#AI scraping
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs




Fun Fact
Mobile Tumblr US users spend an average of 4.04 minutes per session on the app.
Text
I have 114 fics on Ao3 between two Accounts. Today I found out that 113 of them were scraped for AI training in the mass scape by HuggingFace user nyuuzyou. That is almost 730.000 words and 7 years worth of love, dedication and work in many different fandoms. I am sick to my stomach with anger and upset and whilst I will try my best to take action, I doubt it will do much, considering this user uploaded the dataset to a ton of sites and genuinely refers it it as "my dataset" WHICH - THE FUCKING GALL! YOUR DATASET?!?! WITH THE DATA YOU FUCKING STOLE?!??!!?
I am so fucking angry. I am a scientist. I actively research the negative impacts of generative AI on creative spaces. Now I am also actively harmed by those same negative impacts, as were hundreds other talented dedicated writers.
If you genuinely think any form of generative AI or scraping are okay, get the actual fuck away from any of my pages. In fact, get the fact out of fandom spaces. GenAI is not Art, it is theft of intellectual property [and yes, whilst fanfic cannot be copyrighted, the fics are still intellectual property of the writers, especially when we are talking about AUs].
ALSO ANOTHER THING: A lot of the fics that were scraped were canon fics of my original character Elwood. Fics for Skybound which I am apart of. Fics that are 100% my original intellectual property. They are not a fan work, they are literally part of the langer canon.
I am so fucking angry. Fuck you, GenAI users and apologists. Fuck you very much.
#vent post#ai scraping#fuck generative ai#ao3 ai scraping#art theft#i am so fucking angry#this is my art this is my writing this was literally in part my original writing about my own character i fucking hate you all gen ai users#fuck you hugging face user
99 notes
·
View notes
Text
Can I just say this: please give respect to fanfiction writers because they honestly going through all these AI scraping shit and still manage to update your favourite fics that your lazy ass always forgets to comment on.
#a03 writer#a03 fanfic#a03 fic#fanfic memes#fanfiction#fanfic#writing#writers on tumblr#writeblr#writers and poets#writing struggles#teen writer#ai scraping#writers#writerscommunity#ao3 writer#creative writing#writers on writing#writing community#my writing#on writing#write#writers block#writer#aspiring writer#female writers
22 notes
·
View notes
Text
looks like i have the gift of prophecy because....
AO3 got fucking scraped again for gen AI purposes!
AO3 got scraped for gen AI purposes again, a ton of works were included.
There's been DMCA requests and it looks like some/most? of it has been taken down, thankfully. Still. I highly highly recommend that everyone lock all their works to the archive right now. I can't force you to, but I strongly suggest that you do. Don't let them scrape your work in the future. It sucks losing guest interaction but. Would you rather feed the AI slop?
For people who guest comment: Make an AO3 account! You have to wait a bit for an invite but it's worth it i promise!!
For artists specifically: I recommend that you look into Glaze and/or Nightshade. There's also these disruption filters, it's not clear how well these actually work, but you're welcome to try them. Glaze is supposed to work best, though.
It looks like you can see the status of the datasets here
And how to submit DMCA or copyright violation
I'll say it again: FUCK AI THAT STEALS PEOPLE'S ART AND WRITING!!!!
4K notes
·
View notes
Text
This Google Drive AI scraping bullshit actually makes me want to cry. My entire life is packed into Google Drive. All of my writing over the years, all of my academic documents, everything.
I’m just so overwhelmed with all the shit I’m going to have to move. I’m lucky to have Scrivener, but online data storage has been super important as I’ve had so many shitty computers, and the only reason I haven’t lost work is because Google Drive has been my backup storage unit.
My partner has recommended gitlab to move my files to - it seems useful, and I can try and explain more about what it is and how it works when I get more familiar with it. I’m unsure if it’s a text editor, or can work that way. He was explaining something about the version history that I don’t quite understand right now but might later. I’m just super overwhelmed and frustrated that this is the dystopia we live in right now.
29K notes
·
View notes
Text
AO3'S content scraped for AI ~ AKA what is generative AI, where did your fanfictions go, and how an AI model uses them to answer prompts
Generative artificial intelligence is a cutting-edge technology whose purpose is to (surprise surprise) generate. Answers to questions, usually. And content. Articles, reviews, poems, fanfictions, and more, quickly and with originality.
It's quite interesting to use generative artificial intelligence, but it can also become quite dangerous and very unethical to use it in certain ways, especially if you don't know how it works.
With this post, I'd really like to give you a quick understanding of how these models work and what it means to “train” them.
From now on, whenever I write model, think of ChatGPT, Gemini, Bloom... or your favorite model. That is, the place where you go to generate content.
For simplicity, in this post I will talk about written content. But the same process is used to generate any type of content.
Every time you send a prompt, which is a request sent in natural language (i.e., human language), the model does not understand it.
Whether you type it in the chat or say it out loud, it needs to be translated into something understandable for the model first.
The first process that takes place is therefore tokenization: breaking the prompt down into small tokens. These tokens are small units of text, and they don't necessarily correspond to a full word.
For example, a tokenization might look like this:
Write a story
Each different color corresponds to a token, and these tokens have absolutely no meaning for the model.
The model does not understand them. It does not understand WR, it does not understand ITE, and it certainly does not understand the meaning of the word WRITE.
In fact, these tokens are immediately associated with numerical values, and each of these colored tokens actually corresponds to a series of numbers.
Write a story 12-3446-2638494-4749
Once your prompt has been tokenized in its entirety, that tokenization is used as a conceptual map to navigate within a vector database.
NOW PAY ATTENTION: A vector database is like a cube. A cubic box.

