#delete the datasets
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The total number of visits Tumblr.com received during January 2021 is 327 million.
Text


I tried nightshade and glaze with this painting from 2019!
Protect your images from genAI with Glaze! Paintings, photos, 3D renders... everything! Tell your friends!
32 notes
·
View notes
Text
I think that if a person knows that something was made using trained on unethically sourced data AI. And still uses it/likes it/supports it/defends it.
Then said person should stop "being mad" when their data is used to train AI without consent.
#nitunio.txt#please dont half-ass it in terms of not supporting this stuff#if you like and willingly use writing AI that scrapes web without consent#then turn around and say 'wahh AI bad' when it concerns digital art. you're just a hypocrite#same goes for photos and music and other creative work#if you come across any 'machine learning AI generation' website immediately go to their FAQ or About sections#just see for yourself if they provide any sources for the data they've used and if it was consensual and only after that#ask yourself if you should be using it or just make something yourself#hell you can even ask somebody or pay somebody to do something you can't do. thats the joy of community#and even then there are many resources that were already made to be used for free with or without credit#i ramble a lot about things like these bc i cant just wrap my head around it#i just need all of these scraped datasets to burn down and self-delete
2 notes
·
View notes
Text
The justice league sees Batman periodically updating a database of his, at the oddest of times, and naturally they think it's got something to do with his contingency plans or a dataset about the Gotham rogues, but in reality it's just him keeping record of his many children's changing tastes
Superman: Woah, he's writing down with such concentration, wonder what could be in there, maybe a new villain in Gotham?
Bruce, writing: "Dick has refused his favourite Pb&J five mornings in a row. Delete from favourites. Ask for new favourite food."
"Jason didn't seem as Eager to read the new book by his favourite author, put it in neutral category."
"Tim chose a green shirt instead of a red one at the mall today. More research needed."
"Cass listened to arctic monkeys on repeat this week. Update to favourites."
"Duke expressed an interest in slam poetry and called band practice lame. Put poetry in favourites and band in neutral."
"Damian watched Bluey for a total of 50 hours this week. Update to favourites."
#he's aware it's a bit stalkerish. but.#batdad is way more fun when he carries over the incessant paranoia from his batman gig over to his father gig#it makes it all so delicious#dick grayson#jason todd#batfam#bruce wayne#tim drake#damian wayne#batman#cassandra cain#duke thomas#nightwing#red hood#red robin#robin#batgirl#dc headcanon#batfamily headcanons#orphan dc#batfamily#batfam headcanons#batfam hcs#dc#dc comics#batfam shenanigans#incorrect batfamily quotes#incorrect batfam#incorrect batman quotes#clark kent
18K notes
·
View notes
Text
AO3 Ship Stats: Year In Bad Data
You may have seen this AO3 Year In Review.

