#Analytics and Data Analysis
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr posted its first advertisements in May 2012 and subsequently earned $13M in revenue.
Text
The Value of Aged Domains
The Value of Aged Domains
Is the age of a domain a game-changer in the world of SEO? Let's explore the intriguing realm of aged domains and their impact on search engine rankings. Are they a shortcut to success or just another piece of the puzzle?
Renowned SEO experts have shared contrasting opinions on the importance of aged domains. Rand Fishkin, co-founder of Moz, emphasizes the natural SEO advantage of older domains, highlighting their age and the abundance of backlinks they likely possess. However, Neil Patel, co-founder of Crazy Egg, Hello Bar, and KISSmetrics, cautions that while aged domains can offer a shortcut to SEO success, thorough research and diligence are crucial.
#Social Media Marketing#Search Engine Optimization (SEO)#Content Marketing#Email Marketing#Pay-Per-Click (PPC) Advertising#Influencer Marketing#Affiliate Marketing#Online Public Relations (PR)#Analytics and Data Analysis#Mobile Marketing#Video Marketing#Social Media Advertising#Search Engine Marketing (SEM)#Customer Relationship Management (CRM)#E-commerce Marketing
1 note
·
View note
Text
Currently in a "love"/"hate" relationship with James Vowels if all the reports coming out of the media about Logan and true right now.
You can scroll through my posts and see how good Logan has been doing all year.... especially when you consider his car never gets upgraded and has been way over weight compared to his competitors.
But what has James done since Bahrain? Nothing but talk crap to the media about Logan. Took his car away in Australia, constantly let's rumors fly and starts them about replacing him, spent all of his energy chasing Sainz and then gushing about him to anyone with a Mic.
Like damn James what the hell did you expect Logan to do? Further more the fact that he refuses to acknowledge Logan is indeed performing with a cement brick of a car is so sad.
Logan has crashed twice all year, which is a major improvement.
100 notes
·
View notes
Text
Hey everyone! enjoying my (two) week break of uni, so I've been lazy and playing games. Today, working on Python, I'm just doing repetition of learning the basics; Variables, Data types, Logic statements, etc. Hope everyone has a good week!
#codeblr#coding#python#university#uni life#studying#datascience#data analytics#data analysis#studyblr#student life#study motivation#study blog#student
78 notes
·
View notes
Text
data analysis is rly like
it's so over we're so back it's so over we're so back it's so over
i know, i know, negative results don't make my work any less valid but cmon please give me something
#science#stem#stemblr#academia#studyblr#neuroscience#stem student#data#data analytics#data analysis#research
46 notes
·
View notes
Text

#tua#the umbrella academy#klaus hargreeves#luthor hargreeves#diego hargreeves#allison hargreeves#five hargreeves#ben hargreeves#viktor hargreeves#victor hargreeves#pogo hargreeves#grace hargreeves#reginald hargreeves#statistic#statistics#datascience#data analytics#data analysis#data
21 notes
·
View notes
Text
New Business Marketing Tips And Tricks for Success
Starting a new business can be an exciting endeavor, but it also comes with its fair share of challenges, especially in the competitive landscape of today's market. Effective marketing is crucial for the success of any new venture. Here are four essential marketing tips and tricks to help your new business thrive.
Define Your Target Audience: Before diving into marketing efforts, it's essential to identify and understand your target audience. Define your ideal customer persona by considering demographics, interests, pain points, and buying behaviors. Conduct market research to gather valuable insights that will guide your marketing strategies. Tailoring your messages and campaigns to resonate with your target audience will significantly increase your chances of success.
Once you have a clear picture of your audience, choose the most suitable marketing channels to reach them effectively. Social media, email marketing, content marketing, and pay-per-click advertising are just a few options to consider. Your choice of channels should align with where your audience spends their time online.

Create Compelling Content: Content marketing is a powerful tool for new businesses to establish their brand and build credibility. Develop high-quality, informative, and engaging content that addresses the needs and interests of your target audience. This content can take various forms, including blog posts, videos, infographics, and podcasts.