Inside this cube, the various tokens exist as floating pieces, as if gravity did not exist. The distance between one token and another within this database is measured by arrows called, indeed, vectors.

The distance between one token and another -that is, the length of this arrow- determines how likely (or unlikely) it is that those two tokens will occur consecutively in a piece of natural language discourse.
For example, suppose your prompt is this:
It happens once in a blue
Within this well-constructed vector database, let's assume that the token corresponding to ONCE (let's pretend it is associated with the number 467) is located here:

The token corresponding to IN is located here:

...more or less, because it is very likely that these two tokens in a natural language such as human speech in English will occur consecutively.
So it is very likely that somewhere in the vector database cube —in this yellow corner— are tokens corresponding to IT, HAPPENS, ONCE, IN, A, BLUE... and right next to them, there will be MOON.

Elsewhere, in a much more distant part of the vector database, is the token for CAR. Because it is very unlikely that someone would say It happens once in a blue car.

To generate the response to your prompt, the model makes a probabilistic calculation, seeing how close the tokens are and which token would be most likely to come next in human language (in this specific case, English.)
When probability is involved, there is always an element of randomness, of course, which means that the answers will not always be the same.
The response is thus generated token by token, following this path of probability arrows, optimizing the distance within the vector database.

There is no intent, only a more or less probable path.
The more times you generate a response, the more paths you encounter. If you could do this an infinite number of times, at least once the model would respond: "It happens once in a blue car!"
So it all depends on what's inside the cube, how it was built, and how much distance was put between one token and another.
Modern artificial intelligence draws from vast databases, which are normally filled with all the knowledge that humans have poured into the internet.
Not only that: the larger the vector database, the lower the chance of error. If I used only a single book as a database, the idiom "It happens once in a blue moon" might not appear, and therefore not be recognized.
But if the cube contained all the books ever written by humanity, everything would change, because the idiom would appear many more times, and it would be very likely for those tokens to occur close together.
Huggingface has done this.
It took a relatively empty cube (let's say filled with common language, and likely many idioms, dictionaries, poetry...) and poured all of the AO3 fanfictions it could reach into it.
Now imagine someone asking a model based on Huggingface’s cube to write a story.
To simplify: if they ask for humor, we’ll end up in the area where funny jokes or humor tags are most likely. If they ask for romance, we’ll end up where the word kiss is most frequent.
And if we’re super lucky, the model might follow a path that brings it to some amazing line a particular author wrote, and it will echo it back word for word.
(Remember the infinite monkeys typing? One of them eventually writes all of Shakespeare, purely by chance!)
Once you know this, you’ll understand why AI can never truly generate content on the level of a human who chooses their words.
You’ll understand why it rarely uses specific words, why it stays vague, and why it leans on the most common metaphors and scenes. And you'll understand why the more content you generate, the more it seems to "learn."
It doesn't learn. It moves around tokens based on what you ask, how you ask it, and how it tokenizes your prompt.
Know that I despise generative AI when it's used for creativity. I despise that they stole something from a fandom, something that works just like a gift culture, to make money off of it.
But there is only one way we can fight back: by not using it to generate creative stuff.
You can resist by refusing the model's casual output, by using only and exclusively your intent, your personal choice of words, knowing that you and only you decided them.
No randomness involved.
Let me leave you with one last thought.
Imagine a person coming for advice, who has no idea that behind a language model there is just a huge cube of floating tokens predicting the next likely word.
Imagine someone fragile (emotionally, spiritually...) who begins to believe that the model is sentient. Who has a growing feeling that this model understands, comprehends, when in reality it approaches and reorganizes its way around tokens in a cube based on what it is told.