It hasn’t crossed my tumblr dash but it sure is circulating on twitter with 3.5M views, 10K likes, 17K retweets and counting. Normally this would be great! I love data and charts and comparisons!
Except this data is GARBAGE and belongs in the TRASH.
I first noticed something fishy when I realized that Steve/Bucky – the 5th largest ship on AO3 by total fic count – wasn’t on this Top 100 list anywhere. I know Marvel’s popularity has fallen in recent years, but not that much. Especially considering some of the other ships that made it on the list. You mean to tell me a femslash HP ship (Mary MacDonald/Lily Potter) in which one half of the pairing was so minor I had to look up her name because she was only mentioned once in a single flashback scene beat fandom juggernaut Stucky? I call bullshit.
Now obviously jumping to conclusions based on gut instinct alone is horrible practice... but it is a good place to start. So let’s look at the actual numbers and discover why this entire dataset sits on a throne of lies.
Here are the results of filtering the Steve/Bucky tag for all works created between Jan 1, 2023 and Dec 31, 2023:
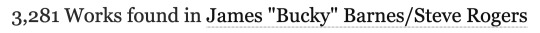
Not only would that place Steve/Bucky at #23 on this list, if the other counts are correct (hint: they're not), it’s also well above the 1520-new-work cutoff of the #100 spot. So how the fuck is it not on the list? Let’s check out the author’s FAQ to see if there’s some important factor we’re missing.
The first thing you’ll probably notice in the FAQ is that the data is being scraped from publicly available works. That means anything privated and only accessible to logged-in users isn’t counted. This is Sin #1. Already the data is inaccurate because we’re not actually counting all of the published fics, but the bots needed to do data collection on this scale can't easily scrape privated fics so I kinda get it. We’ll roll with this for now and see if it at least makes the numbers make more sense:
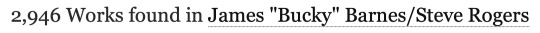
Nope. Logging out only reduced the total by a couple hundred. Even if one were to choose the most restrictive possible definition of "new works" and filter out all crossovers and incomplete fics, Steve/Bucky would still have a yearly total of 2,305. Yet the list claims their total is somewhere below 1,500? What the fuck is going on here?
Let’s look at another ship for comparison. This time one that’s very recent and popular enough to make it on the list so we have an actual reference value for comparison: Nick/Charlie (Heartstopper). According to the list, this ship sits at #34 this year with a total of 2630 new works. But what’s AO3 say?
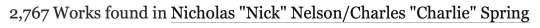
Off by a hundred or so but the values are much closer at least!
If we dig further into the FAQ though we discover Sin #2 (and the most egregious): the counting method. The yearly fic counts are NOT determined by filtering for a certain time period, they’re determined by simply taking a snapshot of the total number of fics in a ship tag at the end of the year and subtracting the previous end-of-year total. For example, if you check a ship tag on Jan 1, 2023 and it has 10,000 fics and check it again on Jan 1, 2024 and it now has 12,000 fics, the difference (2,000) would be the number of "new works" on this chart.
At first glance this subtraction method might seem like a perfectly valid way to count fics, and it’s certainly the easiest way, but it can and did have major consequences to the point of making the entire dataset functionally meaningless. Why? If any older works are deleted or privated, every single one of those will be subtracted from the current year fic count. And to make the problem even worse, beginning at the end of last year there was a big scare about AI scraping fics from AO3, which caused hundreds, if not thousands, of users to lock down their fics or delete them.
The magnitude of this fuck up may not be immediately obvious so let’s look at an example to see how this works in practice.
Say we have two ships. Ship A is more than a decade old with a large fanbase. Ship B is only a couple years old but gaining traction. On Jan 1, 2023, Ship A had a catalog of 50,000 fics and ship B had 5,000. Both ships have 3,000 new works published in 2023. However, 4% of the older works in each fandom were either privated or deleted during that same time (this percentage is was just chosen to make the math easy but it’s close to reality).
Ship A: 50,000 x 4% = 2,000 removed works Ship B: 5,000 x 4% = 200 removed works
Ship A: 3,000 - 2,000 = 1,000 "new" works Ship B: 3,000 - 200 = 2,800 "new" works
This gives Ship A a net gain of 1,000 and Ship B a net gain of 2,800 despite both fandoms producing the exact same number of new works that year. And neither one of these reported counts are the actual new works count (3,000). THIS explains the drastic difference in ranking between a ship like Steve/Bucky and Nick/Charlie.
How is this a useful measure of anything? You can't draw any conclusions about the current size and popularity of a fandom based on this data.
With this system, not only is the reported "new works" count incorrect, the older, larger fandom will always be punished and it’s count disproportionately reduced simply for the sin of being an older, larger fandom. This example doesn’t even take into account that people are going to be way more likely to delete an old fic they're no longer proud of in a fandom they no longer care about than a fic that was just written, so the deletion percentage for the older fandom should theoretically be even larger in comparison.
And if that wasn't bad enough, the author of this "study" KNEW the data was tainted and chose to present it as meaningful anyway. You will only find this if you click through to the FAQ and read about the author’s methodology, something 99.99% of people will NOT do (and even those who do may not understand the true significance of this problem):