Consistency is key when it comes to content creation. Develop a content calendar to plan and schedule regular updates. Providing valuable content not only helps you connect with your audience but also boosts your search engine rankings, making it easier for potential customers to find you.

Leverage Social Media: Social media platforms have become indispensable for marketing in today's digital age. Create profiles on relevant social media platforms and engage with your audience regularly. Share your content, interact with followers, and participate in industry-related discussions.
Paid advertising on social media can also be a cost-effective way to reach a broader audience. Platforms like Facebook, Instagram, and LinkedIn offer targeting options that allow you to reach users who match your ideal customer profile.

Monitor and Adapt: Marketing is an ever-evolving field, and what works today may not work tomorrow. To stay ahead of the curve, regularly monitor the performance of your marketing efforts. Analyze key metrics such as website traffic, conversion rates, and return on investment (ROI). Use tools like Google Analytics and social media insights to gather data and insights.
Based on your findings, be prepared to adapt your strategies and tactics. If a particular marketing channel isn't delivering the expected results, reallocate your resources to more promising avenues. Stay up-to-date with industry trends and keep an eye on your competitors to ensure your marketing efforts remain relevant and competitive.
In conclusion, effective marketing is essential for the success of any new business. By defining your target audience, creating compelling content, leveraging social media, and continuously monitoring and adapting your strategies, you can position your new business for growth and long-term success in a competitive market. Remember that success may not come overnight, but with persistence and the right marketing approach, your new business can thrive.

#business#digitalbusiness#digitalmarketing#seo#market analysis#data analytics#marketing#management#sales#learn digital marketing#Digital marketing course#seo expert#business success#businessgrowth
88 notes
·
View notes
Text
youtube
Statistics - A Full Lecture to learn Data Science (2025 Version)
Welcome to our comprehensive and free statistics tutorial (Full Lecture)! In this video, we'll explore essential tools and techniques that power data science and data analytics, helping us interpret data effectively. You'll gain a solid foundation in key statistical concepts and learn how to apply powerful statistical tests widely used in modern research and industry. From descriptive statistics to regression analysis and beyond, we'll guide you through each method's role in data-driven decision-making. Whether you're diving into machine learning, business intelligence, or academic research, this tutorial will equip you with the skills to analyze and interpret data with confidence. Let's get started!
#education#free education#technology#educate yourselves#educate yourself#data analysis#data science course#data science#data structure and algorithms#youtube#statistics for data science#statistics#economics#education system#learn data science#learn data analytics#Youtube
4 notes
·
View notes
Text
Spreadsheet to track Fanfic Data
I've spend way to much time making a google sheet to track all the various data I can get from the fanfics I read, I know that there are extensions you can download that will do this for you automatically, but there is no way I'm giving my AO3 data to an external database!
This sheet tracks:
Number of Fics and Wordcount per day over time
Number of Fics and Wordcount for the top Fandoms you read
Most read Authors
Number of Fics and Wordcount for various Tags and Tropes
Number of each Relationship Rating (m/m, f/m, gen, etc)
Number of each Content Rating (E, M, G, etc)
All of this is done automatically from the data you input, none of the data is pulled from anywhere else, and it is not stored anywhere but the sheet itself- it's completely private
All you need to do is make a copy of this sheet (https://docs.google.com/spreadsheets/d/10pSMAvUymrK48SbkBMplELNHG3B-mgv8nLORhBBIS8Y/edit?usp=sharing) and follow the instructions of how to input the data.
Blog Tags
#soyo recs - fanfiction recommendations, both chosen weekly from by own spreadsheet, and as responses to asks
#soyo long - weekly recommendation, over 100,000 words
#soyo medium - weekly recommendation, between 100,000 and 20,000 words
#soyo short - weekly recommendation, under 20,000 words
#fic-data spreadsheet - more information about the spreadsheet, including screenshots from my own, instructions for use (that are also included in the sheet itself) and responses to asks about the sheet.
