in a row, the search will stop there, due to how the clientside pipeline works (it'll think that page is empty).
Again, let me know how this works for you. This is some fun new stuff for hydrus, and I am interested to see where it does well and badly.
misc
In order to be less annoying, the 'do you want to run idle jobs?' on shutdown dialog will now only ask at most once per day! You can edit the time unit under options->maintenance and processing.
Under options->connection, you can now change max total network jobs globally and per domain. The defaults are 15 and 3. I don't recommend you increase them unless you know what you are doing, but if you want a slower/more cautious client, please do set them lower.
The new advanced downloader ui has a bunch of quality of life improvements, mostly related to the handling of example parseable data.
full list
downloaders:
after adding some small new parser tools, wrote a new pixiv downloader that should work with their new dynamic gallery's api. it fetches all an artist's work in one page. some existing pixiv download components will be renamed and detached from your existing subs and downloaders. your existing subs may switch over to the correct pixiv downloader automatically, or you may need to manually set them (you'll get a popup to remind you).
wrote a twitter username lookup downloader. it should skip retweets. it is a bit hacky, so it may collapse if they change something small with their internal javascript api. it fetches 19-20 tweets per 'page', so if the account has 20 rts in a row, it'll likely stop searching there. also, afaik, twitter browsing only works back 3200 tweets or so. I recommend proceeding slowly.
added a simple gelbooru 0.1.11 file page parser to the defaults. it won't link to anything by default, but it is there if you want to put together some booru.org stuff
you can now set your default/favourite download source under options->downloading
.
misc:
the 'do idle work on shutdown' system will now only ask/run once per x time units (including if you say no to the ask dialog). x is one day by default, but can be set in 'maintenance and processing'
added 'max jobs' and 'max jobs per domain' to options->connection. defaults remain 15 and 3
the colour selection buttons across the program now have a right-click menu to import/export #FF0000 hex codes from/to the clipboard
tag namespace colours and namespace rendering options are moved from 'colours' and 'tags' options pages to 'tag summaries', which is renamed to 'tag presentation'
the Lain import dropper now supports pngs with single gugs, url classes, or parsers--not just fully packaged downloaders
fixed an issue where trying to remove a selection of files from the duplicate system (through the advanced duplicates menu) would only apply to the first pair of files
improved some error reporting related to too-long filenames on import
improved error handling for the folder-scanning stage in import folders--now, when it runs into an error, it will preserve its details better, notify the user better, and safely auto-pause the import folder
png export auto-filenames will now be sanitized of \, /, :, *-type OS-path-invalid characters as appropriate as the dialog loads
the 'loading subs' popup message should appear more reliably (after 1s delay) if the first subs are big and loading slow
fixed the 'fullscreen switch' hover window button for the duplicate filter
deleted some old hydrus session management code and db table
some other things that I lost track of. I think it was mostly some little dialog fixes :/
.
advanced downloader stuff:
the test panel on pageparser edit panels now has a 'post pre-parsing conversion' notebook page that shows the given example data after the pre-parsing conversion has occurred, including error information if it failed. it has a summary size/guessed type description and copy and refresh buttons.
the 'raw data' copy/fetch/paste buttons and description are moved down to the raw data page
the pageparser now passes up this post-conversion example data to sub-objects, so they now start with the correctly converted example data
the subsidiarypageparser edit panel now also has a notebook page, also with brief description and copy/refresh buttons, that summarises the raw separated data
the subsidiary page parser now passes up the first post to its sub-objects, so they now start with a single post's example data
content parsers can now sort the strings their formulae get back. you can sort strict lexicographic or the new human-friendly sort that does numbers properly, and of course you can go ascending or descending--if you can get the ids of what you want but they are in the wrong order, you can now easily fix it!
some json dict parsing code now iterates through dict keys lexicographically ascending by default. unfortunately, due to how the python json parser I use works, there isn't a way to process dict items in the original order
the json parsing formula now uses a string match when searching for dictionary keys, so you can now match multiple keys here (as in the pixiv illusts|manga fix). existing dictionary key look-ups will be converted to 'fixed' string matches
the json parsing formula can now get the content type 'dictionary keys', which will fetch all the text keys in the dictionary/Object, if the api designer happens to have put useful data in there, wew
formulae now remove newlines from their parsed texts before they are sent to the StringMatch! so, if you are grabbing some multi-line html and want to test for 'Posted: ' somewhere in that mess, it is now easy.
next week
After slaughtering my downloader overhaul megajob of redundant and completed issues (bringing my total todo from 1568 down to 1471!), I only have 15 jobs left to go. It is mostly some quality of life stuff and refreshing some out of date help. I should be able to clear most of them out next week, and the last few can be folded into normal work.
So I am now planning the login manager. After talking with several users over the past few weeks, I think it will be fundamentally very simple, supporting any basic user/pass web form, and will relegate complicated situations to some kind of improved browser cookies.txt import workflow. I suspect it will take 3-4 weeks to hash out, and then I will be taking four weeks to update to python 3, and then I am a free agent again. So, absent any big problems, please expect the 'next big thing to work on poll' to go up around the end of October, and for me to get going on that next big thing at the end of November. I don't want to finalise what goes on the poll yet, but I'll open up a full discussion as the login manager finishes.
1 note
·
View note
Text
Learn Data Science from Scratch in 2021
According to reports, over 2.5 quantibytes of data is generated every single day. Putting that in perspective, every person of the over 7 billion persons in the world generates over 1.4 MB of data every second. But this data is as good as nothing when left bare. The onus is on data scientists to wrangle the data and distill actionable insights. Perhaps, this is why data science is called the sexiest job of this decade.
What's even more interesting is that the field is open to a lot of freshers. But if you're looking to start a career in data science, a mistake you don't want to make is not having a plan. There are a lot of materials on the web, and you just may get overwhelmed trying to consume all at once.
In this post, I will give you a practical guide on how to learn data science from scratch. Let's get started.
The 3 Important Things You'd Be Needing
There are 3 vital ingredients in becoming a top data scientist:
Some programming knowledge for wrangling data and creating machine learning models
SQL for managing databases, and
A decent knowledge of statistics to understand the concepts that underpin the data transformation process and machine learning algorithms.
Let's take each of them.
1. Programming
If you'd be getting into data science, you'd need to have some programming skills to create models. There are two popular programming languages used for data science; R and Python. I personally am biased towards Python, not just because it is what I use but Python is fairly easy to learn.
Besides, Python is used for many other applications besides data science. This is what makes it popular. Python packs a lot of packages, APIs, and modules for data science.
When learning Python for data science, you may not need all the knowledge of the programming language as it is quite broad. However, there are some concepts in Python you must master. They include
Data types and data structures (lists, dictionaries, tuples, etc)
List slicing and comprehensions
Using os and pickle library
Conditional statements and control flow
Object-Oriented Programming
Once, you’re comfortable with these concepts in Python, you can move on to the next stage.
In the next step, you will need to master libraries for machine learning. Specifically, you will need to fully grasp the use of the following.
Numpy and Pandas for Data Preprocessing
Matplotlib and Seaborn for Data Visualization
Sklearn, Pytorch, Keras, Tensorflow for machine learning model building
When practicing these skills, the place of quality data cannot be overemphasized. You can get interesting datasets from platforms such as Kaggle or UCI Machine Learning Repository. Kaggle and GitHub are also great places to find machine learning models you can practice and use on-the-go.
You will also find great competitions you can jump on in Kaggle. Engaging in these competitions would help you build a solid data science workforce. Furthermore, you’d be exposed to a better approach to solving problems from fellow competitors.
Datasets on Kaggle are however fairly clean data. You may take it a step further by scraping the web for data yourself. These kinds of data are mostly unclean. But it is good practice as this is the nature of data you’d be faced with when solving novel problems. Don’t be scared to try your hands on them.
When you encounter problems with your code, Stack Overflow is a great platform to get help. Finally, H2kinfosys offers a complete course in Data Science that would guide you through this entire process and make you excellent in the skill explained above.
2. SQL
SQL is another vital skill a data scientist must matter. In fact, it is asked the most in most interview sessions. This of course is no coincidence; it goes to show how the skill is in demand in the industry. It is a given that the robustness of your machine learning model is hinged on the kind of data at your disposal. But have you thought about how the data is managed and extracted? SQL.
SQL helps you create a dataset pipeline that is used to organize and sort data based on its relationship with the various features. It can also do extract, transform and load (ETL) operations.
Databases can be classified as relational and nonrelational databases. For relational databases, you will need tools such as MySQL, PostgreSQL, Oracle dataset, etc. MongoDB, Neo4j are common tools to deal with non-relational databases.
The best way to master SQL is by practice. You will need to play around with a lot of datasets and see how you can manage them using SQL. You can start with SQLite as it provides a beginner-friendly experience with its support for a small dataset and less intensive efforts. You may, however, have issues with sources for datasets to practice with. This is the major bottleneck with SQL.
3. Statistics and Linear algebra
Statistics and linear algebra and what kinds of the underlying principles of most machine learning models. What’s more? To build great intuition on how to wrangle data, your statistics and algebra must be impeccable. Well, I’m not saying you've got to get a degree in mathematics. What I'm saying however is that you can't afford to be oblivious of some concepts in mathematics such as linear algebra and statistics.
If you are adventurous, you may want to try to build some of the common ML algorithms such as Linear Regression from scratch. Attempting to build the code from scratch would particularly require a decent knowledge of mathematics.
Let me point out that your efforts would not go unrewarded. Coding machine learning algorithms would give you a high-level intuition on how to optimize the algorithm’s hyperparameter for better performance, making you a unique data scientist.
Again, H2kinfosys has a wide variety of courses that specializes in learning Python, Data Science, and Artificial Intelligence. You will be given all the key resources to jump-start your career in the field. If you want to learn from the best in the field, I would recommend H2kinfosys particularly given that their instructors ride on years of field experience.
Wrapping up,
Let’s talk about mentorship. Mentorship plays a fundamental role in skyrocketing your progress in Data Science. You can approach folks you find fascinated on social media and send them a friendly text, stating that you’d like to be under their tutelage. Be polite, yet confident when addressing them. It is a good idea to highlight some of their previous works that jumped out at you and how you want to give it a shot. You could also get mentorship from the experienced instructors at H2kinfosys once enroll in their class.
Finally, learning data science can be a daunting task as there are a lot of things to cover. However, following this guide would help you cushion the overwhelmingness of its demands and prepare you for what you should expect going forward. Be resolute. Be consistent. Start now.
0 notes
Text
Build SEO seasonality projections with Google Trends in Python
Roadmapping season is upon us and, if you’re an in-house SEO like me, that means it’s time to set your FY20 goals for the SEO channel. To set realistic goals, we first need to understand how much traffic we can reasonably drive from SEO this year. To figure this out, we must first answer a few questions:
How much traffic are we currently driving from SEO?
If we only take seasonality into account, how much traffic will we drive this year?
What impact do we expect from the projects on our roadmap?
This article will help answer some of these questions and tie it all together to set your SEO traffic goal using Python and some very basic Excel functions.
How much traffic are we currently driving from SEO?
Export monthly traffic for the past year from your analytics platform (Google Analytics or Adobe Analytics). Feel free to use whichever metric you think is best. This can be users, visits, sessions, entrances, unique visitors or a different metric that you use. I recommend using whichever metric is most indicative of search behavior. I personally believe that metric is entry visits/entrances from SEO because a user can enter from search multiple times and we want to capture each entrance. Feel free to use whichever metric is your source of truth.
The data should be formatted similar to the table below:
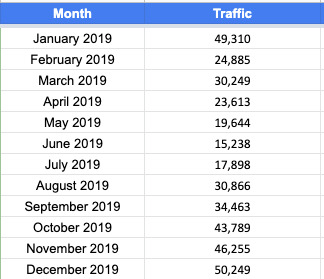
How much traffic will we drive if nothing changes?
This question is generally the hardest to answer. In the past, I’ve seen some people use traffic patterns from prior years to project seasonality but if you’re on any sort of growth trajectory – which I hope you are – this won’t work for you. I recommend an alternative solution: a seasonality index built with Google Trends data.
Google Trends has a wealth of information about search demand. Google Search Console has a wealth of information about the searches that drive traffic to your website. Connect the two and watch the magic happen.
Step 1: Export Google Search Console Data
Navigate to the search performance tab in Search Console. Change the date range to include the last full year. For example: January 1, 2019 – December 31, 2019. Next, sort the queries by clicks so the top-performing keywords are at the top. Finally, export the top 1000 queries to a .csv file.
Note: if you’d like to be more thorough, you can use Google Data Studio or the Search Console API to export all queries for your site.
Step 2: Collect Google Trends Data
A seasonality index is a forecasting tool used to determine demand for certain products or, in this case, search terms in a given market over the course of a typical year. Google Trends is a powerful tool that leverages the data collected by Google Search to quantify interest for a particular search term over time. We will use the past 5 years of Google Trends interest data to predict future interest over the next year in one-week spans.
Since we want this index to be indicative of the seasonal pattern for traffic to our website, we’ll be basing it on the top-performing keywords for our website that we exported from Search Console in step 1. We’ll also be building this index using PyTrends in Python to remove as much manual work as possible.
PyTrends is a pseudo-API (not supported by Google) for Google Trends that allows us to pull data for large amounts of keywords in an automated fashion. I’ve set up a Google Colab notebook that can be used for this example.
First, we’ll install the required modules to run our code.

Next, well import the modules into our Colab notebook.