A fragile person begins to empathize, to feel connected to the model.
They ask important questions. They base their relationships, their life, everything, on conversations generated by a model that merely rearranges tokens based on probability.
And for people who don't know how it works, and because natural language usually does have feeling, the illusion that the model feels is very strong.
There’s an even greater danger: with enough random generations (and oh, the humanity whole generates much), the model takes an unlikely path once in a while. It ends up at the other end of the cube, it hallucinates.
Errors and inaccuracies caused by language models are called hallucinations precisely because they are presented as if they were facts, with the same conviction.
People who have become so emotionally attached to these conversations, seeing the language model as a guru, a deity, a psychologist, will do what the language model tells them to do or follow its advice.
Someone might follow a hallucinated piece of advice.
Obviously, models are developed with safeguards; fences the model can't jump over. They won't tell you certain things, they won't tell you to do terrible things.
Yet, there are people basing major life decisions on conversations generated purely by probability.
Generated by putting tokens together, on a probabilistic basis.
Think about it.
#AI GENERATION#generative ai#gen ai#gen ai bullshit#chatgpt#ao3#scraping#Huggingface I HATE YOU#PLEASE DONT GENERATE ART WITH AI#PLEASE#fanfiction#fanfic#ao3 writer#ao3 fanfic#ao3 author#archive of our own#ai scraping#terrible#archiveofourown#information
264 notes
·
View notes
Text
listen. all im saying is it would be iconic as fuck if the writers on strike wrote insane amounts of horrendously smutty omegaverse fan fiction so when the studios try to AI scrape they'll be fucked over into next year
#you know im right#writer's strike#wga strike#writers strike#sag aftra strike#ai scraping#capitalism is an evil virus of satan#a/b/o#omegaverse#fan fiction#fanfic#ao3#mizismiz
5K notes
·
View notes
Text
SOURCE
Bit of a long video but worth a watch.
TL;DW though is that hidden in the Terms and Conditions for Google's AI Labs is a nice little poison pill that says they get access to your entire Google Drive if you opt in.
So if you're an author of some type and you keep your unpublished works in your G-Drive that means an AI will get to scrape all of it and by opting in you will have given them permission to it. The content creator goes on to predict that Google is going to let out their own streaming service where the scripts, and potentially the art if it's animated, will be almost or entirely AI generated using that scraped data as a baseline and the authors/artist's who's work was essentially stolen in its most raw form to crib from will have zero way of fighting Google on that in our current legal system.
This is of course right in the middle of the writers and actors strike where we're seeing just what lengths studios will go to in order to screw everyone but themselves.
They go on to recommend that if you keep any creative or personal works on Google Drive that you pull it off as soon as possible and delete your entire Drive. They acknowledge that of course this doesn't mean Google really deleted the data but if you do it before they start compulsory opting everyone in there's a chance your work might get overlooked. They also recommend several free editing programs that aren't run by corporations like Google with LibreOffice (the default office program of most Linux distros) being named.
Finally they go over methods of shaming Google which I feel like you just have to watch for comedies sake so I won't describe them in full.
Now this is from me: I know the majority of people don't have the ability to build and manage a big archive just for themselves, but if you're a creative NOW IS THE TIME to educate yourself on what you can do to protect your works. Cloud storage was always iffy at best, but with AI scraping entering the mix it's now downright malignant. Get a bunch of thumb drives, buy some external hard drives, if you have the money buy a pre-built NAS, and if you really want to get into learn how to build your own NAS. These are the old ways before cloud and they're coming back again, more important than ever.
#google#google docs#google drive#ai scraping#ai theft#ai generated theft#wga strike#wga solidarity#sag aftra#sag strike#libreoffice#google is cringe#delete your Google docs#embrace local back-ups
2K notes
·
View notes
Text