The author may try to argue their post states that the tags "which had the greatest gain in total public fanworks” are shown on the chart, which makes it not a lie, but a error on the viewer’s part in not interpreting their data correctly. This is bullshit. Their chart CLEARLY titles the fic count column “New Works” which it explicitly is NOT, by their own admission! It should be titled “Net Gain in Works” or something similar.
Even if it were correctly titled though, the general public would not understand the difference, would interpret the numbers as new works anyway (because net gain is functionally meaningless as we've just discovered), and would base conclusions on their incorrect assumptions. There’s no getting around that… other than doing the counts correctly in the first place. This would be a much larger task but I strongly believe you shouldn’t take on a project like this if you can’t do it right.
To sum up, just because someone put a lot of work into gathering data and making a nice color-coded chart, doesn’t mean the data is GOOD or VALUABLE.
#ao3#ao3 stats#psa#my words#fandom#I doubt anyone is even going to read this but I needed to get it out of my system and at least try to stop this from spreading#if you know me#you know I get Big Mad about misinformation#don't take anything at face value#do your own research
4K notes
·
View notes
Text
PSA: Your AO3 work might have been scraped for a GenAI dataset
(PLEASE NOTE: At this time, access to the dataset has been disabled. You can file a DMCA takedown request if your work is included in the scraped data to campaign for full deletion, but at this time it is considered unnecessary.)
This is intended as a general notification for all the writers following this blog who post on AO3.
Approximately 12.6 million public works were scraped from AO3 and several other published-work sites, including PaperDemon, which has regular updates on the situation as well as resources. Here is the link to their updates.
Affected AO3 users are those whose work IDs were public-facing (that is to say, not locked to registered AO3 users only), and whose work IDs are between 1 and 63,200,000.
Your work ID is the number in your work's site URL, like so:

This work has an ID only in the 61-million range, and so was scraped for the dataset.
If you wish to lock your works to be visible to logged-in users only, you can do so through Works > Edit Works > All > Edit > Only show to registered users.
#mod ziva#ao3#genai#ao3 scrape#as of time of posting the user has uploaded to at least 2 other dataset sites as well as huggingface
310 notes
·
View notes
Text
I wonder if those AI-twats know how rapey they sound when they send me messages like "you should just lean back and relax and let people take what they want. You can't stop it anyway."
Gee, I do wonder why artists don't like ya all.
What an enigma.
aka: having anon asks open is a fucking adventure. <3

Since my most recent post made a few people aware that I might not be a big fan of certain usages of machine learning and image generators, I felt I should make one thing clear. Again. uwu
✧・゚: ✧・゚:Fuck AI.:・゚✧:・゚✧
✧・゚: ✧・゚:Fuck NFTs.:・゚✧:・゚✧
✧・゚: ✧・゚:Fuck people who claim AI regurgitated images are "art".:・゚✧:・゚✧
✧・゚: ✧・゚:And especially fuck people who tag it as "traditional art" or "artists on tumblr".:・゚✧:・゚✧
✧・゚: ✧・゚:You are nothing else but scalpers and scammers and I will never support you.:・゚✧:・゚✧
✧・゚: ✧・゚:Don't like this? Well, lucky you! This is not an airport and you can leave without having to notify anybody about your departure! The unfollow button is there for a reason! <;3 :・゚✧:・゚✧
With love: dra <3
3K notes
·
View notes
Text