We’ll require two functions to create our seasonality index. The first, getTrends, will take a keyword and a dictionary object as parameters. This function will call the Google Trends API and append the data to a list stored in the dictionary object using the dates as a key. The second function, average, will be used to calculate the average interest for each date in the dictionary.

Next, we’ll import our dataset of keywords from Search Console. This can be very confusing in Google Colab so I’ve tried to make it as simple as possible. Follow these steps:
Upload your CSV file to Google Drive
Right click on the file, click “Get Shareable Link” and copy the link.
Replace the link in the code with the link to your file.
Run the code. The first time it runs, you’ll be asked to authorize Google Drive access by navigating to an authorization page and logging in with your Google account. It will then give you an authorization code. Copy the code and paste it in the box that appears after running the code and hit enter.
We’ll then convert your CSV file to a Pandas DataFrame.
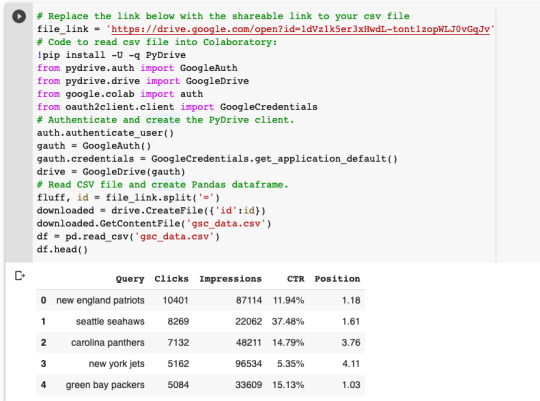
Once we’ve imported our keyword data, we’ll convert the Query column to a list object called keywords. We’ll create an empty dictionary object called data. This is where we will store the Google Trends data. Finally, we’ll iterate over the keyword list to get Google Trends data for each keyword and store it in the data dictionary.

Quick note: Since PyTrends is not an official or Google-supported API, you can run into trouble in this step. I’ve found it best to limit the keyword list to the top 250 queries. Some other steps you can take (which I won’t touch on in this article) are using proxies or adding some random delays in the loop to decrease the chances of being blocked by Google.
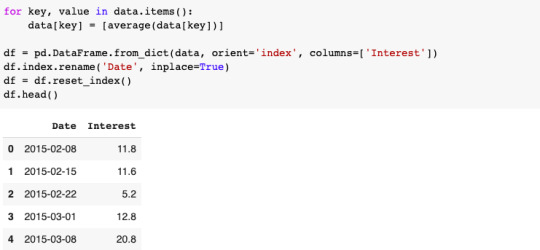
Once we’ve collected all of our Google Trends data, we’ll then calculate average interest over time.
At this point, it can be helpful to plot the results using a time series. We’ll do this using matplotlib.
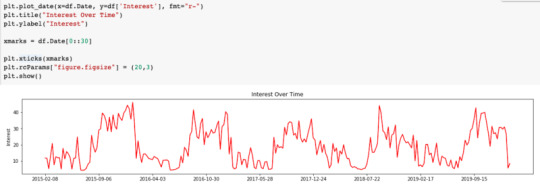
Use this step to verify that the data matches your expectations. Since we’re using NFL teams as our keywords in this example, you’ll notice that the interest peaks during the NFL season and drops off during the off-season. This is what we would expect to happen.
Now, the final step in creating our seasonality index is to group the data by month and convert it to an index. This can be done by calculating the average interest throughout the year and dividing each month’s interest by the average interest.
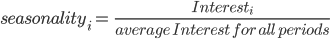
This can be done in Pandas by calculating the mean of the Interest and then dividing each item in the series by the mean.
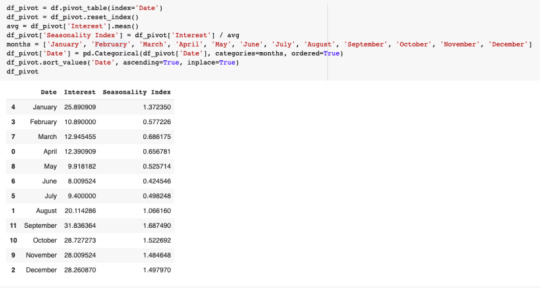
Step 3: Put It All Together in Google Sheets
Now that we have our seasonality index, it’s time to put it to work. This could be done in Python but since we’ll want to be able to change some of the inputs to our projection model, I think it’s easiest to use Google Sheets or Excel.
I have created this Google Sheet as an example.
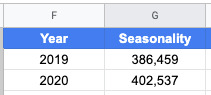
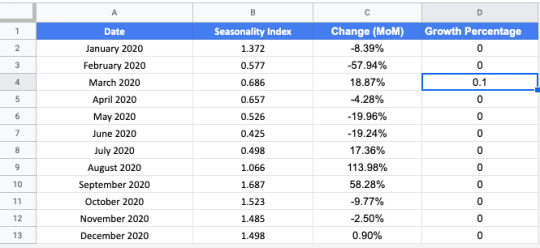
We’ll first create a spreadsheet with our seasonality index and calculate the percentage change from month to month.
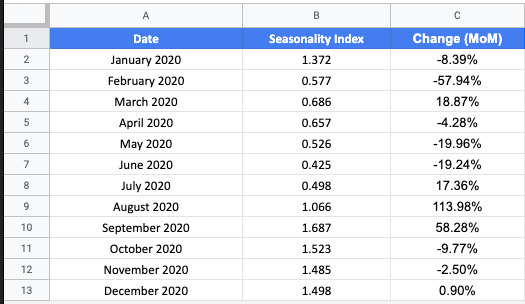
We calculate month over month percentage change using the following function:

In order to calculate the percentage for January, you’ll need to modify the function. Calculate percent change using the formula below.
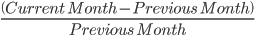
We’ll also create a column for Growth Percentage. This is what we’ll use to model the growth driven by the projects we plan to complete this year. Set the values to 0 for now, we’ll come back to this later.

In a new tab, we’ll add traffic from the past year by month in two columns: Seasonality Projection and Growth Projection. We’ll also continue the Month column to include this year.
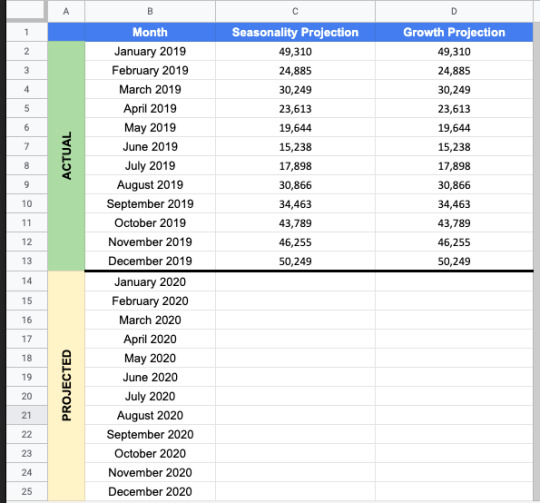
Projecting traffic using seasonality
Now, we’ll use our seasonality index to project monthly traffic based on December’s traffic. This calculation uses the growth percentage in the Seasonality tab in our sheet as follows:


Then, we can drag this function down so it fills in the rest of the months in the year.

If we take the sum of this year, we’ll have our projected annual traffic for 2020.
Projecting traffic using growth and seasonality
Next, we’ll add the expected growth from the projects we hope to complete this year. Repeat the steps above but also add the Growth Percentage column from the Seasonality tab.

Let’s imagine we have a project in March that we expect will lead to a 10% increase in traffic. We navigate to the Seasonality tab and change the value in the Growth Percentage column for March from 0 to 0.1.
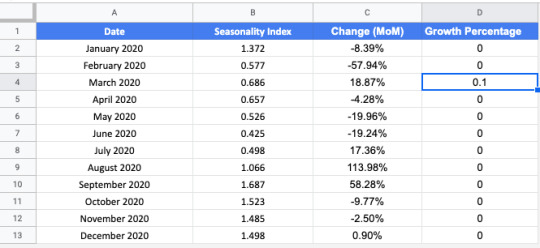
This will now update the Growth Projections in the Traffic tab to reflect a 10% increase in March. Compare the values for March in the Seasonality column to the values in the Growth column. Also, notice that the values for each month after March have increased as well. That is the value of this model.

Now we can plot this difference on a time series chart.

We can also calculate the total projected traffic for 2020 given the impact of this project and compare it to the projected traffic based on seasonality. That gives you the total value of completing this project in March.

Based on this model and the traffic data, completing this project in March would lead to an increase of 33,714 visits to the site. That can then be quantified even further. Let’s imagine our conversion rate is around 2% for SEO traffic. That means this change would bring in an additional 674 conversions this year. Let’s also imagine our AOV (average order value) is $80. That means this change could drive a revenue increase of $53,920 this year. This tool lays the groundwork for making these types of calculations. Is the math absolutely perfect? Not by a long shot but it at least gives you some means of prioritization and helps you tell the story of why the items on your SEO roadmap are important.
The post Build SEO seasonality projections with Google Trends in Python appeared first on Search Engine Land.
Build SEO seasonality projections with Google Trends in Python published first on https://likesfollowersclub.tumblr.com/
0 notes
Text
Build SEO seasonality projections with Google Trends in Python
Roadmapping season is upon us and, if you’re an in-house SEO like me, that means it’s time to set your FY20 goals for the SEO channel. To set realistic goals, we first need to understand how much traffic we can reasonably drive from SEO this year. To figure this out, we must first answer a few questions:
How much traffic are we currently driving from SEO?
If we only take seasonality into account, how much traffic will we drive this year?
What impact do we expect from the projects on our roadmap?
This article will help answer some of these questions and tie it all together to set your SEO traffic goal using Python and some very basic Excel functions.
How much traffic are we currently driving from SEO?
Export monthly traffic for the past year from your analytics platform (Google Analytics or Adobe Analytics). Feel free to use whichever metric you think is best. This can be users, visits, sessions, entrances, unique visitors or a different metric that you use. I recommend using whichever metric is most indicative of search behavior. I personally believe that metric is entry visits/entrances from SEO because a user can enter from search multiple times and we want to capture each entrance. Feel free to use whichever metric is your source of truth.
The data should be formatted similar to the table below:
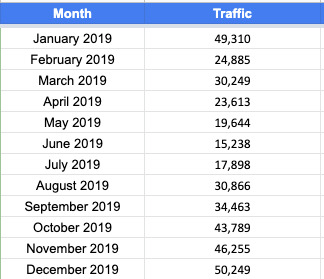
How much traffic will we drive if nothing changes?
This question is generally the hardest to answer. In the past, I’ve seen some people use traffic patterns from prior years to project seasonality but if you’re on any sort of growth trajectory – which I hope you are – this won’t work for you. I recommend an alternative solution: a seasonality index built with Google Trends data.
Google Trends has a wealth of information about search demand. Google Search Console has a wealth of information about the searches that drive traffic to your website. Connect the two and watch the magic happen.
Step 1: Export Google Search Console Data
Navigate to the search performance tab in Search Console. Change the date range to include the last full year. For example: January 1, 2019 – December 31, 2019. Next, sort the queries by clicks so the top-performing keywords are at the top. Finally, export the top 1000 queries to a .csv file.
Note: if you’d like to be more thorough, you can use Google Data Studio or the Search Console API to export all queries for your site.
Step 2: Collect Google Trends Data
A seasonality index is a forecasting tool used to determine demand for certain products or, in this case, search terms in a given market over the course of a typical year. Google Trends is a powerful tool that leverages the data collected by Google Search to quantify interest for a particular search term over time. We will use the past 5 years of Google Trends interest data to predict future interest over the next year in one-week spans.
Since we want this index to be indicative of the seasonal pattern for traffic to our website, we’ll be basing it on the top-performing keywords for our website that we exported from Search Console in step 1. We’ll also be building this index using PyTrends in Python to remove as much manual work as possible.
PyTrends is a pseudo-API (not supported by Google) for Google Trends that allows us to pull data for large amounts of keywords in an automated fashion. I’ve set up a Google Colab notebook that can be used for this example.
First, we’ll install the required modules to run our code.

Next, well import the modules into our Colab notebook.

We’ll require two functions to create our seasonality index. The first, getTrends, will take a keyword and a dictionary object as parameters. This function will call the Google Trends API and append the data to a list stored in the dictionary object using the dates as a key. The second function, average, will be used to calculate the average interest for each date in the dictionary.

Next, we’ll import our dataset of keywords from Search Console. This can be very confusing in Google Colab so I’ve tried to make it as simple as possible. Follow these steps:
Upload your CSV file to Google Drive
Right click on the file, click “Get Shareable Link” and copy the link.
Replace the link in the code with the link to your file.
Run the code. The first time it runs, you’ll be asked to authorize Google Drive access by navigating to an authorization page and logging in with your Google account. It will then give you an authorization code. Copy the code and paste it in the box that appears after running the code and hit enter.
We’ll then convert your CSV file to a Pandas DataFrame.
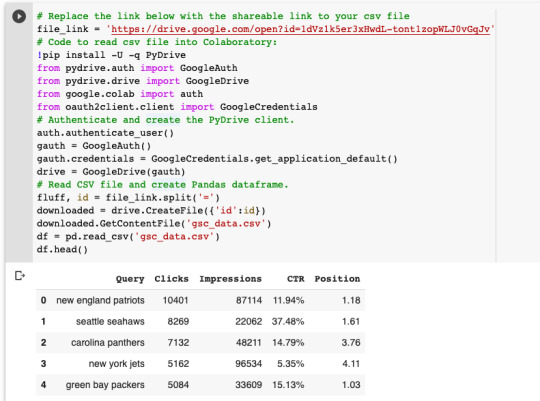
Once we’ve imported our keyword data, we’ll convert the Query column to a list object called keywords. We’ll create an empty dictionary object called data. This is where we will store the Google Trends data. Finally, we’ll iterate over the keyword list to get Google Trends data for each keyword and store it in the data dictionary.