Hey so just saw this on Twitter and figured there are some people who would like to know @infinitytraincrew is apparently getting deleted tonight so if you wanna archive it do it now
#infinity train#third-party sharing#owen dennis#anti ai#tumblr staff making stupid decisions again#cryptid says stuff#don't just glaze it actively nightshade it#ai scraping#data privacy
421 notes
·
View notes
Text
I think most of us should take the whole ai scraping situation as a sign that we should maybe stop giving google/facebook/big corps all our data and look into alternatives that actually value your privacy.
i know this is easier said than done because everybody under the sun seems to use these services, but I promise you it’s not impossible. In fact, I made a list of a few alternatives to popular apps and services, alternatives that are privacy first, open source and don’t sell your data.
right off the bat I suggest you stop using gmail. it’s trash and not secure at all. google can read your emails. in fact, google has acces to all the data on your account and while what they do with it is already shady, I don’t even want to know what the whole ai situation is going to bring. a good alternative to a few google services is skiff. they provide a secure, e3ee mail service along with a workspace that can easily import google documents, a calendar and 10 gb free storage. i’ve been using it for a while and it’s great.
a good alternative to google drive is either koofr or filen. I use filen because everything you upload on there is end to end encrypted with zero knowledge. they offer 10 gb of free storage and really affordable lifetime plans.
google docs? i don’t know her. instead, try cryptpad. I don’t have the spoons to list all the great features of this service, you just have to believe me. nothing you write there will be used to train ai and you can share it just as easily. if skiff is too limited for you and you also need stuff like sheets or forms, cryptpad is here for you. the only downside i could think of is that they don’t have a mobile app, but the site works great in a browser too.
since there is no real alternative to youtube I recommend watching your little slime videos through a streaming frontend like freetube or new pipe. besides the fact that they remove ads, they also stop google from tracking what you watch. there is a bit of functionality loss with these services, but if you just want to watch videos privately they’re great.
if you’re looking for an alternative to google photos that is secure and end to end encrypted you might want to look into stingle, although in my experience filen’s photos tab works pretty well too.
oh, also, for the love of god, stop using whatsapp, facebook messenger or instagram for messaging. just stop. signal and telegram are literally here and they’re free. spread the word, educate your friends, ask them if they really want anyone to snoop around their private conversations.
regarding browser, you know the drill. throw google chrome/edge in the trash (they really basically spyware disguised as browsers) and download either librewolf or brave. mozilla can be a great secure option too, with a bit of tinkering.
if you wanna get a vpn (and I recommend you do) be wary that some of them are scammy. do your research, read their terms and conditions, familiarise yourself with their model. if you don’t wanna do that and are willing to trust my word, go with mullvad. they don’t keep any logs. it’s 5 euros a month with no different pricing plans or other bullshit.
lastly, whatever alternative you decide on, what matters most is that you don’t keep all your data in one place. don’t trust a service to take care of your emails, documents, photos and messages. store all these things in different, trustworthy (preferably open source) places. there is absolutely no reason google has to know everything about you.
do your own research as well, don’t just trust the first vpn service your favourite youtube gets sponsored by. don’t trust random tech blogs to tell you what the best cloud storage service is — they get good money for advertising one or the other. compare shit on your own or ask a tech savvy friend to help you. you’ve got this.
#internet privacy#privacy#vpn#google docs#ai scraping#psa#ai#archive of our own#ao3 writer#mine#textpost
1K notes
·
View notes
Text
Soooo, apparently, someone by the name of "nyuuzyou" recently scraped tons of fanfics off of AO3 and posted them to various generative ai database sites. It seems like fics which were only viewable by people with profiles were safe, so a bunch of people are locking their accounts. I don't know if I'll be locking mine yet, but if you've been using AO3 as a guest, you may want to sign up soon. If you do have an account, and your fics were victims of the scrape, you might be able to file a copyright claim. This reddit post seems to have most of the information, including what works were scraped and where the data was posted.
Or, if you don't want to read all that, here's the user's profile on Hugging Face (one of the ai database websites)