Focus of your research: EXTREME PETTINESS AND UNWILLINGNESS TO LET ANYTHING GO
Research Account [Explained]
Transcript
[A shot of a webpage entitled "Application for Research Account". The page is cut off the end of a dropdown form asking for the institution, for which the response is "other/none".
Under it is the form "reason for requesting access to our datasets", under which is written "to win an argument with someone in a group chat".]
[The action "select all" is written, followed by the action "delete".]
[The same form, only now with the response "independent research".]
[Cueball sat at a desk, typing on a laptop.]
Caption: I never know how honest to be on these forms.
2K notes
·
View notes
Text
Update on the AI scrapping situation
I really wish I didn't have to make another post about this, but here we are.
The AO3 dataset, while currently unavaible on the HuggingFace website. has been made into a downloadable, still avaible Torrent file by the person who scrapped AO3
And all the others are avaible here too!
This person scrapped all of these works, whether they be drawings or writings, for AI purposes and to sell them!
The website datafish, the one these are avaible on, is based in Russia, and from what I know it's not responding to DMCAs. Despite all these datasets consisting of stolen work, so far nothing has been done against these!
This was brought to my attention by @mazois in the previous post's comment section, and I've did a little bit of further digging into this, but just know I'm not an expert in this! I'm just another scared person who's work was stolen
This dataset is still downloadable! This can still be downloaded and used by anyone who wishes for it!
Now I really hate doing these tumblr posts, mostly because I shouldn't need to, but also because I kind of feel like I'm bothering people with this, but I just want everyone to have a chance to do something about this.
Right now I don't know if the same approach will work with this one. Even enough DMCAs get filed, maybe something will get done. But I don't know. All I know is that these things are still avaible, even at least one of those that were deleted off of HuggingFace
Now I've tagged the same things as before, with a couple extra added tags, and I'll also link the last post relating to this issue here
Now, while this is a shitty situation, please do not harrass this person! Not because of the whole don't get on their level or whatever, but because it might help them get these datasets back online if they can say they've been harrassed over this! If we want something to get done about this, we must not give this person ground to push back!
Sorry to bother everyone about this again, but I wanted to share this in case someone wanted to know this.
#anti ai#fuck ai#anti genai#fuck genai#anti generative ai#fuck generative ai#Scientist Eclipse's Adventures#Watchful Nightmare#Witching Hours#Witching Hours fic#I refuse! fic#Scientist Solar's Adventures#Embrace the Deep#Embrace the Deep fic#Chasing your memory#ao3 author#ao3 writer#ao3 fanfic#writers on tumblr#artists on tumblr#the sun and moon show#sun and moon show#tsams#sams#the eclipse and puppet show#eclipse and puppet show#teaps#eaps#the lunar and earth show#lunar and earth show
259 notes
·
View notes
Text
AO3 Data Scraped for AI Training Dataset
What is happening, and what you can do. Check for potential edits with additions at the end of the post!
What is happening? What do we know?
A user going by "nyuuzyou" on the HuggingFace platform uploaded a dataset a few days ago - containing scraped content from AO3. HuggingFace is a very popular platform and widely used for sharing machine learning and AI models/datasets. The scraped dataset includes fics, fanart, and other fanworks - all taken without permission and intended for use in training gen AI models. You can find more information in this Reddit post.
This dataset is one of several compiled from various websites—at least seven in total. While two datasets have been removed, the AO3 one was only disabled on HuggingFace. This means that it’s not downloadable at the moment but still visible. It may also return if takedown efforts end up being challenged/reversed by that user.
Key Details