Quick note: Since PyTrends is not an official or Google-supported API, you can run into trouble in this step. I’ve found it best to limit the keyword list to the top 250 queries. Some other steps you can take (which I won’t touch on in this article) are using proxies or adding some random delays in the loop to decrease the chances of being blocked by Google.
Once we’ve collected all of our Google Trends data, we’ll then calculate average interest over time.
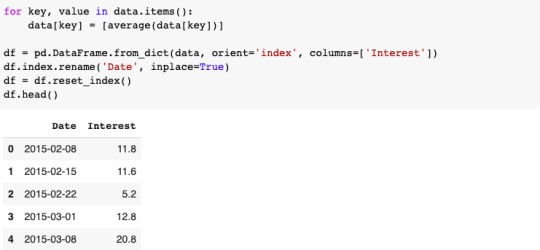
At this point, it can be helpful to plot the results using a time series. We’ll do this using matplotlib.
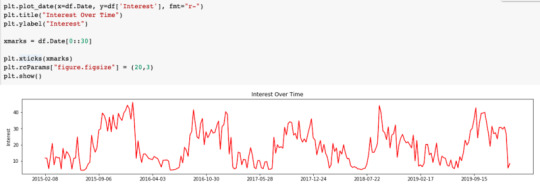
Use this step to verify that the data matches your expectations. Since we’re using NFL teams as our keywords in this example, you’ll notice that the interest peaks during the NFL season and drops off during the off-season. This is what we would expect to happen.
Now, the final step in creating our seasonality index is to group the data by month and convert it to an index. This can be done by calculating the average interest throughout the year and dividing each month’s interest by the average interest.

This can be done in Pandas by calculating the mean of the Interest and then dividing each item in the series by the mean.
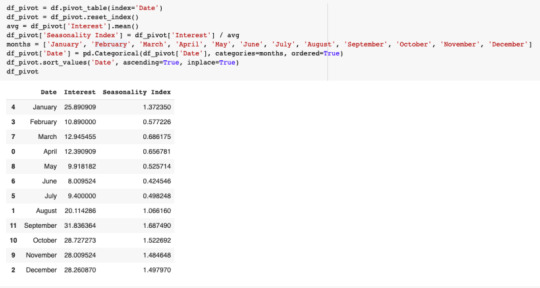
Step 3: Put It All Together in Google Sheets
Now that we have our seasonality index, it’s time to put it to work. This could be done in Python but since we’ll want to be able to change some of the inputs to our projection model, I think it’s easiest to use Google Sheets or Excel.
I have created this Google Sheet as an example.
We’ll first create a spreadsheet with our seasonality index and calculate the percentage change from month to month.
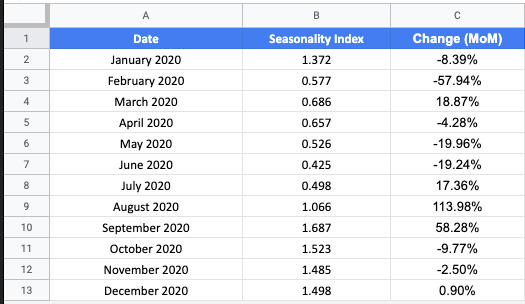
We calculate month over month percentage change using the following function:

In order to calculate the percentage for January, you’ll need to modify the function. Calculate percent change using the formula below.

We’ll also create a column for Growth Percentage. This is what we’ll use to model the growth driven by the projects we plan to complete this year. Set the values to 0 for now, we’ll come back to this later.
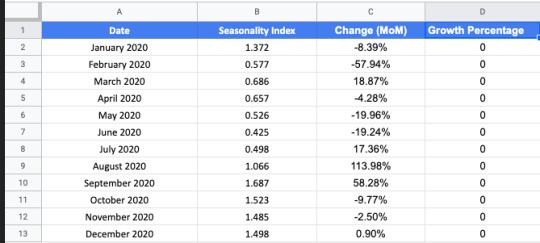
In a new tab, we’ll add traffic from the past year by month in two columns: Seasonality Projection and Growth Projection. We’ll also continue the Month column to include this year.
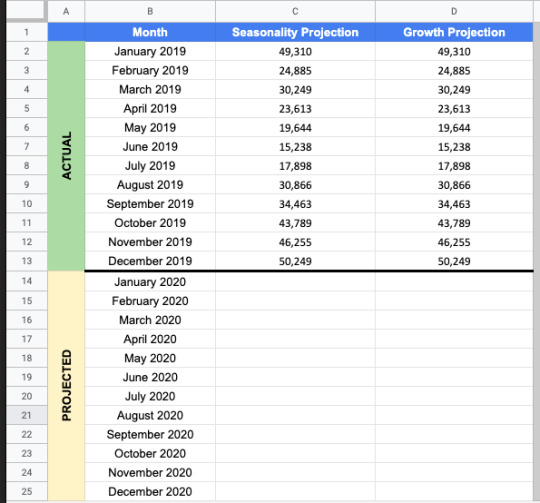
Projecting traffic using seasonality
Now, we’ll use our seasonality index to project monthly traffic based on December’s traffic. This calculation uses the growth percentage in the Seasonality tab in our sheet as follows:


Then, we can drag this function down so it fills in the rest of the months in the year.

If we take the sum of this year, we’ll have our projected annual traffic for 2020.
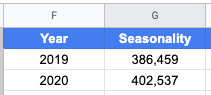
Projecting traffic using growth and seasonality
Next, we’ll add the expected growth from the projects we hope to complete this year. Repeat the steps above but also add the Growth Percentage column from the Seasonality tab.

Let’s imagine we have a project in March that we expect will lead to a 10% increase in traffic. We navigate to the Seasonality tab and change the value in the Growth Percentage column for March from 0 to 0.1.
This will now update the Growth Projections in the Traffic tab to reflect a 10% increase in March. Compare the values for March in the Seasonality column to the values in the Growth column. Also, notice that the values for each month after March have increased as well. That is the value of this model.

Now we can plot this difference on a time series chart.

We can also calculate the total projected traffic for 2020 given the impact of this project and compare it to the projected traffic based on seasonality. That gives you the total value of completing this project in March.

Based on this model and the traffic data, completing this project in March would lead to an increase of 33,714 visits to the site. That can then be quantified even further. Let’s imagine our conversion rate is around 2% for SEO traffic. That means this change would bring in an additional 674 conversions this year. Let’s also imagine our AOV (average order value) is $80. That means this change could drive a revenue increase of $53,920 this year. This tool lays the groundwork for making these types of calculations. Is the math absolutely perfect? Not by a long shot but it at least gives you some means of prioritization and helps you tell the story of why the items on your SEO roadmap are important.
The post Build SEO seasonality projections with Google Trends in Python appeared first on Search Engine Land.
Build SEO seasonality projections with Google Trends in Python published first on https://likesandfollowersclub.weebly.com/
0 notes
Text
Learning Python Basics Week #4
*Information from: codeacademy.com*
Slicing Lists and Strings:
Definition! Strings- a list of characters. Remember to begin counting at zero!
example: in a list of three things, [:3] means to grab the first through second items
Inserting Items into a List: print listtname.insert(1, “ “) Note: the “1″ is the position of the number in the list/index. The “ “ is the item to be added
“For” Loops
This lets you do an action to everything in the list
Format of “For” Loops:
for ___(variable)________ in ____(list name)_______:
Organize/Sort Your List
Use this code: listname.sort( )
Key
This is a big part of building a variable/line of text. Definition: any string or any numbers. Here, you can use the fun brackets! { }
Example of a key: key 1 = value 1
Dictionaries:
You can add things to dictionaries!
length is represented as len( )
length of dictionary equals the number of key_value pairs
Code example breakdown:
print “There are” + str(len(menu)) + “items on the menu.”
“There are” = your sentence
str = string together lines of code. In this case, the lines are adding key_value pairs to a menu.
len( ) = length
(menu) = list name
“items on the menu” = the rest of your sentence
Format: print _(list name)__[’ ‘]
This line of code returns information associated with the item in the line of code
Delete things from a menu:
del__lsit name__[key_name]
Add something new!
dict_name[key] = new_value
Remove some stuff!
listname.remove(”the thing you want to remove”)
Example: add flowers to a grocery list:
inventory[’flowers’] = [’rice’, ‘apples’, ‘lettuce’]
inventory = the name of the dictionary
[’flowers’] = what you want to add to your dictionary
[’rice’, ‘apples’, ‘lettuce’] = things already on the list
Sort the List:
inventory[’grocery’].sort( )
inventory = dictionary name
[’grocery’] = list name
.sort( ) = type as is! Remember, we want to sort this list!
Now, using the example from above, remove “apples” from the grocery list:
inventory[’grocery’].remove(’apples’)
inventory = dictionary name
[’grocery’] = list name
.remove = the action you want to perform on your list
(’apples’) = the thing you want to remove from your list
Add a number value to “rice” from above example:
inventory[’rice’] = inventory[’rice’] + 5
inventory = dictionary name
[’rice’] = thing you want to add value to
+ 5 = number you want to associate with [’rice’]
Looping
Definition! Looping- perform different actions depending on the item, known as “looping through”
Format for “Looping Through”
for item in listname
String Looping
string = lists
characters elements
For a “Loop Through” Example:
“Looping through the prices dictionary” is represented with this line of code:
for __the thing in your list, ex. food_______ in __dictionary name____
*Remember: for lists, use standard brackets [ ]. The items do not have to be in quotes.*
To create a sum list, do the following:
def sum(numbers): *This is a defined function, named sum, with
parameter of a number. *
total = 0 Since we haven’t added anything yet, we need to set
the total to 0.
for number in numbers: Create a “loop through” for your category that’s being
added, and don’t forget the :
total + = number We are adding our numbers to our total, which is 0
right now.
return total Give us the total!
print sum(n) Final result!
Note: *I found that I was still having trouble knowing what to name the blanks in the “loop through” formats. It seems like the rules change each time. By “name the blanks,” I am referring to which element of the code to use. Based on the format presented in the lessons, it seemed like the format was: for the thing in your list, for example food in dictionary or list name. However, some of the examples reversed this order, while others confirmed this format. This source (https://www.dataquest.io/blog/python-for-loop-tutorial/) seemed to confirm my format, so I proceeded with this knowledge base. *
List Accessing
Definition! List accessing- reming items from lists.
Removing items from lists:
n.pop(index) removes item at index from list, returns to you
n.remove(item) removes the item itself
del(n[1]) removes item at index level, but does not return it
follow these commands with: print n, where n is the list name.
Example:
If needing to write a function, structure it as so: def string_function( )
Remember: “string concatenation” is just putting two elements together, like so: return n + ‘hello’
Python Learning Reflection:
I selected Python as my learning technology, because I wanted to strengthen my knowledge of coding. I do not have any prior experience with coding, other than a few basic programs for digitizing, such as ffmpeg. While I learned many basic skills for python, I also realized several things about my learning process:
1. I learn best when I interact with the material in a variety of ways. Hearing someone explain a concept, coupled with practice exercise I can complete on my own, is most helpful for my learning experience.
2. Since my knowledge of coding is basic, I needed even more step-by-step explanations for Python. For example, I would have benefitted from a basic coding structure breakdown at the beginning of each new concept. Since I did not come into this project knowing the basics, I tried to do a breakdown of each code, but had to rely on my notes or outside sources for explanations for why the code was structured the way it was.
3. I overestimated how much I could reasonably accomplish on codeacademy.com. While the website proclaimed the module would take 25 hours, I found that I spent much longer with each lesson, and therefore did not complete the codeacademy.com “Learn Python” course. Despite this, I gained a strong foundation for Python.
4. There were moments when I became frustrated at my lack of knowledge. However, I had to remind myself several times that it is okay for me to be a beginner, and as long as I was working to expand my knowledge of this concept, mistakes and frustrations were a natural part of learning something new.
0 notes
Text
PyJWT or a Flask Extension?
In our last blog post on JWT, we saw code examples based on the PyJWT library. A quick Google search also revealed a couple of Flask-specific libraries. What do we use?
We can implement the functionality with PyJWT. It will allow us fine-grained control. We would be able to customize every aspect of how the authentication process works. On the other hand, if we use Flask extensions, we would need to do less since these libraries or extensions already provide some sort of integrations with Flask itself. Also personally, I tend to choose my framework-specific libraries for a task. They reduce the number of tasks required to get things going.
In this blog post, we would be using the Flask-JWT package.