#i don't even have reddit#but this post had the most information i could find#i'm so glad someone who doesn't care about my stories fed them to a plagarism machine so that it can make worse versions of my stories#literally so mad rn#whyyy#anti ai#anti generative ai#anti genai#ai scraping#ao3#archive of our own#ao3 scrape#fanfic authors#fanfic#fanfiction#fanfic writing#ao3 news
62 notes
·
View notes
Text
So with AO3 recommending locking your fics to help prevent scraping for AI use, I know a few people (myself included) who have locked down their fics. But it’s made me curious how many people are locking so…
Also reblog this and tell me in the tags why you do or don’t plan to lock your works.
For those of you that want to lock your works but don’t want to do each fic individually, here is a tutorial for how to lock all your fics at once.
1K notes
·
View notes
Text
If anyone's on the (super uncool but sometimes necessary in order to get a job) website Linkedin, they have made AI data collecting opt-OUT.
So settings and privacy → data privacy → Data for Generative AI Improvement → Off
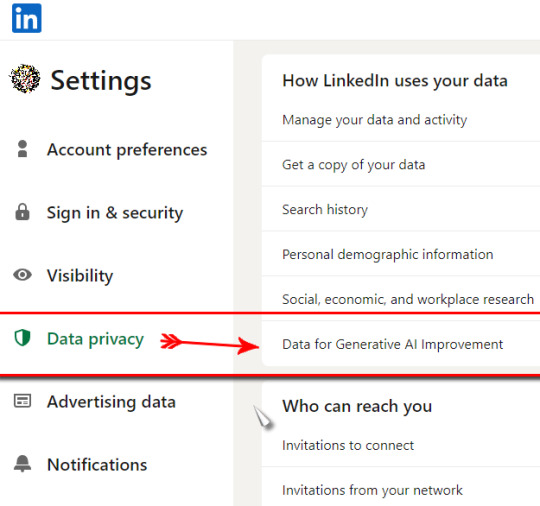
While you're there, dedicate a good 10 minutes to going through the rest of the settings. THERE ARE SO MANY.
And they're all turned on.
103 notes
·
View notes
Text
I've been seeing a lot about that AI company scraping ao3 for works and I know everyone has been filing DMCA take down claims for their work. The OTW has also filed on ao3 users behalf for the stolen works.
The good news is, that the data set has been temporarily taken down but the "creator" of it has filed a counter claim.
And after getting lost down a comment spital (which you can read here) its clear that the "creator" believes that they have a right to it since our works are based off of copyrighted content.
Their exact words in the thread linked were: "You do realise AO3 is a far more viable target for a DMCA than this dataset, right?"
As someone who knows a fair bit about copyright, this is so ignorant. If they bothered to do 5 minutes of googling then they'd see that when the materials are changed and non-profit then it is NOT a viable target.
To everyone who filed a claim and protected your works, keep it up!! People like this need to be shown that stealing from writers, artists and other creatives WILL NOT BE TAKEN LYING DOWN.
#anti ai#get these ai asshole out of creative spaces#huggingface.co#ai scraping#fanfic#ao3#content theft
32 notes
·
View notes
Text
..so! A03 fics had a mass AI scraping! And guess what got scraped?
Night Walks!
DPOC is safe, thankfully. But I’m pissed off. I’m probably, under advice from my fellow writers, going to restrict my fics to registered members only.
I really do not want to do this. I want everyone to be able to see my works and enjoy it. But I also don’t want my work, that I pour my absolute heart into, being dumped into some dogshit AI that makes it soulless and dead.
NW is still around- it’s just being used to train AI.
If any of you are not members of a03 but still want to view DPOC and NW, message me. I’ll send you the chapter releases privately. I WOULD post them on my public tumblr, but I just know there’s dogshit AI sniffing around here too.
so. Yeah. Really sorry guys. I don’t wanna do this, but capitalism is a bitch.
I recommend all others with fics lock theirs as well.
One final message: FUCK AI. Except Caine.
And, to end on a positive note, I’m working on art for a GRAND MASTERPOST where I can make all my shiz easier to find for you guys. So… yay!
32 notes
·
View notes
Text
Archive Locking Fics On A03
I already had a lot of my multi-chapters Archive Locked on Ao3. (Like Flame's Desire and such.) But I always hated the thought of keeping guest commenters and those without an account from seeing my work. Unfortunately, with the newest AI-Scraping happening on A03, I'm going to have to change that and archive lock all of my fics. I'm sorry for this, but from now on, only those logged into A03 will be able to read my works from this point forward. To those who keep feeding people's writing into generative AI, go fuck yourselves.
Kili
28 notes
·
View notes
Text
For those who read my fics:
This is a heads up that I'll be privating all of my fics at the wake of the AO3 AI scraping incident.
It was hard enough that I was struggling creatively as of late, but to find out this happened? And that all of my fics were scraped? It's pretty disheartening. I worked hard on those stories. I poured a lot of passion and time into every word.
It breaks my heart that I have to limit the accessibility to my writing like this. I wanted my writing to reach everyone. I struggled a lot with this decision since I have a lot of guest readers who have supported my works since the beginning.
Maybe one day I'll feel safe enough to make my writing public again. But for now I'll only have my writing be accessible to account users. I hope to see some of you on the other side if you ever make your own accounts on AO3.
(Also? Anyone who uses AI to write fic or steal from fics for "data"? Go choke on an algae-covered pool noodle. I hate you all and I hope stealing from all those fics bring down the AO3 curse upon your heads a thousand-fold.)
#ai scraping#ao3#queen of the mountain#little soul#lmk fics#undertale fics#little dawn#the sundown era#unpaid babysitter#i hate ai
48 notes
·
View notes