Scope: On AO3, all content with work IDs between 1 and 63,200,000 has been targeted. The work ID is the number at the end of a work's URL — for example, in https://archiveofourown.org/works/12345678, 12345678 is the work ID. You can find it by simply opening the work and checking the URL in your browser’s address bar. So, if your work falls in that range and is publicly accessible (i.e., not locked and open to everyone, including guests), it’s mostly likely included in the dataset. This dataset is currently disabled on HuggingFace, but that doesn't mean it's gone. It's only a temporary takedown as of now.
Takedown notices have been issued, but this user has also uploaded the dataset to other sites after backlash and partial removal.
There are talks in the discussion forums of potentially moving this dataset to Telegram, torrents, and/or other private channels.
HuggingFace AO3 dataset page
Other distributed sites listed here (as per a Reddit comment)
Currently deleted from ModelScope
What can you do?
Should the dataset return again and you see that your work was affected: file your own DMCA or copyright takedown notice. The uploader, in their own words, "has not agreed to take down the entire repo. At this time, the scraper has agreed with taking down art from the person who owns the copyright. That means each of you will need to request a takedown."
Instructions and a sample CSV template to list your work IDs for removal are provided in this guide. You can find more details in this announcement by PaperDemon.
Lock your works! It would limit visibility to registered users only, and is a very good step to prevent scraping or unauthorized use. To lock all your works on AO3, go to “My Works,” click “Edit Works,” and select all. Then click “Edit” and check the box labeled “Only show to registered users.” Scroll down and click “Update All Works” to apply the change.
⚠️ | Final Notes:
This user has so far shown no signs of stopping and is continuing to redistribute the data across multiple sites, even after numerous takedown requests (read more here). So, we can only recommend to be cautious and beware, lock your works, feel free to make use of takedown notices if you're unfortunately affected, and spread the word to fellow creators.
Follow up on this and get the latest updated in the Fanfic Communities Network (FCN) Discord Server!
If you have more information regarding this - e.g. if works from other sites are affected too - please reach out to us in the FCN!!
Edit (2025-04-26):
The user who has scraped the works has, upon request by another person, posted a way to convert ao3 json to markdown:
https://huggingface.co/datasets/nyuuzyou/archiveofourown/discussions/170
https://gist.github.com/nyuuzyou/b2f83669ad80a22e435728245ebcdf9f
This shows us that nyuuzyou continues to show no signs of taking down the scraped works.
Edit (2025-04-28):
A user warned that even archive-locked AO3 fics were included in a scraped dataset (most likely taken while the scraper was logged in, before they were banned or switched to public-only access). Some public works were missed as well:
https://huggingface.co/datasets/nyuuzyou/archiveofourown/discussions/213#680fcdb76d9e022324a70cf1
Edit (2025-05-03):
Hey everybody, this is a bit late, but the AO3 dataset has been permanently removed from HuggingFace: https://huggingface.co/datasets/nyuuzyou/archiveofourown. While this unfortunately doesn’t prevent it from being shared elsewhere (like torrents) nor does it guarantee any deletion of past downloads and whatnot, having it taken down from a major platform like HF is still a significant step forward. (There is more info about other sites on PaperDemon.)
So please don’t be disheartened—every action counts, and this shows that pushing back and filing DMCAs and copyright notices as appropriate does make a difference. We’ll certainly keep an eye out for more info and post updates here, but thank you again to everyone who helped report, spread the word, or supported the effort. Keep reading, keep writing. ♥️
#fanfiction#community#discordserver#fanfiction community#theft#ao3 works being stolen#fanfic theft#fanfiction stealing#ao3
157 notes
·
View notes
Text
Hi yeah so it’s been hours and I’m still really sad about this actually.
All my fellow fic writing moots pls go and archive lock all your ao3 uploads. Sure we can’t take back what they’ve already stolen but if they go back in or they do it again, at least your work will be safer :(
2 notes
·
View notes
Text
How Trump is reshaping reality by hiding data
Curating reality is an old political game, but Trump’s sweeping statistical purges are part of a broader attempt to reinvent “truth.”