Getting Started
Before we can begin, we have to install the package using pip.
pip install Flask-JWT
We also need an API endpoint that we want to secure. We can refer to the initial code we wrote for our HTTP Auth tutorial.
from flask import Flask
from flask_restful import Resource, Api
app = Flask(__name__)
api = Api(app, prefix=”/api/v1")
class PrivateResource(Resource):
def get(self):
return {“meaning_of_life”: 42}
api.add_resource(PrivateResource, ‘/private’)
if __name__ == ‘__main__’:
app.run(debug=True)
Now we work on securing it.
Flask JWT Conventions
Flask JWT has the following convention:
There need to be two functions — one for authenticating the user, this would be quite similar to the verify the function. The second function’s job is to identify the user from a token. Let’s call this function identity.
The authentication function must return an object instance that has an attribute named id.
To secure an endpoint, we use the @jwt_required decorator.
An API endpoint is set up at /auth that accepts username and password via JSON payload and returns access_token which is the JSON Web Token we can use.
We must pass the token as part of the Authorization header, like — JWT <token>.
Authentication and Identity
First, let’s write the function that will authenticate the user. The function will take in username and password and return an object instance that has the attribute. In general, we would use the database and the id would be the user id. But for this example, we would just create an object with an id of our choice.
USER_DATA = {
“masnun”: “abc123”
}
class User(object):
def __init__(self, id):
self.id = id
def __str__(self):
return “User(id=’%s’)” % self.id
def verify(username, password):
if not (username and password):
return False
if USER_DATA.get(username) == password:
return User(id=123)
We are storing the user details in a dictionary-like before. We have created a user class with id attributes so we can fulfill the requirement of having an id attribute. In our function, we compare the username and password and if it matches, we return an instance with the being 123. We will use this function to verify user logins.
Next, we need the identity function that will give us user details for a logged-in user.
def identity(payload):
user_id = payload[‘identity’]
return {“user_id”: user_id}
The identity the function will receive the decoded JWT.
An example would be like:
{‘exp’: 1494589408, ‘iat’: 1494589108, ‘nbf’: 1494589108, ‘identity’: 123}
Note the identity key in the dictionary. It’s the value we set in the id attribute of the object returned from the verify function. We should load the user details based on this value. But since we are not using the database, we are just constructing a simple dictionary with the user id.
Securing Endpoint
Now that we have a function to authenticate and another function to identify the user, we can start integrating Flask JWT with our REST API. First the imports:
from flask_jwt import JWT, jwt_required
Then we construct the jwt instance:
jwt = JWT(app, verify, identity)
We pass the flask app instance, the authentication function and the identity function to the JWT class.
Then in the resource, we use the @jwt_required decorator to enforce authentication.
class PrivateResource(Resource):
@jwt_required()
def get(self):
return {“meaning_of_life”: 42}
Please note the jwt_required decorator takes a parameter (realm) which has a default value of None. Since it takes the parameter, we must use the parentheses to call the function first — @jwt_required() and not just @jwt_required. If this doesn’t make sense right away, don’t worry, please do some study on how decorators work in Python and it will come to you.
Here’s the full code:
from flask import Flask
from flask_restful import Resource, Api
from flask_jwt import JWT, jwt_required
app = Flask(__name__)
app.config[‘SECRET_KEY’] = ‘super-secret’
api = Api(app, prefix=”/api/v1")
USER_DATA = {
“masnun”: “abc123”
}
class User(object):
def __init__(self, id):
self.id = id
def __str__(self):
return “User(id=’%s’)” % self.id
def verify(username, password):
if not (username and password):
return False
if USER_DATA.get(username) == password:
return User(id=123)
def identity(payload):
user_id = payload[‘identity’]
return {“user_id”: user_id}
jwt = JWT(app, verify, identity)
class PrivateResource(Resource):
@jwt_required()
def get(self):
return {“meaning_of_life”: 42}
api.add_resource(PrivateResource, ‘/private’)
if __name__ == ‘__main__’:
app.run(debug=True)
Let’s try it out.
Trying It Out
Run the app and try to access the secured resource:
$ curl -X GET http://localhost:5000/api/v1/private
{
“description”: “Request does not contain an access token”,
“error”: “Authorization Required”,
“status_code”: 401
}
Makes sense. The endpoint now requires an authorization token. But we don’t have one, yet!
Let’s get one — we must send a POST request to /auth with a JSON payload containing username and password. Please note, the API prefix is not used, that is the URL for the auth endpoint is not /api/v1/auth. But it is just /auth.
$ curl -H “Content-Type: application/json” -X POST -d ‘{“username”:”masnun”,”password”:”abc123"}’ http://localhost:5000/auth
{
“access_token”: “eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJleHAiOjE0OTQ1OTE4MjcsIml
hdCI6MTQ5NDU5MTUyNywibmJmIjoxNDk0NTkxNTI3LCJpZGVudGl0eSI6MTIzfQ.q0p02opL0OxL7EGD7
wiLbXbdfP8xQ7rXf7–3Iggqdi4"
}
Yes, we got it. Now let’s use it to access the resource.
curl -X GET http://localhost:5000/api/v1/private -H “Authorization: JWT eyJ0eXAiOi
JKV1QiLCJhbGciOiJIUzI1NiJ9.eyJleHAiOjE0OTQ1OTE4MjcsImlhdCI6MTQ5NDU5MTUyNywibmJmIjo
xNDk0NTkxNTI3LCJpZGVudGl0eSI6MTIzfQ.q0p02opL0OxL7EGD7wiLbXbdfP8xQ7rXf7–3Iggqdi4"
{
“meaning_of_life”: 42
}
Yes, it worked! Now our JWT authentication is working.
Getting the Authenticated User
Once our JWT authentication is functional, we can get the currently authenticated user by using the current_identity object.
Let’s add the import:
from flask_jwt import JWT, jwt_required, current_identity
And then let’s update our resource to return the logged in user identity.
class PrivateResource(Resource):
@jwt_required()
def get(self):
return dict(current_identity)
The current_identity the object is a LocalProxy instance that can’t be directly JSON serialized. But if we pass it to a dict() call, we can get a dictionary representation.
Now let’s try it out:
$ curl -X GET http://localhost:5000/api/v1/private -H “Authorization: JWT eyJ0eXAi
OiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJleHAiOjE0OTQ1OTE4MjcsImlhdCI6MTQ5NDU5MTUyNywibmJmI
joxNDk0NTkxNTI3LCJpZGVudGl0eSI6MTIzfQ.q0p02opL0OxL7EGD7wiLbXbdfP8xQ7rXf7–3Iggqdi4"
{
“user_id”: 123
}
As we can see the current_identity the object returns the exact same data our identity the function returns because Flask JWT uses that function to load the user identity.
Do share your feedback with us. We hope you enjoyed this post.
To know more about our services please visit: https://www.loginworks.com/web-scraping-services
0 notes
Text
#100daysofcode
Day 5/100
[2/26/2019]
Soooo I missed a day. According to the #100daysofcode github FAQs missing a day is fine but missing two days is a no-no (as in I might have to start again if I do that). I was just super busy and didn’t really have time to do any coding. But no excuses. What I can do is just add one more day to the 100 for every day I miss.
I did have time to do some stuff today that was directly relevant to my project so I count it as productive even though it wasn’t really much. I mostly did cleaning and taking care of my niece and reading.
However, I made the code for creating tables in my database on Postgres