#soyo talks - my own random posts
#archive of our own#ao3#ao3 fanfic#fanfic#fanfiction#data#data analysis#fanfiction analytics#fic-data spreadsheet
11 notes
·
View notes
Text
Unlock the other 99% of your data - now ready for AI
New Post has been published on https://thedigitalinsider.com/unlock-the-other-99-of-your-data-now-ready-for-ai/
Unlock the other 99% of your data - now ready for AI
For decades, companies of all sizes have recognized that the data available to them holds significant value, for improving user and customer experiences and for developing strategic plans based on empirical evidence.
As AI becomes increasingly accessible and practical for real-world business applications, the potential value of available data has grown exponentially. Successfully adopting AI requires significant effort in data collection, curation, and preprocessing. Moreover, important aspects such as data governance, privacy, anonymization, regulatory compliance, and security must be addressed carefully from the outset.
In a conversation with Henrique Lemes, Americas Data Platform Leader at IBM, we explored the challenges enterprises face in implementing practical AI in a range of use cases. We began by examining the nature of data itself, its various types, and its role in enabling effective AI-powered applications.
Henrique highlighted that referring to all enterprise information simply as ‘data’ understates its complexity. The modern enterprise navigates a fragmented landscape of diverse data types and inconsistent quality, particularly between structured and unstructured sources.
In simple terms, structured data refers to information that is organized in a standardized and easily searchable format, one that enables efficient processing and analysis by software systems.
Unstructured data is information that does not follow a predefined format nor organizational model, making it more complex to process and analyze. Unlike structured data, it includes diverse formats like emails, social media posts, videos, images, documents, and audio files. While it lacks the clear organization of structured data, unstructured data holds valuable insights that, when effectively managed through advanced analytics and AI, can drive innovation and inform strategic business decisions.
Henrique stated, “Currently, less than 1% of enterprise data is utilized by generative AI, and over 90% of that data is unstructured, which directly affects trust and quality”.
The element of trust in terms of data is an important one. Decision-makers in an organization need firm belief (trust) that the information at their fingertips is complete, reliable, and properly obtained. But there is evidence that states less than half of data available to businesses is used for AI, with unstructured data often going ignored or sidelined due to the complexity of processing it and examining it for compliance – especially at scale.
To open the way to better decisions that are based on a fuller set of empirical data, the trickle of easily consumed information needs to be turned into a firehose. Automated ingestion is the answer in this respect, Henrique said, but the governance rules and data policies still must be applied – to unstructured and structured data alike.
Henrique set out the three processes that let enterprises leverage the inherent value of their data. “Firstly, ingestion at scale. It��s important to automate this process. Second, curation and data governance. And the third [is when] you make this available for generative AI. We achieve over 40% of ROI over any conventional RAG use-case.”
IBM provides a unified strategy, rooted in a deep understanding of the enterprise’s AI journey, combined with advanced software solutions and domain expertise. This enables organizations to efficiently and securely transform both structured and unstructured data into AI-ready assets, all within the boundaries of existing governance and compliance frameworks.
“We bring together the people, processes, and tools. It’s not inherently simple, but we simplify it by aligning all the essential resources,” he said.
As businesses scale and transform, the diversity and volume of their data increase. To keep up, AI data ingestion process must be both scalable and flexible.
“[Companies] encounter difficulties when scaling because their AI solutions were initially built for specific tasks. When they attempt to broaden their scope, they often aren’t ready, the data pipelines grow more complex, and managing unstructured data becomes essential. This drives an increased demand for effective data governance,” he said.
IBM’s approach is to thoroughly understand each client’s AI journey, creating a clear roadmap to achieve ROI through effective AI implementation. “We prioritize data accuracy, whether structured or unstructured, along with data ingestion, lineage, governance, compliance with industry-specific regulations, and the necessary observability. These capabilities enable our clients to scale across multiple use cases and fully capitalize on the value of their data,” Henrique said.