Trump appears to be turning the federal government into its own 1984-style Ministry of Truth.

This is a gift 🎁 link so there is no paywall to read it. Below are some excerpts/highlights.
By Amanda Shendruk and Catherine Rampell | March 11, 2025 The Trump administration is deleting taxpayer-funded data — information that Americans use to make sense of the world. In its absence, the president can paint the world as he pleases. We don’t know the full universe of statistics that has gone missing, but the U.S. DOGE Service’s wrecking ball has already left behind a wasteland of 404 pages. All sorts of useful information has disappeared, including data on:

[...]

[See more under the cut.]
Three cases of legerdemath and other tricks up Trump’s sleeve
Deleting data isn’t the only way to manipulate official statistics. Trump and his allies have also misrepresented or altered data. Here are a few examples: 1. Incorrect data

Witness DOGE’s bogus statistics on its supposed government savings. The administration counts as “savings” some canceled contracts that had already been paid in full. Some canceled expenses were created out of whole cloth, such as $50 million supposedly spent on sending condoms to Gaza. 2. Misrepresented data

One of Trump’s favorite charts on immigration is riddled with errors. For one, it does not show the number of immigrants entering the United States illegally, as he claims, but the number of people stopped at the U.S. border. Similarly, when Commerce Secretary Howard Lutnick was recently asked how much DOGE funding cuts might reduce economic growth, he suggested that the agency might decide to change how economic growth is calculated so that the usual GDP report strips out government spending altogether. This would be an abrupt change to the standard GDP methodology that has been used around the world for nearly a century, but it would certainly make the DOGE cuts look less painful. 3. Altered data

When data doesn’t tell the story Trump wants, he fabricates it. In what became known as “Sharpiegate,” Trump notoriously altered a map of Hurricane Dorian’s path in 2019.


Likewise, before Jan. 30, a National Institutes of Health website documenting years of spending data included a category called “Workforce Diversity and Outreach.” That line item is now gone — even though the money was, indeed, spent.
Taking cues from authoritarian illusionists
Such actions are straight out of authoritarian leaders’ playbooks. Research suggests that less democratic countries have been more likely to inflate their GDP growth rates and manipulate their covid-19 numbers. Statistical manipulation is also more common in countries that shun economic openness and democracy. [...] To be clear, efforts to rewrite reality via statistical manipulation often don’t work. If anything, China’s data deletions reduced public confidence in the country’s economic stability. (No one hides good news, after all.) The Trump team’s efforts to suppress nettlesome numbers have similarly eroded trust in U.S. data. Only about one-third of Americans trust that most or all of the statistics Trump cites are “reliable and accurate.”

Meanwhile, missing or untrustworthy data lead to worse decisions: Auto companies, for example, draw on dozens of federally administered datasets when devising new car models, how to price them, where to stock and market them and other key choices. Retailers need detailed information about local demographics, weather and modes of transit when deciding where to locate stores. Doctors require up-to-date statistics about disease spread when diagnosing or treating patients. Families look at school test scores and local crime rates when deciding where to move. Politicians use census data when determining funding levels for important government programs.

And of course, voters need good data of all kinds when weighing whether to throw the bums out. Many of us take the existence of economic or public health stats for granted, without even thinking about who maintains them or what happens if they go away. Fortunately, some outside institutions have been saving and archiving endangered federal data. The Internet Archives’ Wayback Machine, for instance, crawls sites around the internet and has become an invaluable resource for seeing what federal websites used to contain. Other organizations are archiving topic-specific data and research, such as on the environment or reproductive health. These are critical but ultimately insufficient efforts. At best, they can preserve data already published. But they cannot update series already halted or purged.... Some private companies may step in to offer their own substitutes (on prices, for example), but private companies still rely on government statistics to calibrate their own numbers. Much of the most critical information about the state of our union can be collected only by the state itself. Americans might be stuck with whatever Trump chooses to share with us, or not.
#government data#donald trump#hiding government data#manipulating government data#manipulating the truth#autocracy#1984#ministry of truth#amanda shendruk#catherine rampell#michelle kondrich#sethinsua#the washington post#my edits
196 notes
·
View notes
Text
Excerpt from this story from Common Dreams:
Climate defenders and farmers sued the Trump administration in federal court on Monday over "the U.S. Department of Agriculture's unlawful purge of climate-related policies, guides, datasets, and resources from its websites."
The complaint was filed in the Southern District of New York by Earthjustice and the Knight First Amendment Institute at Columbia University on behalf of the Environmental Working Group (EWG), Natural Resources Defense Council (NRDC), and Northeast Organic Farming Association of New York (NOFA-NY).
The case focuses on just one part of Republican President Donald Trump's sweeping effort to purge the federal government and its resources of anyone or anything that doesn't align with his far-right agenda, including information about the fossil fuel-driven climate emergency.
"USDA's irrational climate change purge doesn't just hurt farmers, researchers, and advocates. It also violates federal law several times over," Earthjustice associate attorney Jeffrey Stein said in a statement. "USDA should be working to protect our food system from droughts, wildfires, and extreme weather, not denying the public access to critical resources."
Specifically, the groups accused the department of violating the Administrative Procedure Act, Freedom of Information Act, and Paperwork Reduction Act. As the complaint details, on January 30, "USDA Director of Digital Communications Peter Rhee sent an email ordering USDA staff to 'identify and archive or unpublish any landing pages focused on climate change' by 'no later than close of business' on Friday, January 31."
"Within hours, and without any public notice or explanation, USDA purged its websites of vital resources about climate-smart agriculture, forest conservation, climate change adaptation, and investment in clean energy projects in rural America, among many other subjects," the document states. "In doing so, it disabled access to numerous datasets, interactive tools, and essential information about USDA programs and policies."
EWG Midwest director Anne Schechinger explained that "by wiping critical climate resources from the USDA's website, the Trump administration has deliberately stripped farmers and ranchers of the vital tools they need to confront the escalating extreme weather threats like droughts and floods."
182 notes
·
View notes
Text
Everyone listen up! Owen Dennis is deleting the Infinity Train crew blog (infinitytraincrew) because of Tumblr selling people's art to AI datasets.