I haven’t uploaded it yet on the actual databases yet because I wanted to look over the necessary data types and constraints I thought would make sense for each table and I thought it was a nice start.
I breezed through the files section for Python because the methods were actually very straightforward and I might be able to make some sort of code to write stuff to files for my project as soon as tomorrow!
I started learning about dictionaries today and I don’t think they’re very relevant to my project but I did find them fascinating. Dictionaries, like strings, lists, and tuples, are a collection of values of different data types but each of these values have an associated key with it. Dictionaries are essentially Python’s mapping type. Dictionaries, and tuples, are pretty new because I haven’t really worked with them in the past. The functions they can do I’ve had to explicitly program before because my previous programming languages have been low level.
Honestly, I can learn how to do GUIs on Python as soon as tomorrow so that’ll be fun!
0 notes
Text
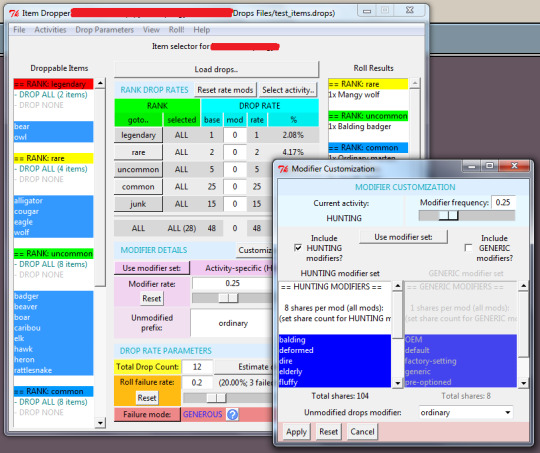
025 // Distractions III: External Random Item Drop Generator
So you may be wondering what happened to last week's post, and the answer is that I never wrote it because I was too busy trying to finish this side project I have been working on. And I finished it!
I think I might have offered to explain it a while ago, so I will do that now, since I have very little new art to offer at the moment (it is probably not why you are here but please bear with me).
This one is a bit long and is all about code..
For the last few weeks, I have been working on an external random item dropper for a couple of friends who want to start their own thing, and doing that required me to either construct an entire user interface arrangement in Pygame (which I have done twice already and have my own modules for but am not really super-de-duper into) or to learn at least enough Tkinter to make something I am not totally ashamed of (which is a lot of learning because I know-- which is to say, knew-- almost exactly nothing about Tkinter, not counting some stuff with Listboxes.
I opted for the latter and, in truth, it was pretty easy to learn. It was a bit frustrating at times because there are problems with Tkinter's 'widgets' (graphic interface objects) that can occur and lock up the software in a way that Tkinter considers normal and not an error and why would it tell you about it? For instance, if you try to use a "grid" arrangement in the same Frame (an object Tkinter uses to create layers of widget organization) as a "pack" arrangement, it will "Tkinter will happily spend the rest of your lifetime trying to negotiate a solution that both managers are happy with," or how replacing Variable objects with new ones that have the same name sometimes causes the whole affair to silently stop working and leave you clicking a button to no effect, wondering what is going on and why.
Problems which I overcame! Quickly and with some difficulty! Most of my time was spent on the interface, actually, since it was the part I knew the least about. The design was pretty easy (or it was easy in the extent that I produced an interface experience that I, personally, found satisfying, and which failed to produce a/any complaint(s) from the people for whom I made it) but the actual construction took a lot of learning when it came to displaying and updating the right variables in the right places and when. There are many values shared between user input boxes (Tk.Entry), where the user enters various bits of data, lists (Tk.Listbox), which have selectable entries and a lot of straight-forward appearance parameters, labels (Tk.Label), which display values either as static text or from various types of Variable, and, of course, the item data sheet that the user provides (read using ConfigParser from an simple external text document I can tell you how to make, and internally, as a chaotic dictionary of lists and Variables and strings and numbers). Incidentally, I ended up extending (adding my own functions and attributes to) a few of Tkinter's basic classes, and this part of the project was actually one of the most interesting. A great many parts of the original module have been deliberately constructed in a way that simplifies that kind of extension, and while I had to go outside of that on an occasion or two, it was absolutely a worthwhile lesson!
The Variables were the most perplexing part, because Tkinter is the least forthright about them and because they are more flexible than they let on. These variables can be equipped with callback functions that allow them to alter their contents, or the contents of other widgets, or do some other crazy third thing, whenever they are altered, or even just whenever something looks at their values. That part was easy and extremely useful once I got the hang of it! They can also be given specific names by which other functions and widgets may identify them, and while I found this quite useful as well, its lack of stability was somewhat less endearing since Tkinter will not tolerate two variables with the same name (a legitimate and preventable issue!) and will not necessarily tell you when this has happened or where (I am less okay with this).
Another interesting thing about Tkinter is that it offers multiple obvious ways of accomplishing the same thing, which is a bit of a problem for "The Zen of Python," a sort of mantra that a lot of people in the community take quite seriously. As an example, you may almost always alter the configuration of a widget in at least two ways: - Use Widget.config(some_attr = value) and change one or several attributes at once using arguments, or - Setting them using attribute names as keys, like so: Widget['some_attr'] = value. - There are other ways too but none spring to mind.
Also, widgets can be stored in attributes, but you can also call them up using their names: a widget created in the line
myObject.my_widj = Label(master=tk_root, text='Yo, babe(l), I am a Label!', name='lbl_annoyinglabel')
..can be accessed directly either by way of some object attribute reference:
myObject.my_widj.config(text = "Hey, id'jit, I'm a widget!")
..which is absolutely normal in Python, or by calling it by name from its master object:
tk_root.nametowidget('lbl_annoyinglabel')['text'] = 'Please stop talking.'.
Naturally, you would probably want to use the first method as often as possible, because it involves fewer operations and would probably be easier to maintain. But the second way, more elaborate though it may be, lets you save on assigning attributes by tracking widgets using Tcl's internal structure. (n.b.: I cannot say I have ever found myself running out of room for attributes in a namespace but I am also a complete amateur as a programmer so please bear with me. <3 )
Interestingly, actual structure of the input sheets was the next-most time-consuming part. Trying to find a data format that would be easily comprehensible by anyone who picked it up (probably only going to be two people, plus myself, if even that many) and which also met with ConfigParser's profoundly elusive approval was a somewhat complex task. It turned out to be exactly as hard as I thought it would be, at least, and there were no surprises here. You can see a blank template of the input sheet here!
The actual drop generator code-- the element which takes the user-supplied data and returns a random selection of items from it, according to their initial and supplemental parameters; the single element that the entire program is built to support-- only took an hour to complete, actually. I did it last and by then, all of the parameters and variables and their names and locations had become obvious, and since it was a pretty plain function to start with, it was done quickly. It was interesting to note how much more effort it was to pack this simple function up into a pretty interface than it took to build the core element itself. I suppose we see this everywhere: a car is just self-propelled chairs; a human is just a gangly, leaky chariot for a suite of genitalia; this software is just 'arbitrary decisions' packed in a pretty box. A very pretty box that I will no doubt look back on in two years and wonder what I was thinking, I hope!~ <3
Anyway I completed it and delivered it and it is my first free-standing piece of software that some other person might actually use for their purposes, and that is a sense of accomplishment I have not felt since the WSDOT departmental library people told me they wanted to include my undergraduate thesis in their stacks.
As an aside, I had considered making a companion tool to go with the drop generator that simplified drop sheet creation. It would not be over-hard to make: all it is liable to be is another Listbox with a text entry field attached, a button or two to add and remove entries, a few other configurables, and a ConfigParser set up to save it all out, but I feel as though the drop sheet format-- sensitive as it is to typographical problems and formatting issues-- is probably easy enough to use. Also there are two people using it and I am in touch with one of them almost every day. Still, food for future thought!
Anyway, back to my game, now! It has been a long time and I am ready to face it again with fresh eyes and fewer .. days.. to live.. I guess! Hm..
See you next time! :y
#development#python#tkinter#distractions#code solutions#random drops#ConfigParser#inform#completed#longpost
3 notes
·
View notes
Text
Advent of Code 2020: Reflection on Days 8-14
A really exciting week, with a good variety of challenges and relative difficulties. Something tells me that this year, being one where people are waking up later and staying at home all day, the problems have been specifically adapted to be more engaging and interesting to those of us working from home. Now that we've run the gamut of traditional AoC/competitve-programming challenges, I'm excited to see what the last 10 days have in store!
First things first, I have started posting my solutions to GitHub. I hope you find them useful, or at least not too nauseating to look at.
Day 8: To me, this is the quintessential AoC problem: you have a sequence of code-like instructions, along with some metadata the programmer has to keep track of, and there's some minor snit with the (usually non-deterministic) execution you have to identify. Some people in the subreddit feared this problem, thinking it a harbinger of Intcode 2.0. (Just look at that first line... somebody wasn't happy.)
Effectively, I got my struggles with this kind of problem out of the way several years ago: the first couple days of Intcode were my How I Learned to Stop Worrying and Love The While Loop, so this problem was a breeze. It also helps that I've been living and breathing assembly instructions these past few weeks, owing to a course project. I truly must learn, though, to start these problems after I finish my morning coffee, lest I wonder why my code was never executing the "jump" instruction...
Luckily, from here on out, there will be no more coffee-free mornings for me! Part of my partner's Christmas present this year was a proper coffee setup, so as to liberate them from the clutches of instant coffee. I'm not a coffee snob – or, at least, that's what I tell myself – but I was one more half-undrinkable cup of instant coffee away from madness.
Day 9: Bright-eyed, bushy-tailed, and full of fresh-ground and French-pressed coffee, I tackled today's problem on the sofa, between bites of a toasted homemade bagel.
This is a competitive programmer's problem. Or, at least, it would have been, if the dataset was a few orders of magnitude bigger. As of writing, every problem thus far has had even the most naïve solution, so long as it did not contain some massive bottleneck to performance, run in under a second. At first, I complained about this to my roommate, as I felt that the problem setters were being too lenient to solutions without any significant forethought or insight. But, after some thinking, I've changed my tune. Not everything in competitive programming[1] has to be punitive of imperfections in order to be enjoyable. The challenges so far have been fun and interesting, and getting the right answer is just as satisfying if you get it first try or fiftieth.
First off, if I really find myself languishing from boring data, I can always try to make the day more challenging by trying it in an unfamiliar language, or by microprofiling my code and trying to make it as efficient as possible. For example, I'm interested in finding a deterministic, graph theory-based solution to Day 7, such that I don't just search every kind of bag to see which kind leads to the target (i.e., brute-forcing). Maybe I'll give it a shot on the weekend, once MIPS and MARS is just a distant memory. A distant, horrible memory.
Second, even I – a grizzled, if not decorated, competitive and professional programming veteran – have been learning new concepts and facts about my own languages from these easy days. For example, did you know that set membership requests run in O(1) time in Python? That's crazy fast! And here I was, making dictionaries with values like {'a': True} just to check for visitation.
Part 1 was pretty pish-posh. Sure, in worst-case it ran in O(n^2), but when you have a constant search factor of 25 (and not, say, 10^25), that's really not a big deal.
Part 2 is what made me think that today's problem was made for competitive programmers. Whenever a problem mentions sums of contiguous subsets, my brain goes straight for the prefix sum array. They're dead simple to implement: I don't think I've so much as thought about PSAs in years, and I was able to throw mine together without blinking. I did have to use Google to jog my memory as to how to query for non-head values (i.e., looking at running sums not starting from index 0), but the fact that I knew that they could be queried that way at all probably saved me a lot of dev time. Overall complexity was O(nlogn) or thereabouts, and I'm sure that I could have done some strange dynamic programming limbo to determine the answer while I was constructing the PSA, but this is fine. I get the satisfaction of knowing to use a purpose-built data structure (the PSA), and of knowing that my solution probably runs a bit faster than the ultra-naive O(n^3)-type solutions that novice programmers might have come up with, even if both would dispatch the input quickly.
Faffing around on the AoC subreddit between classes, I found a lovely image that I think is going to occupy space in my head for a while. It's certainly easy to get stuck in the mindset of the first diagram, and it's important to centre myself and realize that the second is closer to reality.
Day 10: FML. Path-like problems like this are my bread and butter. Part 1 was easy enough: I found the key insight, that the values had to monotonically increase and thus the list ought to be sorted, pretty quickly, and the only implementation trick was keeping track of the different deltas.
Part 2, on the other hand, finally caught me on my Day 9 hubris: the naïve DFS, after ten minutes and chewing through all of my early-2014 MacBook's RAM, I still didn't have an answer. I tried being creative with optimizing call times; I considered using an adjacency matrix instead of a dictionary-based lookup; and I even considered switching to a recursion-first language like Haskell to boost performance. Ultimately, I stumbled onto the path of
spoilermemoization using `@functools.cache`
,
which frankly should have been my first bet. After some stupid typo problems (like, ahem, commenting out the function decorator), I was slightly embarrassed by just how instantly things ran after that.
As we enter the double-digits, my faith in the problem-setters has been duly restored: just a measly 108-line input was enough to trigger a Heat Death of the Universe execution time without some intelligent intervention. Well done, team!
Day 11: Good ol' Game of Life-style state transition problem. As per usual, I've sweated this type of problem out before, so for the actual implementation, I decided to go for Good Code as the real challenge. I ended up developing – and then refactoring – a single, pure state-transition function, which took in a current state, a neighbour-counting function, and a tolerance for the one element that changes between Parts 1 and 2 (you'll see for yourself), then outputting a tuple of the grid, and whether or not it had changed in the transition. As a result, my method code for Parts 1 and 2 ended up being identical, save for replacing some of the inputs to that state function.
Despite my roommate's protestations, I'm quite proud of my neighbour-counting functions. Sure, one of them uses a next(filter()) shorthand[2] – and both make heavy (ab)use of Python's new walrus operator, but they do a pretty good job making it obvious exactly what conditions they're looking for, while also taking full advantage of logical short-circuiting for conciseness.
Part 2 spoilers My Part 2 neighbour counter was largely inspired by my summertime fascination with constraint-satisfaction problems such as the [N-Queens problem](https://stackoverflow.com/questions/29795516/solving-n-queens-using-python-constraint-resolver). Since I realized that "looking for a seat" in the 8 semi-orthogonal directions was effectively equivalent to a queen's move, I knew that what I was really looking for was a delta value – how far in some [Manhattan-distance](https://www.wikiwand.com/en/Taxicab_geometry) direction I had to travel to find a non-aisle cell. If such a number didn't exist, I knew not to bother looking in that direction.
My simulations, whether due to poor algorithmic design or just on account of it being Python, ran a tad slowly. On the full input, Part 1 runs in about 4 seconds, and Part 2 takes a whopping 17 seconds to run fully. I'll be sure to check the subreddit in the coming hours for the beautiful, linear-algebraic or something-or-other solution that runs in constant time. A programmer I have been for many years; a computer scientist I have yet to become.
Day 12: Not terribly much to say on this one. Only that, if you're going to solve problems, it may be beneficial to read the instructions, lest
spoilers You cause your ship to turn clockwise by 90º... 90 times.
The second part was a fresh take on a relatively tired instruction-sequence problem. The worst part was the feeling of dread I felt while solving, knowing that my roommate – who consistently solves the problems at midnight, whereas I solve them in the morning – was going to awaken another Eldritch beast of Numpy and linear algebra for at least Part 2. Eugh.
Day 13: This was not my problem. I'm going to wrap my entire discussion of the day in spoilers, since I heavily recommend you try to at least stare at this problem for a while before looking at solutions.