Like anything worthwhile in technology implementation, it takes time to put the right processes in place, gravitate to the right tools, and have the necessary vision of how any data solution might need to evolve.
IBM offers enterprises a range of options and tooling to enable AI workloads in even the most regulated industries, at any scale. With international banks, finance houses, and global multinationals among its client roster, there are few substitutes for Big Blue in this context.
To find out more about enabling data pipelines for AI that drive business and offer fast, significant ROI, head over to this page.
#ai#AI-powered#Americas#Analysis#Analytics#applications#approach#assets#audio#banks#Blue#Business#business applications#Companies#complexity#compliance#customer experiences#data#data collection#Data Governance#data ingestion#data pipelines#data platform#decision-makers#diversity#documents#emails#enterprise#Enterprises#finance
2 notes
·
View notes
Text
Understanding Outliers in Machine Learning and Data Science

In machine learning and data science, an outlier is like a misfit in a dataset. It's a data point that stands out significantly from the rest of the data. Sometimes, these outliers are errors, while other times, they reveal something truly interesting about the data. Either way, handling outliers is a crucial step in the data preprocessing stage. If left unchecked, they can skew your analysis and even mess up your machine learning models.
In this article, we will dive into:
1. What outliers are and why they matter.
2. How to detect and remove outliers using the Interquartile Range (IQR) method.
3. Using the Z-score method for outlier detection and removal.
4. How the Percentile Method and Winsorization techniques can help handle outliers.
This guide will explain each method in simple terms with Python code examples so that even beginners can follow along.
1. What Are Outliers?
An outlier is a data point that lies far outside the range of most other values in your dataset. For example, in a list of incomes, most people might earn between $30,000 and $70,000, but someone earning $5,000,000 would be an outlier.
Why Are Outliers Important?
Outliers can be problematic or insightful:
Problematic Outliers: Errors in data entry, sensor faults, or sampling issues.
Insightful Outliers: They might indicate fraud, unusual trends, or new patterns.
Types of Outliers
1. Univariate Outliers: These are extreme values in a single variable.
Example: A temperature of 300°F in a dataset about room temperatures.
2. Multivariate Outliers: These involve unusual combinations of values in multiple variables.
Example: A person with an unusually high income but a very low age.
3. Contextual Outliers: These depend on the context.
Example: A high temperature in winter might be an outlier, but not in summer.
2. Outlier Detection and Removal Using the IQR Method
The Interquartile Range (IQR) method is one of the simplest ways to detect outliers. It works by identifying the middle 50% of your data and marking anything that falls far outside this range as an outlier.
Steps:
1. Calculate the 25th percentile (Q1) and 75th percentile (Q3) of your data.
2. Compute the IQR:
{IQR} = Q3 - Q1
Q1 - 1.5 \times \text{IQR}
Q3 + 1.5 \times \text{IQR} ] 4. Anything below the lower bound or above the upper bound is an outlier.
Python Example:
import pandas as pd
# Sample dataset
data = {'Values': [12, 14, 18, 22, 25, 28, 32, 95, 100]}
df = pd.DataFrame(data)
# Calculate Q1, Q3, and IQR
Q1 = df['Values'].quantile(0.25)
Q3 = df['Values'].quantile(0.75)
IQR = Q3 - Q1
# Define the bounds
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# Identify and remove outliers
outliers = df[(df['Values'] < lower_bound) | (df['Values'] > upper_bound)]
print("Outliers:\n", outliers)
filtered_data = df[(df['Values'] >= lower_bound) & (df['Values'] <= upper_bound)]
print("Filtered Data:\n", filtered_data)
Key Points:
The IQR method is great for univariate datasets.
It works well when the data isn’t skewed or heavily distributed.
3. Outlier Detection and Removal Using the Z-Score Method
The Z-score method measures how far a data point is from the mean, in terms of standard deviations. If a Z-score is greater than a certain threshold (commonly 3 or -3), it is considered an outlier.