I want to preserve the art, so I'll be reblogging the posts from that account. REMEMBER TO TURN OFF THIRD-PARTY SHARING IN YOUR BLOG SETTINGS! Also, here's Glaze, which protects your art from AI.
Update: turns out that Glaze does not actually work. please reblog this version instead!
742 notes
·
View notes
Text
AI Scraping Response from r/AO3 mods
AO3’s Data Was Scraped For AI: What To Know
News/Updates
Hi all—as you may be aware, there’s been an incident regarding the Archive’s data being used to potentially train generative AI.
It seems that a user by the name of nyuuzyou conducted an unauthorized scrape of the Archive, both artwork and writing (as well as at least seven other websites) and uploaded the dataset to the machine-learning website Huggingface. This only scraped publicly available works—archive-locked works do not appear to be a part of that dataset. The works in the set are from as recent as March of this year, and comprise all publicly available works before then.
AO3 is aware of this, and they have filed a DCMA takedown to Huggingface, where the data has been made temporarily unavailable (aka nobody is currently able to use it for training). In response, the uploader filed a counterclaim to try to get it reinstated—though as Huggingface’s Terms of Service don’t allow uploads of any content the uploader doesn’t own the rights to, it’s unlikely that their counterclaim will succeed. However, the user also uploaded the dataset to two more websites after the Huggingface takedown: modelscope and datafish. These two sites are based in China and Russia respectively, places that do not always respond to DCMA takedowns—however, the upload to modelscope does appear to have been taken down/deleted as of writing this. (We also cannot link to these websites as Reddit has them shadowbanned).
The website Paperdemon has more information about the timelines, other websites affected, and how to request a DCMA takedown to Huggingface (which will hopefully not be necessary, but a good resource in case the counterclaim succeeds.)
As scraping like this is unfortunately hard to control, the best option we can recommend as a subreddit is to lock your works to only be available to registered archive users (as they are less likely to be scraped, though this is not foolproof). For readers, if you do not have an account, you will need to make one to be able to view archive-locked works. You can find a link to our most recent invite request thread here, or add your email to the signup waitlist on AO3 to get an invite directly in a few days.
~Cthulu (and the rest of the mod team)
Original post is here.
114 notes
·
View notes
Note
hi so, thanks to your tool i was able to figure out that every fic ive ever posted onto ao3 (from 2015 to recent, aside from three fics this last month i just posted) were all scraped, and its absolutely horrifying to me to know my works are being used in this way. this is hundreds of thousands of words of time, and is over 90% of all of the writing ive ever shared online, spread over multiple accounts and fandoms and im just feeling- so dejected. i know youre not an advice blog or anything, and i really appreciate the work youve done to help people find this information. im just curious- do you have any advice when it comes to dealing with this knowledge? i dont want to delete my fics and take them from people who enjoy them, and i want to continue to write and see others read my works. but its just so dejecting knowing what theyre being used for now. that i dont have any control over what is done with my own passion projects because some company can show up and just take it and use it in some environment-poisoning misinformation machine
I wasn't expecting to be ASKED for advice when I made the blog! But I give it my best shot for you guys when I can.
So to ME, it's a bit reassuring to see that the data isn't like. Amazingly collected, if that makes sense. If I were looking for a dataset to generate good writing, a huge thing I would want is a way to know what readers actually liked. For the record, having a low hit or kudos count or whatever does not mean your fic isn't good! (You can have a low hit count because your fandom isn't big or because you're not tagging your fic in a way to help the right people discover it, but the fic can still be amazing.) BUT if I were an outsider not looking to actually read the fics, just figure out what about the writing makes people like them, the top thing I'd be looking for is the stats like the hits, kudos, comments, and bookmarks. Nyuuzyou intentionally tried to exclude that data, which is... an interesting decision.