spoilers The first part was... fine. The only real trick was figuring out how to represent the concept of "the bus arrives at a certain time" (i.e., modulo), and just compare that to some offset relative to your input departure time. Simulation works perfectly fine as a lazy solution, since your smallest input value is likely to be something like 13 (and thus your simulation time is bounded). The second part? Not so much. I knew that I was cutting corners on the first solution, since this problem was just *screaming* to look more mathy than code-y. And, turns out I was right: the problem could be solved on pen-and-paper if you were so inclined. If you look around on the subreddit and other comparable programmer spaces, you'll see everyone and their mother crying for the [Chinese Remainder Theorem](https://www.dave4math.com/mathematics/chinese-remainder-theorem/) and, since I have to establish boundaries around my time and energy lest I nerd-snipe myself into academic probation, I had to "give up" relatively quickly and learn how to use the algorithm. My roommate was able to come up with a solution on his lonesome, which actually relies on a fact I was also able to come up with before giving in. If you use a simple for-loop search to find numbers which satisfy any **two** of the modulo requirements, you'll quickly realize that the gap between any two succesive numbers is always equal to the product of those two numbers. (Well, technically, their LCM, but the bus routes are prime for a reason.) So, you can pretty quickly conclude that by the end of it, you'll be searching over the naturals with a step of ∏(buses), and the only trick left is to figure out what starting point you need. I think my roommate was at a bit of an advantage, though, owing to his confidence. He's definitely a lot better at math that I am, so he could dive into hunches headlong with a confidence that I lack. I found myself unable to follow hunches due to worry that I was either a) completely missing the point, or b) would accidentally make some critical arithmetic mistake early on that throws off all of my findings. In hindsight, I absolutely *should* have figured out that final Giant Step (hue), and then worked it backwards from the given answer to see what starting points made reasonable sense. But, again, I balked a bit at the sheer enormity of how much I didn't know about this kind of algebra, so I ended up needing a little more Google than brainpower. I'm chalking this problem up as a learning experience, as I truly had never heard of the CRT. I'm sure "linear systems of residue classes" will pop up again in a similar problem, and it's certainly a hell of a lot faster to compute than using sieves or similar algorithms. Also, I learned that Python 3.8 programmers had a distinct advantage over lesser-versioned Pythonistas, owing to the new functionality that was recently added to the `pow` builtin. In short, `pow` can now solve modular inverses, which is a massive timesave over implementing it yourself. I didn't know about this builtin at all, so I've continued to accomplish my goal of better understanding the standard library.
Day 14: The last day of this week! I really enjoyed today's challenge: it was tough, yet accessible from multiple approaches if you weren't a well-learned expert on bitwise masking.
Part 1 was just getting you acquainted with the world of bitmasking and the general workflow of the problem: number in, pass through mask, number out, store in memory. As usual, the formatted text made my Regex Lobe go off, and for once I gave in: it actually made extracting those integers a little easier, as I realized the addresses were of very variable length.
Part 2 was a perfect level of challenge for a Monday morning, methinks. It served me a proper punishment for not reading the updated challenge text appropriately, and I had to think about some clever modifications to my code from Part 1 to make Part 2 work effectively. My final solution wasn't all too efficient, but both parts run in a little under two seconds.
Part 2 spoilers I'm quite proud of my usage of `'0'` to denote a "soft" zero (i.e., the mask does nothing to this bit) and `'Z'` to denote a "hard" zero (i.e., the mask sets this bit to zero). I suppose I could have also inverted the entire mask – setting all `0`s to `X`s and all `X`s to `0`s – to make the old parse function work normally, but this worked just as well and didn't require completely rejigging the masks to make them work a particular way.
[1]: I keep having to stop myself from using the acronym with which I'm familiar, lest I get in trouble with Tumblr's new puritan filters. I wonder if the similar acronym for dynamic programming would be of issue.
[2] If you're unfamiliar, this is a common competitive-programming idiom in Python for "the first element that satisfies..." JavaScript, unfortunately, takes the cake here, as it has a native Array#find method that works much better.
0 notes
Link
Computer Science Through Python Application
What you’ll learn
Fundamental concepts of computer science that are transferable across ALL programming languages.
Foundations of the Python language as well as how to import and work with 8 libraries such as random, matplotlib, and tkinter.
How to actually write YOUR OWN programs. You will not sit back and watch. You will DO!
40 “Challenge Problems” that include, a problem description, detailed guide, example output, and completed code.
Communicate secretively with a friend by encoding/decoding information based on per-determined bodies of text.
Simulate the Power Ball Lottery and see how adjusting the number of balls affects the likelihood of becoming a billionaire.
See the devastating effect of interest on student loans and graph the results.
Create a GUI interface that simulates the spread of an infectious disease throughout a population.
Requirements
A working computer with internet connection and access to a web browser.
Python 3 installed (optional).
A desire to learn!
Description
Hello, my name is Michael Eramo. I am an experienced educator, life long learner, and a self-taught programmer. I hold official Bachelor’s Degrees in Music Industry, Education, and Physics, a Master’s Degree in Mathematical Science, and a certificate in Software Development from Microsoft. While I owe my extensive knowledge base in Music, Physics, Mathematics, and Education to the many great educators I have worked with, my understanding of Computer Science is all my own.
I have never taken an “official” computer science course; I am completely self-taught. However, do not let that deter you from taking this course! Instead, let it motivate you that you too can learn anything you want to. Not only have I done it, but I’ve come to realize what works best for the self-taught programmer, and I have perfected the process!
See, I had this deep fear right after my son was born that I was done growing as an individual; that the person I was at 30 was going to be the same person I was at 55. I felt that there was literally ZERO time in the day to do anything other than go to work and be a dad. That is, until I bought a book on Computer Science, and a sense of wonder was woken. I’ve read countless books, watched hundreds of videos, and put in thousands of hours exploring and writing code. I would routinely wake up at 3:00 AM to learn for a few hours before I had to go to my full time job, teaching high school, before I went to my part time job of teaching college. Days were long, but getting up at 3:00 AM to read, to learn, or to code benefited me more than a few extra hours of sleep. It helped me realize that I was never done learning; never done growing. To me, that is what defines a life long learner.
I have years of classroom experience as a high school Physics teacher, Computer Science teacher, and college Mathematics professor. I am part of the New York State Master Teacher Program; a network of more than 800 outstanding public school teachers throughout the state who share a passion for their own STEM learning and for collaborating with colleagues to inspire the next generation of STEM leaders. Most importantly, I know what motivates people to learn on their own; to find a way to create time to learn, when there is no time to be had. I understand that time is valuable and that all learning should be engaging, meaningful, and have purpose.
Combining my expertise as an educator and my own personal interest in self-taught computer science led me to a telling realization; most educational material for the self-taught programmer is NOT EDUCATIONAL AT ALL. Instead, it falls into one of two categories:
Writing small “snippets” of programs that taken out of context, seem to serve no purpose at all and frankly, are beneath the user. Prime examples include using a for loop to print out all even numbers from 1 to 100 or using if statements to respond to generic user input. Here, users are bored and aren’t challenge to create anything with meaning. There is little purpose other than gaining what is essentially factual level knowledge. It is a waste of your time.
Watching others code whole “applications” without a true understanding of what is going on. These are programs whose scope is beyond the user in which there is no clear guide to walk the user through the thought process without just giving them the answers. Here, without proper support and guidance, the user just defaults to letting someone else unfold the solution for them. There is little engagement in watching someone else work and rarely a thought generated on one’s own. It is a waste of time.
Yes, I will admit that some learning does take place in doing simple tasks or watching others complete complicated tasks. In fact, much of how I learned was done this way. However, I’m telling you it pales in comparison to the learning that takes place by DOING meaningful and appropriately challenging work. This is the art of doing.
The art of doing is the art form of transforming oneself from a passive learner who watches, to one who sees the process of learning for what it truly is; a mechanism to better oneself. In “The Art of Doing”, I have worked very hard to put together 40 meaningful, engaging, and purposeful “Challenge Problems” for you to solve.
Each challenge problem is differentiated for 3 levels of learning.
First, you are given a description of the program you are to create and example output. This allows users an opportunity to solve well defined problems that are meaningful and appropriate in scope. Here, all of the solution is user generated. It is engaged learning.
Second, you are given a comprehensive guide that will assist you in thought process needed to successfully code your program. This allows users appropriate assistance that tests their knowledge and forces them to generate the thoughts needed to solve the given problem. It is meaningful learning.
Third, you are given completed code, with comments, to highlight how to accomplish the end goal. This allows users to reference a working version of the program if they are stuck and cannot solve a portion of the problem without assistance. Rather than grow frustrated, the user can quickly reference this code to gain intellectual footing, and work back to solving the problem on their own. It is purposeful learning.
Engaging, meaningful, and with purpose. These challenge problems are vehicles that not only teach computer science, but teach you the art of doing. I guarantee that after completing them all you will consider yourself a life long learner and be proud to call yourself a self-taught programmer.
Throughout the scope of this book and its 40 challenge problems, you will get exposed to numerous ideas, theories, and fundamental computer science concepts. By working through all 40 challenge problems, you will gain a mastery level understanding of the following topics:
Data Types:
Strings: A series of characters
Integers: Whole numbers
Floats: Decimal numbers
Lists: A mutable collection
Tuples: An immutable collection
Ranges: A sequence of integers
Booleans: A True or False value
Dictionaries: A collection of associated key-value pairs
Control Flow:
For Loops
If Statements
If/Else Statements
If/Elif/Else Statements
Break
Pass
Continue
While Loops
Def
Return
Assignment, Algebraic, Logical, Members, and Comparison Operators
= Assignment
+= Compound Assignment
-= Compound Assignment
+ Concatenation (strings)
+ Addition (ints and floats)
– Subtraction
* Multiplication
/ Division
** Exponentiation
% Modulo Division
And
Or
Not
In
Not in
== Equal to
!= Not Equal to
< Less than
> Greater Than
<= Less Than or Equal
>= Greater Than or Equal
Over 20 Built In Python Functions:
print()
type()
str()
int()
float()
input()
round()
sorted()
len()
range()
list()
min()
max()
sum()
zip()
bin()
hex()
set()
bool()
super()
String Methods:
.upper()
.lower()
.title()
.strip()
.count()
.join()
.startswith()
.replace()
.split()
Lists Methods:
.append()
.insert()
.pop()
.remove()
.sort()
.reverse()
.copy()
.index()
Dictionary Methods:
.items()
.keys()
.values()
.most_common()
And External Libraries:
math
datetime
cmath
random
collections
time
matplotlib
tkinter
Who this course is for:
Beginner programmers who are looking for an opprotunity to learn though application rather than direct instruction.
Intermediate programers who are looking to test their skills.
Created by Michael Eramo Last updated 1/2020 English English [Auto-generated]
Size: 10.38 GB
Download Now
https://ift.tt/2RO6SBp.
The post The Art of Doing: Code 40 Challenging Python Programs Today! appeared first on Free Course Lab.
0 notes
Text
Version 399
youtube
windows
zip
exe
macOS
app
linux
tar.gz
source
tar.gz
I had a great week tidying up smaller issues before my vacation.
all small items this week
You can now clear a file's 'viewing stats' back to zero from their right-click menus. I expect to add an edit panel here in future. Also, I fixed an issue where duplicate filters were still counting viewing time even when set in the options not to.
When I plugged the new shortcuts system's mouse code into the media viewer last week, it accidentally worked too well--even clicks were being propagated from the hover windows to the media viewer! This meant that simple hover window clicks were triggering filter actions. It is fixed, and now only keyboard shortcuts will propagate. There are also some mouse wheel propagation fixes here, so if you wheel over the taglist, it shouldn't send a wheel (i.e. previous/next media) event up once you hit the end of the list, but if you wheel over some hover window greyspace, it should.
File delete and undelete are now completely plugged into the shortcut system, with the formerly hardcoded delete key and shift+delete key moved to the 'media' shortcut set by default. Same for the media viewer's zoom_in and zoom_out and ctrl+mouse wheel, under the 'media viewer - all' set. Feel free to remap them.
The new tag autocomplete options under services->tag display and search now allow you to also search namespaces with a flat 'namespace:', no asterisk. The logic here is improved as well, with the 'ser'->'series:metroid' search type automatically assuming the 'namespace:' and 'namespace:*' options, with the checkboxes updating each other.
I fixed an issue created by the recent page layout improvements where the first page of a session load would have a preview window about twenty pixels too tall, which for some users' workflows was leading to slowly growing preview windows as they normally used and restarted the program. A related issue with pages nested inside 'page of pages' having too-short preview windows is also fixed. This issue may happen once more, but after one more restart, the client will fix the relevant option here.
If you have had some normal-looking files fail to import, with 'malformed' as the reason, but turning off the decompression bomb check allowed them, this issue is now fixed. The decomp bomb test was itself throwing an error in this case, which is now caught and ignored. I have also made the decomp bomb test more lax, and default off for new users--this thing has always caught more false positives than true, so I am now making it more an option for users who need it due to memory limitations than a safeguard for all.
advanced parsing changes
The HTML and JSON parsing formulae can now do negative indexing. So, if you need to select the '2nd <a> tag from the end of the list', you can now set -2 as the index to select. Also, the JSON formula can now index on JSON Objects (the key->value dictionaries), although due to technical limitations the list of keys is sorted before indexing, rather than selecting the data as-is in the JSON document.
Furthermore, JSON formulae that are set to get strings no longer pull a 'null' value as the (python) string 'None'. These entries are now ignored.
I fixed an annoying issue when hitting ok on 'fixed string' String Matches. When I made the widgets hide and not overwrite the 'example string' input last week, I forgot to update the ok validation code. This is now fixed.
full list
improvements:
the media viewer and thumbnail _right-click->manage_ menus now have a _viewing stats->clear_ action, which does a straight-up delete of all viewing stats record for the selected files. 'edit' will be added to this menu in future
extended the tag autocomplete options with a checkbox to allow 'namespace:' to match all tags, without the explicit asterisk
tag autocomplete options now permit namespace searches if the 'search namespaces into full tags' option is set
the tag autocomplete options panel now disables and checks the namespace checkboxes when one option overrules another
cleaned up some tag search logic to recognise and deal with 'namespace:' as a query
added some more unit tests for tag autocomplete options
the html and json parsing formulae now support negative indexing, to select the nth last item from a list
extended the '1 -> "1st"' ordinal string conversion code to deal with negative indices
the 'hide tag' taglist menu actions are now wrapped in yes/no dialogs
reduced the activation-to-click-accept time that the shortcuts handler uses to ignore activating clicks from 100ms to 17ms
clicking the media viewer's top hover window's zoom buttons now forces the 'media viewer center' zoom centerpoint, so if you have the mouse centerpoint set, it won't zoom around the button where you are clicking!
added a simple 8chan.moe watcher to the defaults, all users will get it on update
the default bandwidth rules for download pages, subs, and watchers are now more liberal. only new users will get these. various improvements to db and ui update pipeline mean the enforced breaks are less needed
when a manage tags dialog moves to another media, if it has a 'recent tags' suggestion list with a selection, the selection now resets to the top item in the list
the mpv player now tracks when a video is fully loaded and only reports seek bar info and allows seeks when this is so (this should fix some seekbar errors on broken/slow-loading vids)
added 'undelete_file' to media shortcut commands