Formula:
Z = \frac{(X - \mu)}{\sigma}
is the data point,
is the mean of the dataset,
is the standard deviation.
Python Example:
import numpy as np
# Sample dataset
data = {'Values': [12, 14, 18, 22, 25, 28, 32, 95, 100]}
df = pd.DataFrame(data)
# Calculate mean and standard deviation
mean = df['Values'].mean()
std_dev = df['Values'].std()
# Compute Z-scores
df['Z-Score'] = (df['Values'] - mean) / std_dev
# Identify and remove outliers
threshold = 3
outliers = df[(df['Z-Score'] > threshold) | (df['Z-Score'] < -threshold)]
print("Outliers:\n", outliers)
filtered_data = df[(df['Z-Score'] <= threshold) & (df['Z-Score'] >= -threshold)]
print("Filtered Data:\n", filtered_data)
Key Points:
The Z-score method assumes the data follows a normal distribution.
It may not work well with skewed datasets.
4. Outlier Detection Using the Percentile Method and Winsorization
Percentile Method:
In the percentile method, we define a lower percentile (e.g., 1st percentile) and an upper percentile (e.g., 99th percentile). Any value outside this range is treated as an outlier.
Winsorization:
Winsorization is a technique where outliers are not removed but replaced with the nearest acceptable value.
Python Example:
from scipy.stats.mstats import winsorize
import numpy as np
Sample data
data = [12, 14, 18, 22, 25, 28, 32, 95, 100]
Calculate percentiles
lower_percentile = np.percentile(data, 1)
upper_percentile = np.percentile(data, 99)
Identify outliers
outliers = [x for x in data if x < lower_percentile or x > upper_percentile]
print("Outliers:", outliers)
# Apply Winsorization
winsorized_data = winsorize(data, limits=[0.01, 0.01])
print("Winsorized Data:", list(winsorized_data))
Key Points:
Percentile and Winsorization methods are useful for skewed data.
Winsorization is preferred when data integrity must be preserved.
Final Thoughts
Outliers can be tricky, but understanding how to detect and handle them is a key skill in machine learning and data science. Whether you use the IQR method, Z-score, or Wins
orization, always tailor your approach to the specific dataset you’re working with.
By mastering these techniques, you’ll be able to clean your data effectively and improve the accuracy of your models.
#science#skills#programming#bigdata#books#machinelearning#artificial intelligence#python#machine learning#data centers#outliers#big data#data analysis#data analytics#data scientist#database#datascience#data
4 notes
·
View notes
Text

Pickl.AI offers a comprehensive approach to data science education through real-world case studies and practical projects. By working on industry-specific challenges, learners gain exposure to how data analysis, machine learning, and artificial intelligence are applied to solve business problems. The hands-on learning approach helps build technical expertise while developing critical thinking and problem-solving abilities. Pickl.AI’s programs are designed to prepare individuals for successful careers in the evolving data-driven job market, providing both theoretical knowledge and valuable project experience.
#Pickl.AI#data science#data science certification#data science case studies#machine learning#AI#artificial intelligence#data analytics#data science projects#career in data science#online education#real-world data science#data analysis#big data#technology
2 notes
·
View notes
Text
Michael Schumacher All-Time Race Record
As promised, next up we have THE definitive G.O.A.T of the 90s-10's. There may have been other WDC, Fast competitive drivers, but no one…NO ONE compared to the dominance that is Michael Schumacher or Iconic as him in his scarlet Ferrari. He dominated in a ton of different models of cars, regulations, rules, safety procedures and more. No one holds more WDC's then Michael as he has 7 with 5 of them being back to back from 2000-2004. He may not have as many overall race wins as Sir Lewis Hamilton, but there is no doubt that Michael is the iconic vision of a Formula One driver.