The choice of forum is telling, too. They chose to upload on Hugging Face, which is for AI hobbyists, not corporate models. These are people like you and me, just doing this as a hobby for fun, and it's pretty unlikely they'll ever create something they can sell from this. Yes, they're killing the environment with it, which I hate, but they're doing it on a much smaller scale than any of the commercial names in AI. Very similar to how you can post a fic and even get tens of thousands of hits and tons of positive interactions, but that doesn't mean you also publish traditional novels and make tens of thousands of dollars.
Again, for me, it also helps to remind myself that hey. They're already out there. Even if I take down all 60-ish of my fics that were hit in this scrape, that data is still out there, but if I delete them, it's ONLY out there as a stupid AI-training dataset, and I've cut out my readers entirely. Deleting the ones that were already scraped doesn't un-scrape them, and to me, it feels like letting the scrapers win if they get my writing AND I don't get to share my writing anymore.
For new writing going forward, that's definitely a place to make a personal decision! I've said a couple times I'm going to keep writing and sharing anyway because I love it, but that's not The One Right Way to do things.
I also am in the same boat as I've seen some people in my notes. A lot of my scraped fics were uh. Not my best work. Like I was prolific in 2018 and man... those fics were not super well-written. Text-based GenAI is trained to learn the order words should appear, based on probabilities. So if there's a lot of bad, boring works in there (and there definitely are! we all start out by posting mediocre writing!), that teaches the AI model to write bad, boring sentences. Most of us aren't tagging our fics in a way to tell a computer which fics are like this, so the AI doesn't know which fics are written by beginners who still don't know how to write well or who don't know English very well yet, and at least from what I know, the AI is going to treat those works like they're just as valid as the 100k+ novels we all know and love. All that comes together to make a shitty AI model that no one really wants to use, even if they're otherwise super pro-AI.
I'll round this off with a silly little book recommendation, but this book seriously changed the way I think about life in general and definitely impacted how I was able to take the scraping well enough and focus on being productive about it instead of just upset. The big takeaway from it is that no one can fully control their circumstances, but everyone has the ability to control the way they react to those circumstances. No one can control AI scrapers being scumbags, but we all get to choose how to respond to it happening.
28 notes
·
View notes
Text
Currently downloading the Hetalia fics from AO3 as it existed in 2017 (from the Internet Archive). Fun to think what could be on there that's no longer on AO3 now.
Finished downloading the FF.NET files from 2015. This is why I'd love to see what deleted stories people are looking for. It would be an easier way for me to see what's actually been deleted off the internet that's in these datasets.
Livejournal is a harder one to trawl through—it would need someone to have actually saved things manually before it got deleted. Same with fics on Wattpad and DeviantArt and other sites.
Once again, please hit me up if you have any deleted fics (interested mostly in America-centric works) OR if there's a deleted fic you're looking for.
This would mostly be about work that's actually available in either a these datasets, the wayback machine, etc.
#hetalia#hetalia world series#hws america#aph america#usuk#ukus#rusame#amerus#im wondering if i should make a blog for this or just keep it on this blog#is anyone interested in a project like this#.txt
27 notes
·
View notes