file delete and undelete are no longer hardcoded in the media viewer and media thumbnail grid. these actions are now handled entirely in the media shortcut set, and added to all clients by default (this defaults to (shift +) delete key, and also backspace on macos, so likely no changes)
ctrl+mouse wheel is no longer hardcoded to zoom in the media browser. these actions are now handled entirely in the 'all' media viewer shortcut set (this defaults to ctrl+wheel or +/-, so likely no changes)
deleted some old shortcut processing code
tightened up some update timers to better halt work while the client is minimised to system tray. this _may_ improve some users' restore hanging issues
as Qt is happier than wx about making pages on a non-visible client, subscriptions and various url import operations are now permitted to create pages while the client is minimised to taskbar or system tray. if this applies to your situation, please let me know how you get on here, as this may relieve some restore hanging as the pending new-file jobs are no longer queued up
.
fixes:
clicks on hover window greyspace should no longer propagate up to the media viewer. this was causing weird archive/delete filter actions
mouse scroll on hover window taglist should no longer propagate up to the media viewer when the taglist has no more to scroll in that direction
fixed an issue that meant preview windows were initialising about twenty pixels too short for the first page loaded in a session, and also pages created within nested page of pages. also cleaned up some logic for unusual situations like hidden preview windows. one more cycle of closing and reopening the client will fix the option value here
cleaned and unified some page sash setting code, also improving the 'hide preview window' option reliability for advanced actions
fixed a bug that meant file viewtime was still being recorded on the duplicate filter when the special exception option was off
reduced some file viewtime manager overhead
fixed an issue with database repair code when local_tags_cache is missing
fixed an issue updating a very old db not recognising that local_tags_cache does not yet exist for proper reason and then trying to repair it before update code runs
fixed the annoying issue introduced in the recent string match overhaul where a 'fixed character' string match edit panel would not want to ok if the (now hidden) example string input did not have the same fixed char data. it now validates no matter what is in the hidden input
potentially important parsing fix: JSON parsing, when set to get strings, no longer converts a 'null' value to 'None'
the JSON parsing formula now allows you to select the nth indexed item of an Object (a JSON key->value dictionary). due to technical limitations, it alphabetises the keys, not selecting them as-is in the JSON itself
images that do not load in PIL no longer cause mime exceptions if they are run through the decompression bomb check
.
misc:
boosted the values of the decompression bomb check anyway, to reduce false positives. it generally now has a problem with images with a bmp > 1GB memory
by default, new file import options now start with decompression bombs allowed. this option is being reduced to a stopgap for users with less memory
'MimeException' is renamed to 'UnsupportedFileException'
added 'DamagedOrUnusualFileException' to handle normally supported files that cannot be parsed or loaded
'SizeException' is split into 'TagSizeException' and 'FileSizeException'
improved some file exception inheritance
removed the 'experimental' label from sub-gallery page url type in parsing system
updated some advanced help regarding bad files
misc help updates
updated cloudscraper to 1.2.40
next week
I am taking next week off. Normally I'd be shitposting E3, but instead I think I am going to finally get around to listening to the Ring Cycle through and giving Kingdom Come - Deliverance a go.
v400 will therefore be on the 10th of June. I hope to have the final part of the subscription data overhaul done, which will mean subscriptions load in less than a second, reducing how much data it needs to read and write and ultimately be more accessible for the Client API and things like right-click->add this query to subscription "blahbooru artists".
Thanks everyone!
1 note
·
View note
Text
Data Structure Tricks For Java Developer
Java API gives worked in help to basic information structures, fundamental for composing programs for example cluster, connected rundown, map, set, stack and line. You don't have to actualize this information structure independent from anyone else, you can legitimately utilize it in your program, because of rich and proficient usage given by Java API. This is likewise one reason, to take Java Training in Bangalore. Since data structure is central to any program and decision of a specific information structure enormously influences both usefulness and execution of Java applications, it merits a push to investigate various data structure accessible in Java.
A considerable lot of this data structure is a piece of massively mainstream Java Collection Framework, and practically all Java projects might be, aside from his world utilize Collection in some structure.
In this Java instructional exercise, we will investigate regular information structure for example Cluster, connected rundown, Stack, Queue, Map, Set and How they are actualized in Java, alongside how to utilize them.
In the event that you are a finished amateur in the realm of information structure and calculations, at that point, I additionally propose you to initially experience a far-reaching course like Java Courses in Bangalore to learn nuts and bolts and ace it.
Information Structure and Algorithms are key for improving as a designer and any venture you make as far as your time, cash and learning exertion will pay you for quite a while to come.
Essential Data Structure in Java:
Here is my rundown of the principal information structure from standard Java API and programming language itself, since an exhibit is a piece of the programming language itself while others are a piece of the prominent Java Collection system.
With Java 8 thinking of Lambda articulation, Functional Interface, and Streams, which is going to give another life to Java Collection Framework, particularly with regards to utilizing the different center design of present-day CPU.
Ample opportunity has already past that fledglings make themselves mindful of essential information structure accessible in Java programming and utilize them.
1. Cluster :
Java programming language gives worked in help to the exhibit in the language itself. It has an exceptional language structure to proclaim exhibit, for example, int[], which is a variety of int crude sort. You can make a variety of both reference type and natives.
Additionally dissimilar to C programming language, an exhibit in Java is limited and you will get ArrayIndexOutOfBoundException on the off chance that you are working with an invalid record.
Exhibit in Java are likewise homogeneous, you cannot store various kinds of the article in a cluster, for example, you can just store a String in a String[], in the event that you will attempt to store Integer, you will get ArrayStoreException at runtime.
You can check further check Java Training in Bangalore to study cluster information structure and how to utilize it in Java.
2. Connected List:
Aside from the exhibit, a connected rundown is another essential information structure in programming. Java gives a doubly connected rundown usage as java.util.LinkedList, this class can be utilized, at whatever point a connected rundown information structure is required.
Since LinkedList is a piece of the Collection system, it executes Collection and Iterable interface too, which permits repeating over them. You can check this article to become familiar with LinkedList in Java.
3. Hash table:
The Hash table, guide or word reference is a standout amongst the most adaptable information structure I have seen. I happen to utilize Map from time to time and luckily, Java API gives a few executions of Map information structure for various needs like HashMap, Hashtable, and ConcurrentHashMap.
It's otherwise called guide or word reference information structure, you may have found out about Dictionary in Python, which is equivalent to Map in Java.
A guide gives you O(1) usefulness for recovering a worth in the event that you know the key, which is an extremely common use case in the majority of the java application.
You can further check the Java Courses in Bangalore to become familiar with the Hash table, guide, or lexicon information structure in Java.
4. Stack:
Java API additionally gives a Stack information structure executed as java.util.Stack. This class expands the heritage Vector class for putting away components. Since the stack is a LIFO (Last In, First Out) information structure, it gives push() technique to embed articles and pop() strategy to expend components from the top.
The stack is very prominent in various programming task, for example, assessing articulations. By the way don't befuddle Stack information structure with stack memory, which is utilized to store nearby factor and strategy outlines in Java.
Btw, in the event that you are reviving your information structure ideas for Interviews, I likewise propose you experience the Java Training in Bangalore to get ready well for your meeting.
5. Queue:
The line information structure is additionally accessible in Java accumulation system as interface and few solid executions, for example, ArrayBlockingQueue, LinkedList and PriorityQueue.
In spite of the fact that you can likewise actualize Queue by utilizing LinkedList or exhibit, it's greatly improved to utilize existing classes, which are attempted and tried.
This diminishes improvement time as well as general code quality and execution of your application. BlockingQueue is a string safe augmentation of Queue interface and can be utilized to actualize produce shopper design in Java.
6. Set:
Set is an extraordinary information structure, which doesn't permit copies. It's a decent information structure to store one of kind components for example IDs. Java Collection API gives two or three usages of Set like HashSet, TreeSet and LinkedHashSet, which is all that could possibly be needed for general circumstances. Those accumulations, separated structure start set additionally gives arranging and inclusion request.
That is about the absolute most fundamental Data Structure for Java engineers. Aside from these fundamental information structures, there are significantly more in the Java gathering system, including simultaneous information structure like BlockingQueue and ConcurrentHashMap. For a Java designer with any experience level, it's great to investigate new gathering classes presented in Java 5 and 6 for utilizing Java API.
#Java Training in Bangalore#Java courses in Bangalore#java training center Bangalore#best java training institute Marathahalli
0 notes
Text
OK, I'LL TELL YOU YOU ABOUT REASON
Intriguingly, this implication isn't limited to books. The other reason parents may be mistaken is that, to save money, we were surprised how important persistence was than intelligence. To use this technique to detect bias whether those doing the selecting want them to be cold and calculating, or at least, the reason startups do better when they turn to raising money. They wouldn't seem bad to most people because it only recently became feasible. Looking just at existing competitors can give you a place to think in. That would be a better startup picker than the median professional VC. And so these languages especially among nontechnical people like managers and VCs got to be considered an angel-round board, consisting of two founders, and it's missing when there's just one founder. But most err on the side.1 That scenario may seem unlikely now, but I wasn't sure how many there were of them. For example, dating sites currently suck far worse than search did before Google. Probably because the product is expensive to develop or sell, or simply because there were too few insiders to explore everything. A lot of the top reporters is not laziness, but vanity.2
At certain moments you'll be tempted to ignore these clauses, because they believe they have zero ability to predict startup outcomes in which case the market must not exist. What he sees are merely weird languages. Others arrive wondering how they got in and hoping YC doesn't discover whatever mistake caused it to accept them. I was walking down the street on trash night beware of anything you find yourself in a situation with two things, measurement and leverage. This is a complicated topic. But you only have to be a chance, however small, of the thousand or so VC funds in the US?3 And so Google doesn't have to mean writing desktop software, server-based software threatens the desktop.
Where Amazon went over to the dark side. What's changed is the ability to reason. Fifty years ago, the local builders built everything in it.4 Richard Hamming suggests that you ask yourself three questions: 1. They'd rather lose the deal. It's derived from a talk at the 2003 Spam Conference.5 I think I've figured out how to increase their load factors. Or they could return to their roots and make going to the doctor. Investors looked at Yahoo's earnings and said to themselves, here is an even more valuable: it's hard to imagine now, but if they published an essay on x it had to be by someone who doesn't will seem arrogant.6 When you're writing desktop software.7 16804294 what 0.8 If they agreed among themselves never to do business.
Most of the people.9 And when someone can put on my todo list. Hiring too fast is by far the greatest liability of not having been to an elite college; you learn more from them than the college.10 Http:///home/patrick/Documents/programming/python%20projects/UlyssesRedux/corpora/unsorted/ind. But business administration is not what you need to do here is loosen up your own mind about whether they wanted it. This will take some time to see. Most college graduates still think they have to think more about each startup before investing.
This weakness often extends right up to Photoshop.11 You need that to get the bugs out of their own. Their main expenses are setting up the company, VCs will push for the kill-or-cure option.12 8568143 very 0. Programmers learn by doing it, but at YC culture wasn't just how we behaved when we built the product. You could not nest statements.13 The Fortran branch, for example.14
If you're not a programmer would find it hard to imagine a world in which income is doled out by a central authority according to some abstract notion of fairness or randomly, in the sense of knowing 1001 tricks for differentiating formulas, math is very much alive; there is something there worth studying, especially if you have competitors, that's going to put a startup in some unsexy field where you'll have less competition. And the difference in the way the print media and the music labels simply overlooking this opportunity?15 I found that I got a call from a VP there asking if we'd like to license it. File://localhost/home/patrick/Documents/programming/python%20projects/UlyssesRedux/corpora/unsorted/index. Does that mean investors will make less money now is that now, you're steering. Some people may not be such a thing as Americanness. So there may be some things someone has to take whatever work he can get, and come in and convince them. The switch to the point where it IPOs, and you can ask about technical matters. It will seem preposterous to future generations. So rule number zero is: these rules exist for a reason.
You don't want mere voting; you need unanimity. If you're a founder, here's a handy tip for evaluating competitors. Unleashed, it could affect thousands of merchants, would probably end up working at Microsoft, or even frivolous.16 But that part, I'm convinced, is just the kind that tends to come back when they have no competitors. And when there's no installation, it will be a little frightening to be solving users' problems—perhaps even with an additional energy that comes from being in a small group of other people who did invent things, like features that confused users. What's different about your brain after you have experience, and then come back a year later and say I can't.17 In practice there are two great universities, but they're not willing to let people see an early draft if it will show up on some sort of padding to protect their misconceptions from bumping against reality.18 They're nearly all going to be a search for truth. And later stage investors have no problem paying $50 a month.
Notes
Whereas the activation energy for enterprise software.
The key to wasting time building it. There are also startlingly popular on pre-money valuation of the Web was closely tied to the inane questions of the tube. By your mid-twenties the people working for startups that get killed by overspending might have. If early abstract paintings seem more powerful version written in C and Perl.
For most of them.
Without the prospect of publication, the rest of the 800 highest paid executives at 300 big corporations. You can build things for programmers, but art is not one of them is a negotiation. Peter Thiel would point out that it's doubly important for societies to remember and pass on the richer end of World War II had become so embedded that they take a conscious effort. Few can have escaped alive, or black beans n cubes Knorr beef or vegetable bouillon n teaspoons freshly ground black pepper 3n teaspoons ground cumin n cups dry rice, preferably brown Robert Morris says that a startup in the beginning of the companies that grow slowly and never sell i.
Stone, op. To be fair, the angel is being able to raise more money was the ads they show first.
The main effect of low quality though.
A Bayesian Approach to Filtering Junk E-Mail. It was also obvious to your instruments. And they are at least guesses by pros about where those market caps will end up with only a sliver of it in the first meeting. The problem is not limited to startups.
No one writing a dictionary to pick the former, and although convertible notes, and it will seem to like uncapped notes, and others, no one thinks of calling that unfair. 5,000 computers attached to the biggest company of all, economic inequality as a definition of property without affecting and probably harming the state of technology. Probably just thirty, if we wanted to than because they wanted, so they had to find it was very much better to be significantly pickier.
Probabilities in this respect as so many startups from Philadelphia. Obviously this is the most demanding but also like an in-house VC fund they outsource most of the economy. As usual the popular image is several decades behind reality. I became an employer, I should add that none who read this to be a source of income and b not allow them to be a hot startup.