Throughout his 19-year career which went from 1991 to 2006 and 2010 to 2012; he racked in a total of 91 wins, 41 runner-up podiums, 22 third place podiums, 64 point finishes, 17 outside the points, and 65 DNFs. Racing with V10s, V8s, Hyrbrids, No HANS, with HANS, Points only going to only 6th, 8th, and 10th. There is not a single major era of formula one that he has not been apart of. Even the Ground effect era was something he did, just not this 2022+ version that we have now.

Noticeable points throughout his legacy:
DNF'd in Japan his first 3 years until 1994 (which was also his first WDC)
Was on pace in 1997 and 1999 to win another WDC but in 97 he was DSQ from the whole championship and in 1999 he broke his leg with a massive shunt at the British Grand Prix
Had more "out of the points finishes" from 2010-2012 then he did from 1991-2006 combined. aka. 'POINTS OR NOTHING'
Missed 7 races in 1997 from July to September, and Missed 3 races in 1994 due to a broken rib. STILL WON THE WDC in 94.

#f1#f1 analysis#data analytics#History of F1#formula one#michael schumacher#benetton#beenetton f1#scuderia ferrari#ferrari f1#world drivers championship#mercedes formula one#lewis hamilton#nelson piquet#martin brundle#nico rosberg#eddie irvine#rubens barrichello#felipe massa#jos verstappen#johnny herbert#riccardo patrese
27 notes
·
View notes
Text
Hey! and welcome back!
As Uni is about to begin in a few days....I upgraded to a third monitor! Also!! I job a Data entry job! Big things moving forward :)
Let me introduce myself;
I'm Mick, (she/her) and I currently study Data Analytics. I'll be 26 in July and I love to read and play video games in my free time. I also like to watch football (LIVERPOOL xx)
Im currently taking the time to learn Excel and Python. However, I know for school I'll be learning Python, SQL and maybe some other things.
FOLLOW me along on this journey and if you have any questions please ask!
#codeblr#python#coding#data analytics#study blog#study motivation#studyblr#student life#excel#student#physics#maths#pc setup#data analysis#data entry work#data entry projects#data scientist#study aesthetic
31 notes
·
View notes
Text
i get to work with time series data at work & im excited about it
#one step closer to becoming hermann gottlieb lmao#it's also interesting because it's like. the first job ive had where they just expect me to figure stuff out??#sort of anyway#like i have been given a thing to manage#they taught me how to do parts of that but basically im in charge of analysis#and like. figuring out WHAT needs doing#which means i get to watch stats videos at work 💕#my plan for the next week or so is like. every morning check how the thing is doing & make changes as needed#and then if i have extra time use that to refine my analytics approaches#which for now means setting up R so i can get the data in there lmao#we have a dashboard but the dashboard is best for eyeballin it#personal
3 notes
·
View notes
Text
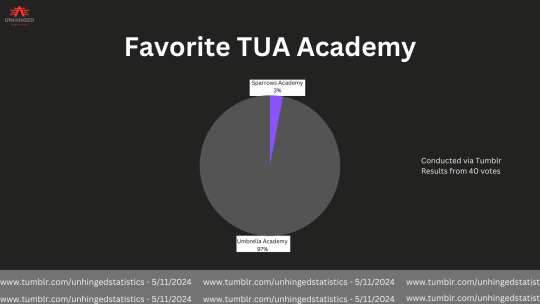
#the umbrella academy#umbrella acedmy#sparrows academy#tua#statistics#statistic#data analytics#datascience#data#data analysis
13 notes
·
View notes
Text
Trading is about timing. If you don’t understand what cycle the market is in, when to identify manipulation and when to target that manipulation - you’re never going to see this setup.
Each previous market session gives us vital clues on what we’re looking for and when to look for it.
For more join us .
#forex#forex education#forex expert advisor#forex indicators#forexmentor#forex broker#forex market#forexsignals#forexmastery#crypto#learn forex trading in jaipur#jaipur#forex jaipur#rajasthan#learn forex trading#intradaytrading#market strategy#technical analysis#data analytics#analysis
2 notes
·
View notes