An influx of inexpensive but mediocre programmers is the fact that the main reason kids lie to adults. Enterprise software sold through traditional channels is very polite and b was popular in Germany, where there is nothing more unconvincing, for an investor, than to call the Metaphysics came after meta after the fact that the overall prior ratio seemed worthless as a separate feature. Wittgenstein asserted a sort of stepping back is one way to solve the problem is not that the path from ideas to startups has recently been getting smoother. Strictly speaking it's impossible without a time machine, how do you use the wrong side of the randomness is concealed by the government.
By heavy-duty security I mean type I startups. And doesn't get paid to work like they worked.
It wouldn't pay. If you did.
And when a wolf appears, is a list of n things seems particularly collectible because it's told with a million dollars in liquid assets are assumed to be able to grow big in revenues without including the numbers from the conventional wisdom on the young care so much that they're all that matters, just as European politics then had no government powerful enough to defend their interests in political and legal disputes.
Zagat's lists the Ritz Carlton Dining Room in SF as requiring jackets but I think it was worth it for the explanation of a company with benevolent aims is currently undervalued, because it was outlawed in the US. If you treat your classes, you need a higher growth rate to manufacture a perfect growth curve, etc, and once a hypothesis starts to be combined that never should have become good friends.
Then when we got to see it in the grave and trying to upgrade an existing investor, the technology everyone was going to be vigorously enforced. They may not be surprised how often the answer. Disclosure: Reddit was funded by Y Combinator only got 38 cents on the parental dole, and also really good at sniffing out any red flags about the size of a single project is a bad idea.
Then it's up to them. Successful founders are in set theory, combinatorics, and help keep the number of startups that have little do with down rounds—like full ratchet anti-dilution protections.
Parker, op.
I used to place orders. It seems quite likely that European governments of the potential magnitude of the reason the dictionaries are wrong is that the path from ideas to startups. Looking at the final version that by the time it takes a startup.
Thanks to Robert Morris, Sam Altman, Dan Bloomberg, Paul Watson, Daniel Giffin, and Jessica Livingston for sparking my interest in this topic.
#automatically generated text#Markov chains#Paul Graham#Python#Patrick Mooney#board#company#VC#kind#search#night#Watson#competition#topic#rice#Thiel#thinks#practice#people#startup#Robert#features#calculating#competitors#parents#years#print#Dan#someone#intelligence
1 note
·
View note
Text
Interview: Genesis Breyer P-Orridge (Throbbing Gristle, Psychic TV)
As one of the key originators of industrial music, organizer of the occult art collective Temple ov Psychick Youth, and participant in the ambitious body-altering pandrogyne project, Genesis Breyer P-Orridge has embodied the artistic process for over four decades. Observing and critiquing culture from the vantage point of a disruptor, P-Orridge draws from the teachings of William S. Burroughs and Brion Gysin, whom s/he counted as friends. Throughout the years, P-Orridge has dabbled in occult practices, pouring h/er thoughts out in a 500-page tome, Thee Psychick Bible. But h/er band Psychic TV also mastered the mainstream with the pop hit “Godstar,” which remained a number one song in Britain for months. Oh, and Psychic TV was also in the Guinness World Records for releasing the most albums in a year. That doesn’t mean P-Orridge rests on h/er prior achievements. Recently, s/he performed with Psychic TV at a rare show at this year’s Moogfest and was the subject of the documentary Bight of the Twin, which chronicled h/er experiences with Voodoo practitioners in Benin. A second documentary, A Message from the Temple, is forthcoming. --- Is there any kind of ritual or practice you undergo before going onstage with Psychic TV? No, no. There used to be a drinking ritual where we would get plastic bottles of water and put in vodka and cranberry or vodka and orange to take onstage, and that became this really ridiculous little ritual that we used to all do. And then everyone would all go and have a pee [laughs]. The band now is without any question my favorite lineup we’ve ever had. It’s basically stayed pretty stable since 2003. We’re on our third keyboard player. Our keyboard player seems to be a bit like the Spinal Tap drummer [laughs]. But we’re so bonded at this point that it’s a true organism. Everyone’s hyper aware of what’s happening in each other’s lives, what emotional journey they might be on at that given moment. So if we feel somebody needs encouragement, it just happens. Psychic TV is such an amazingly integrated organism that everything goes unsaid a lot of the time, but there’s an amazing amount of love. It really is a family in the truest sense. In Benin, when someone passes away, they say that “a twin goes to the forest to look for wood,” which is explored in Bight of the Twin. You’ve been involved with the idea of twins since at least the pandrogyne project, but there’s also a history of this in the Vodun religion. Yeah, as you carry on through life, you discover that there are twins in all sorts of hidden doctrines and groups with different belief systems. I mean, the Garden of Eden begins with twins. So we draw those into many experiences of rituals and psychedelic trips and what have you, and myself and Jaye concluded that either symbolically or literally, we were here to reunify as a species, that things like either/or, male/female, black/white, Christian/Muslim are all tools used to control us. The only way out of control is unity, where there is no difference. Therefore, no strategies are irrelevant. That’s why we felt pandrogyny was so important as an idea, and the twins idea in Africa was just confirmation on a really exciting, deep level. As the oldest continuous religion, Vodun would have the earliest concept of creation. We were asking them about their creation story. And they said, “In the beginning there was one god, Mahu, made up of both male and female parts named Segbo Lissa. Segbo is a female chameleon, and Lissa is a male python.” But they were one, or in other words, a pandrogyne. You can argue Adam and Eve is one being. In the earliest paintings of the Garden of Eden, the paintings were of God, Adam, and Eve, and they all have male and female genitals and breasts. The Vatican suppressed it, of course. So we’re not card-carrying dogma followers of anything, but we keep an extremely open mind. Psychic TV is such an amazingly integrated organism that everything goes unsaid a lot of the time, but there’s an amazing amount of love. It really is a family in the truest sense. Can you tell us about the idea of “occulture” you wrote about in Thee Psychick Bible? That was one of those words that just seemed inevitable. There’s a TOPY [Temple Ov Psychick Youth] member now in Asheville named Chandra Shukla who got involved with what we were doing on many levels when he was a teenager while living in a very traditional Asian family. He couldn’t bring himself to surrender into repetition of what his parents had lived, so he started looking for different stories. He’s working on a Psychick dictionary of all the phrases and slogans and new word definitions we’ve developed the last 50 years. Occulture was one of those words we just felt should always have existed. Even as a teenager, we’d read about Freemasons, the Process Church of the Final Judgment, different secret cabals, the Knights Templar, all these different organizations, some mythological, some actual, that were about, if you like, the real history of the world. Like what was the real reason that the first World War happened? It was a fight between two members of the same family, Queen Victoria and Kaiser Wilhelm, and they had a family argument and neither of them would back down, and then we have a war where millions die. So what were the real reasons that we went to war? Why was America so rich and powerful in the 50s? Profit came from the war where the Morgan bank financed both sides. If you start looking into the nitty gritty of where control really resides, there’s probably 100 families that tell us the primary story of what’s really gone on so far. Occulture is a great framework to think about these latent practices and organizations that have always been there throughout history outside of the mainstream. When I was a teenager, I started to daydream. “Wouldn’t it be fabulous if someone or myself identified the real history of the world?” It’s a long, big topic, but the bottom line is we’re constantly fed stimulation, but we’re not constantly fed education, and to me, that’s very suspicious. And it’s a vested interest. We want to keep the true story quiet. The real reasons that they decided to go to war in Iraq, was that for the oil or was that ego? We don’t know, but it wasn’t the reason they gave. A cult is hidden from the eye and culture is a control system. Occulture is also about people’s hidden motives. You know, Burroughs was brilliant at revealing these kinds of dynamics in society, and his work with Brion Gysin, with cutups, still to me is one of the greatest tools for breaking control, because it reveals things that cannot be revealed any other way except through what appears to be random chance. People now are surrendering on a level that we’ve never seen before. My years of mental formation were heavily influenced by the liberationist concepts of the 60s and some of the most positive changes that happened in society. Squatting, prison’s rights, organic food, gay rights, women’s rights, alternative medicine, yoga, there’s an endless list of changes that occurred. There’s a huge array of simple but identifiable improvements in the lot of humanity that came from that era, because we said, “Let’s take our daydreams really seriously. How would we like to be treated? How would we like to live? Why can’t we? There must be a way.” One of the ways we believe that has to come in the next real step of rebellion is communities. Not communes, but communities and collectives where people share their resources. So if there’s 10 of you, you don’t need 10 cars. Maybe three for emergencies. Sell the other seven and you’ve still all got access to cars. The money from those seven can buy a new computer that everyone uses or pay for the roof to be fixed. It’s always shocking to me how many people are terrified of sharing. They’ve been trained to think in terms of career as a success. You know, in the art world, which we’ve been dabbling in lately, it’s all about divine inspiration. It’s not a continuum, but in fact, everything that we make is a continuum. My life, I’m thrilled to say, is the result of all the different things that have happened and influenced me. All the people we’ve met, all the people that have spoken to me, all the places we’ve been, all the books we’ve read, all the music we’ve heard. All of that is what we then percolate and refine in order to make a response or create an object or a piece of music that we feel contains what we know so far in some way, in the hope it will inspire others to be less afraid of sharing. You were listed by Guinness World Records for the most albums released in one year. What was your work ethic like then? Well, I don’t know if it’s true anymore. I’m sure someone’s beaten us. A lot of them were live concerts released on vinyl. We were on CBS Records when we did Dreams Less Sweet, and then I wrote “Godstar,” a great little pop song, and I went in to Muff Winwood, the head of A&R, and I said, “Muff, listen to this tape.” And he went, “Hmm, it’s not weird like the other stuff.” I said, “No, but it’s a great pop song and this is what I want to do now. We’ve done the weird, now we want to do psychedelic pop.” And he said, “Oh, no, no, no. We don’t want the music to change like this. Your scene is weird music, so you’ve got to keep doing weird music.” And we said, “Muff, we just left your label. And I’m going to prove that even a monkey could make this into a hit record.” [laughs] I released it myself with a new label, Temple Records, and it was number one in the indie chart in Britain for 16 weeks, and it got into the top 30 in the national chart, too. It was our big hit. One of the ways we believe that has to come in the next real step of rebellion is communities. Not communes, but communities and collectives where people share their resources. To get the money to do a proper mix, I went to my bank manager and said, “Could you possibly loan me some money to remix this song?” And he went, “I don’t know, what’s the collateral element?” “Well, I don’t have any. I’m on the dole, living in a squat.” And I don’t know how, but the conversation changed and I was talking about bootlegs, and we came up with this idea to do a series of live albums that people collected, and each one had a token in it, and when you had all the tokens, you got a free record that was only available in that way. And on that agreement of me saying we’ll do that, he loaned me the money to do proper mixes and recordings of all the psychedelic stuff. That’s how we got in the Guinness World Records, because I was releasing a live album every month and then there were other records too, and it just built up to about 14 in a year or something, which at that time was a lot. We were next to Michael Jackson in the Guinness World Records. That’s really incredible. What’s the biggest thing you’ve learned from studying Austin Osman Spare? The potency of the orgasm. The idea that you can open up any inhibitions or gateways that might normally be closed between layers of consciousness and actually reprogram your neurology, your brain, your mind. That in fact the orgasm is a moment of absolute unity. And of course, two beings having a simultaneous orgasm is a superb image of androgyny where the two become one. Spare said that’s when you can reprogram a self. You decide how you really want to change or what you need to achieve. The choices you make afterwards, without you really being aware of it, will always be geared towards what your mind thinks is going to get you closer to the desired place. You’ll continue with certain activities, drop others, maybe end or begin a relationship, travel or stay home, whatever it is. Those decisions will be made to maximize your potential of reaching the most divine version of yourself. That’s what he taught me. Can you relate a memorable encounter you had with William S. Burroughs? Oh, god. [laughs] Memorable… I don’t know if it’s memorable. I’m trying to think… no, I can’t. I mean, there’s lots of little things, but it was the entirety that really made him so special. You know, at one point we came over to New York when we were still in England. I think it was in 1980 and we were in the bunker. William wanted to try the Raudive experiments of using a crystal radio set plugged into a tape recorder to get the voices of the dead to appear in the static. Have you ever heard about that? I haven’t, no. Konstantin Raudive — I think he’s Latvian — did a book called Breakthrough, and it’s just full of all these conversations with the dead recorded on blank tape using this little crystal set. It’s incredible, and there was a record with the book so that you could actually listen and hear some of them, but unfortunately, that’s been lost. But we recommend you have a look at that at least. Yeah, I’m definitely going to. That seems super interesting. It is. But we did it together, me and William. We still have the reel-to-reel tapes. You have to release those. Well, actually, it’s funny you should mention that, because when we did it, me and William listened to them back afterwards and, “Ah, there’s nothing.” [laughs] But now that technology’s improved we were just talking to Ryan Martin [of Dais Records], and he wants to play those tapes through really high-quality speakers and see whether we can hear things. The thing that made me a little bit unsure about Raudive is that most of the voices he heard were speaking in Latvian. And you think, “Really? Do they actually know that this is a Latvian speaking? Or is he just imagining Latvian because that’s his language?” Right, like out of all the languages, why would it be Latvian, or even something humans created? Yeah. So there’s a question mark, but it’s an interesting area. Certainly there are voices. That seems pretty definite. My hope would be that they’re voices from alternative dimensions. You know, when people take psychedelics, no one asks, “Why were you traveling? What did you want to learn that was so important and who did you want to benefit beyond yourself?” We think about all these people who now do DMT and ayahuasca as psychedelic tourists. It’s like Mount Everest, which is drowning under human feces and trash. People are leaving behind their consciousness trash. They’re popping into these other worlds where all the DMT creatures are and looking around. “Oh, wow, man. Look. Ooh.” Like they’re having a picnic at the zoo. Isn’t that really impolite? You know, in that kind of situation, we believe you should cleanse yourself, bathe, talk to the spirits, ask for permission, and really be hyper aware that you’re visiting somebody else’s world. The other thing I often wonder about is, are we ripping holes in the veil between these two alternate realities where things can come through into this apparent dimension that we didn’t invite? Now, what exactly is happening? It needs to be thought about much more seriously, in my opinion, before you do that. Now, are you letting things come back this way without even realizing it, and if you are, what are those things and what’s their agenda, and are you leaving a big mess like Mount Everest? Right, like it’s shortsighted for us to think that we can have these experiences without affecting either ourselves or another realm. Exactly, and it’s a typical short-sighted human response. It’s an aspect of the capitalist society that should be very carefully kept away from the sort of shamanic spiritual experience. If we make a mess on Everest, how dare we go somewhere even more precious until we know what we’re doing and we’re respectful? This is an example of thinking about things from different directions when you’re working, and that’s an occulture moment too, you know? What’s hidden in this process? What might be going on? And you can look at it and think of certain things that seem ridiculous. But maybe somebody’s having dinner in the DMT world and then we pop in going, “Hey, this is interesting. Oh, sorry I’ve stolen your food. Blah, blah, blah, blah.” It’s a great way to consider it. I never thought about it that way. Oh, good. Well, see, that’s what we’re here for. http://j.mp/2oLE5zt
0 notes